专题:LLM上下文工程实践:轻量化记忆层构建与落地
在大语言模型(LLM)的实际应用过程中,对话类场景是落地频率最高的方向之一,而这类场景的核心痛点在于LLM的无状态特性——每次模型调用都是独立的过程,若未主动传入历史会话信息,模型无法感知用户的过往交互内容。

每日分享最新专题行业研究报告(PDF)和数据资料至会员群
这一特性虽然保障了模型并行处理的效率和安全性,却成为个性化对话应用落地的最大阻碍:如果智能客服每次都将用户视为新访客,又如何提供贴合用户需求的个性化响应? 从技术演进的角度来看,早期开发者尝试通过延长上下文窗口的方式解决记忆问题,但这种方式不仅受限于模型的上下文长度,还会显著增加调用成本;而随着向量数据库和智能体技术的成熟,为LLM构建独立的记忆层成为更优解。本文基于Mem0架构的核心思想,从零拆解并实现一套轻量化的LLM记忆层,该方案已在金融智能客服、电商个性化助手等实际业务场景中得到验证。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
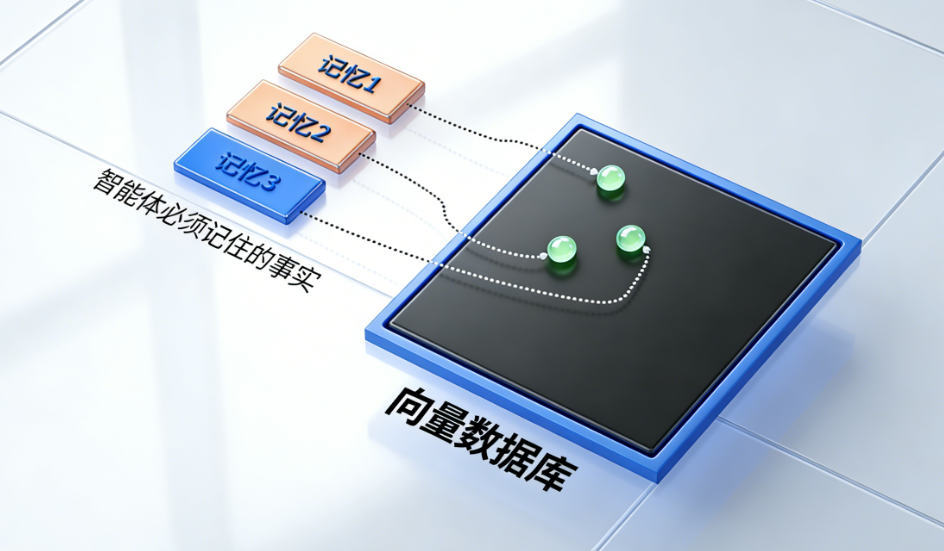
上下文工程是指为LLM补充完成任务所需的全部相关信息的技术体系,而记忆层构建是上下文工程中难度