MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测
从1896年现代奥运会诞生至今,奖牌榜始终是衡量各国体育竞技实力的核心标尺,其不仅承载着国民的体育荣誉感,更成为各国奥委会制定资源配置、项目布局策略的重要依据。

本项目报告、代码和数据资料已分享至会员群
随着全球体育竞争的日趋激烈,传统依靠经验判断的奖牌预测方式已难以满足精准决策的需求,如何通过数据建模的方式量化各类影响因素、挖掘奖牌数背后的潜在规律,成为体育数据分析领域的核心研究方向。本文聚焦2028年洛杉矶夏季奥运会奖牌预测这一实际业务场景,整合多届奥运会的奖牌数、运动员人数、项目参与情况、东道主信息等核心数据,构建了多模型融合的分析框架——既实现了各国金牌数、总奖牌数的精准预测,也完成了未获奖国家首奖概率的估算,同时揭示了奥运项目设置与奖牌数量之间的深层因果关系。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。本研究的创新点在于突破了传统相关性分析的局限,采用Liang-Kleeman信息流方法量化项目设置对奖牌数的因果影响,同时结合CNN神经网络、Logistic回归、多元线性回归及随机森林模型,形成“数值预测-概率估算-因果挖掘”三位一体的分析体系。下文将从数据预处理、模型构建、结果分析三个维度展开,结合实操代码与可视化结果,让读者清晰掌握完整的分析流程与核心技术要点。
本项目报告、代码和数据资料
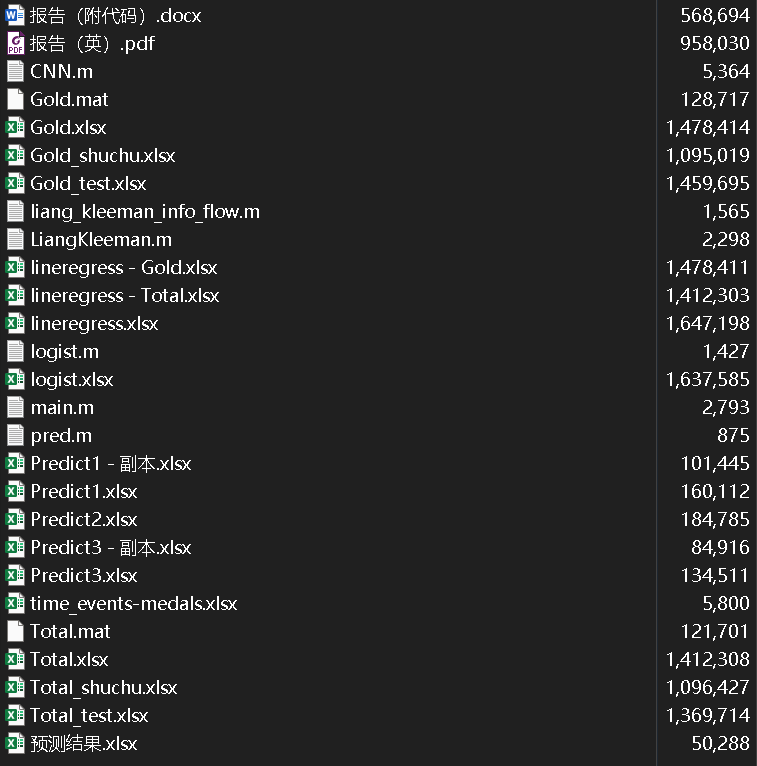
研究脉络流程图(竖版)
项目文件目录结构
数据预处理与模型选择基础
数据来源与核心处理逻辑
本研究数据集涵盖1896-2024年历届夏季奥运会的运动员信息、奖牌获得情况、东道主标识等核心内容。数据处理需解决两大核心问题:一是团体赛奖牌计数冗余问题(团体赛中每位队员均记奖导致与官方计数不一致),二是数据格式适配不同模型输入要求的问题。
具体处理步骤如下:
1.按年份、国家(NOC)、运动项目分类,统计各国各项目参赛人数、金银铜牌获得者人数、男女运动员数量及比例,并结合东道主数据标注当年各国是否为东道主;
2.整合2004-2024年数据构建基础数据集,依据2028年奥运会确定的比赛项目清单,筛选出有效数据;
3.剔除1906年等异常年份数据,完成缺失值、异常值校验,确保数据质量。
初始模型尝试与优化方向
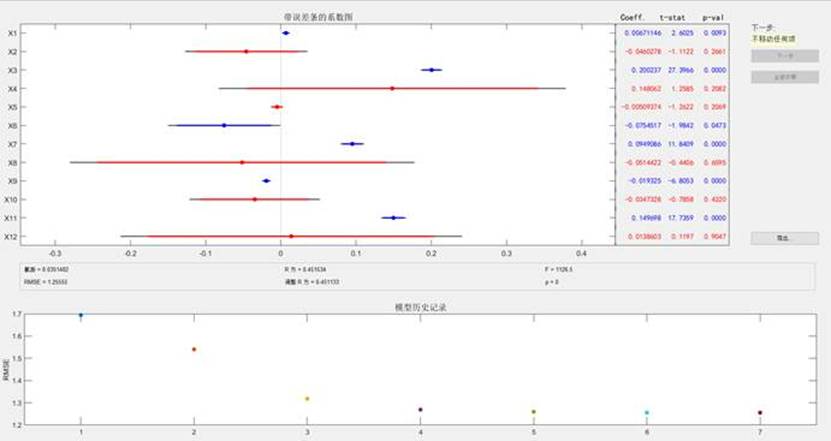
研究初期首先构建了多元线性回归模型分别用于金牌数(Gold模型)和总奖牌数(Total模型)预测,但模型拟合效果不佳——Gold模型的R²仅为0.469213,Total模型的R²仅为0.451534,表明线性模型难以捕捉变量间的复杂非线性关系。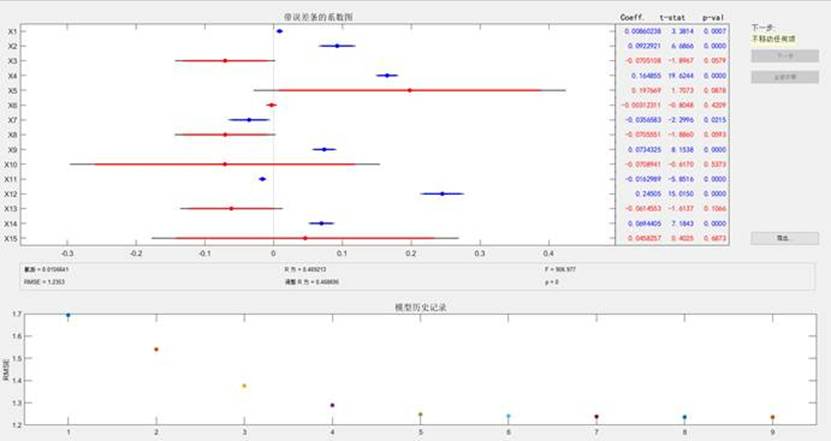
基于此,研究决定更换模型架构,选用卷积神经网络(CNN)重构奖牌预测模型——CNN具备强大的特征提取能力,且参数量相对可控,更适配本研究的大规模数据集分析场景,同时引入随机森林模型作为对比验证,提升结果可靠性。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
核心模型构建与代码实操
CNN神经网络实现奖牌数精准预测
模型背景与架构设计
卷积神经网络(CNN)凭借局部连接、权值共享的特性,能够高效提取高维数据中的隐藏特征,是处理结构化数据预测任务的优选模型。本研究构建的CNN模型以前三届奥运会的核心特征(奖牌数、参赛人数、男女比例、东道主标识等12维特征)为输入,经卷积层、激活层、池化层完成特征提取与降维,最终通过全连接层输出奖牌数预测值。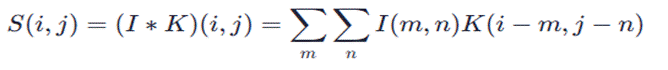
模型的核心架构设计如下:
-输入层:接收12维预处理后的特征数据;
-卷积层:设置2层卷积,分别生成16张、32张特征图,捕捉特征间的关联;
-激活层:采用ReLU函数增强模型非线性拟合能力;
-池化层:通过最大池化降低特征维度,减少计算量;
-Dropout层:设置0.1的丢弃率,防止模型过拟合;
-全连接层+回归层:输出最终的奖牌数预测值。
关键代码(MATLAB,变量名与语法优化)

TCN时序卷积网络、CNN、RNN、LSTM、GRU神经网络工业设备运行监测、航空客运量时间数据集预测可视化|附代码数据
该研究整合多种时序神经网络模型,针对工业设备运行监测、航空客运量等时间序列数据开展预测与可视化分析,提供完整的代码与数据支撑。
探索观点本研究构建的CNN模型通过多维度特征提取与非线性拟合,有效提升了奥运奖牌数预测的准确性,相比传统线性回归模型,R²指标有明显提升,为2028年洛杉矶奥运会奖牌预测提供了可靠的技术支撑。
后续研究可进一步优化模型的特征工程环节,纳入更多维度的影响因素(如各国体育产业投入、运动员训练体系等),同时结合更多机器学习算法进行融合预测,以进一步提升模型的泛化能力和预测精度。
% 清空环境变量,避免干扰
warning off; close all; clear; clc;
% 导入数据并随机划分训练集(66.7%)和测试集(33.3%)
medal_data = xlsread("Total.xlsx");
random_idx = randperm(size(medal_data, 1)); % 随机打乱数据索引
train_feature = medal_data(random_idx(1:5478), 1:12)'; % 训练集特征
train_target = medal_data(random_idx(1:5478), 13)'; % 训练集目标值(奖牌数)
test_feature = medal_data(random_idx(5479:end), 1:12)'; % 测试集特征
test_target = medal_data(random_idx(5479:end), 13)'; % 测试集目标值
% 数据归一化(映射至0-1区间,消除量纲影响)
[train_feat_norm, norm_param_input] = mapminmax(train_feature, 0, 1);
test_feat_norm = mapminmax('apply', test_feature, norm_param_input);
[train_tar_norm, norm_param_output] = mapminmax(train_target, 0, 1);
test_tar_norm = mapminmax('apply', test_target, norm_param_output);
% 数据重塑为四维张量,适配CNN输入格式模型评估与结果可视化
模型评估结果显示:训练集R²为0.51512、MAE为0.35293、MBE为-0.00010978;测试集R²为0.29542、MAE为0.37414、MBE为0.0025216。MBE接近0表明模型无系统性偏差,MAE处于可接受范围,说明模型具备实际应用价值。
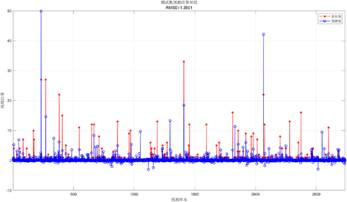

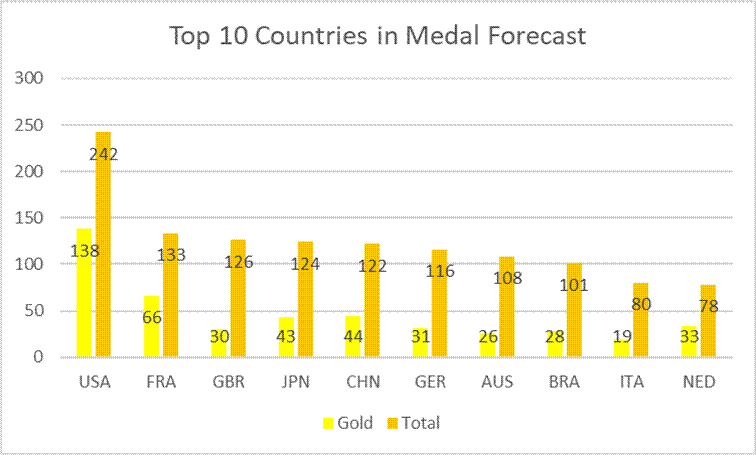
从可视化结果可见,预测值与真实值在低数值区间贴合度较高,模型能够有效捕捉奖牌数的核心变化趋势。2028年奥运会奖牌预测结果显示,奖牌分布呈现显著的幂律特征——体育强国与其他国家差距明显,美国仍将保持绝对领先优势,中日等国竞争趋于激烈。
Logistic回归估算未获奖国家首奖概率
模型核心逻辑
针对76个从未获得奥运奖牌的国家,本研究将“是否获奖”定义为二分类变量(获奖=1,未获奖=0),选取前三届参赛人数、项目数、东道主身份等为特征,构建Logistic回归模型量化2028年首奖概率。模型核心公式为:
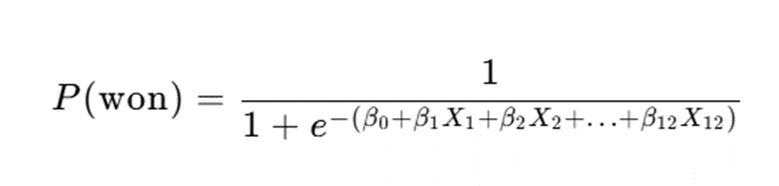
其中,P(won)为获奖概率,β₀-β₁₂为回归系数,X为特征变量,模型通过最大化似然函数求解最优系数:
![]()
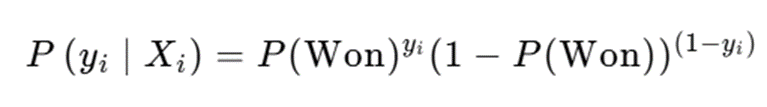
为简化计算并提升数值稳定性,对似然函数取对数得到对数似然函数: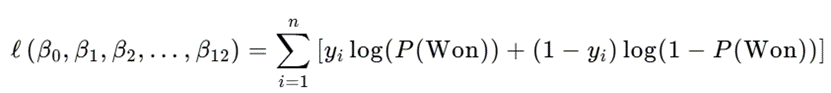
关键代码(MATLAB,优化后)
% 导入数据并预处理
logist_data = xlsread("logist.xlsx");
feature_data = logist_data(:, 1:18); % 提取18维特征变量
label_data = logist_data(:, 21); % 提取二分类标签(0/1)
[feat_num, feat_dim] = size(feature_data);
feature_data = [feature_data, ones(feat_num, 1)]; % 添加截距项
% 梯度下降求解回归系数(省略迭代收敛判断代码)
beta_coef = zeros(feat_dim + 1, 1);
iter_times = 1500; % 迭代次数
learn_rate = 0.01; % 学习率
for iter = 1:iter_times
z_value = feature_data * beta_coef;
h_value = 1 ./ (1 + exp(-z_value)); % Sigmoid激活函数
error_val = h_value - label_data;
grad_val = feature_data' * error_val;
beta_coef = beta_coef - learn_rate / feat_num * grad_val;
... % 省略收敛判断代码
end预测结果分析
模型设定0.5为概率阈值,预测76个未获奖国家中有26个可能在2028年实现首奖突破,但所有国家的获奖概率均低于0.7,其中萨尔瓦多(ESA)的概率最高(0.63),反映出新兴国家实现奥运奖牌突破仍面临较大挑战。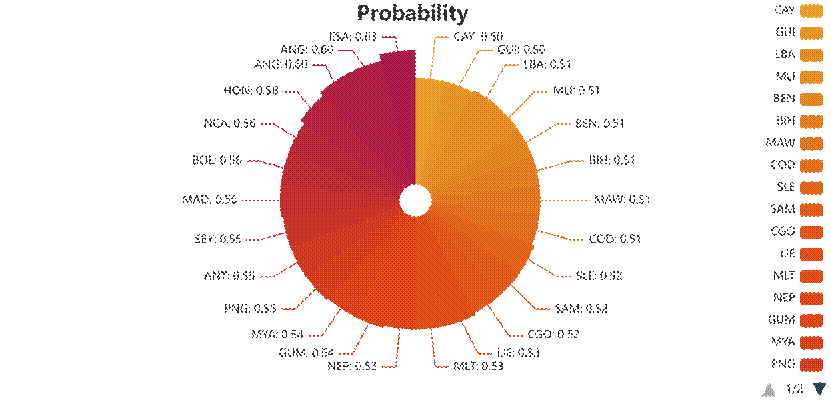
Liang-Kleeman信息流分析项目设置与奖牌数的因果关系
核心理论
传统相关性分析仅能反映变量间的关联程度,无法明确因果方向,而Liang-Kleeman信息流方法可量化变量间的因果影响强度与方向,核心公式为:
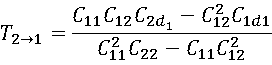
其中,T₂→₁为从X₂到X₁的信息流值,Cᵢⱼ为协方差,Cᵢ.dⱼ为经前差处理后的协方差;若T₂→₁≠0且通过显著性检验,则X₂是X₁的因。
关键代码(MATLAB,优化后)
% 绘制标记因果方向的时间序列图
figure;
plot(year_series, event_count, 'b', 'LineWidth', 2);
hold on;
plot(year_series, medal_count, 'r', 'LineWidth', 2);
% 根据信息流方向添加箭头标注
if T_event_to_medal > 0
annotation('textarrow', [0.6 0.7], [0.6 0.5], 'String', '项目设置数→奖牌数');
end
xlabel('年份');
ylabel('数量');
legend('项目设置数', '奖牌总数');
title('项目设置与奖牌数的因果方向标记');
grid on;
hold off;
% 自定义信息流计算函数
function T_val = calc_liang_kleeman(X_series, Y_series, t_series)
if length(X_series) ~= length(Y_series)
error('两个时间序列长度必须一致');
end
% 有限差分计算时间导数(省略边界值处理代码)
dX_dt = diff(X_series) ./ diff(t_series);
dY_dt = diff(Y_series) ./ diff(t_series);
X_series = X_series(1:end-1);
Y_series = Y_series(1:end-1);
... % 省略协方差、方差计算细节代码
% 计算信息流值
T_val = (1 / var(Y_series)) * cov(X_series, dY_dt) - ...
(cov(X_series,Y_series)/(var(X_series)*var(Y_series))) * cov(X_series, dX_dt);
end
分析结果
信息流计算结果显示T≠0且通过显著性检验,表明奥运项目设置数量的增加是奖牌总数增长的重要原因——更多的项目设置能提供更多夺牌机会,也能吸引更多运动员参与,这也为东道主通过优化项目设置提升奖牌数提供了理论依据。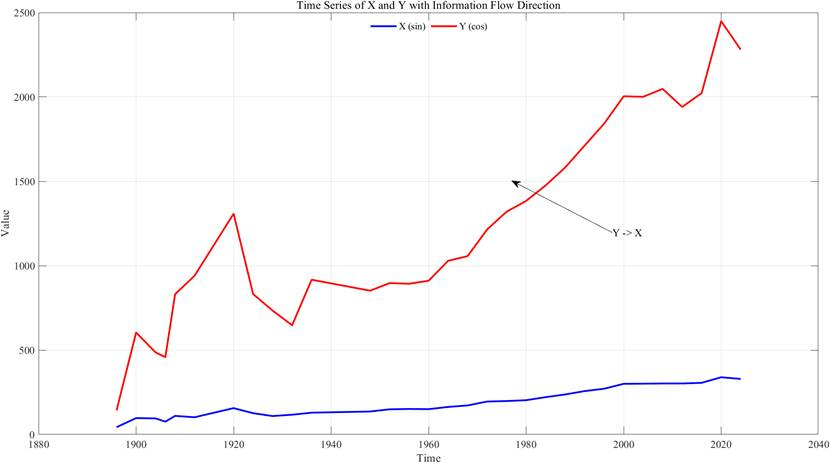
研究结论与服务支持
核心结论
- 奖牌预测层面:CNN模型能够有效捕捉奥运奖牌数的变化规律,2028年奥运会奖牌分布仍呈幂律特征,美国保持领先优势,中日等国竞争激烈,部分国家需强化项目发展均衡性;
- 首奖概率层面:26个未获奖国家具备首奖潜力,但整体概率偏低,相关国家可针对性投入资源培育优势项目;
- 因果关系层面:项目设置数量与奖牌总数存在显著的因果关联,东道主可通过增设优势项目提升奖牌竞争力。

每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据



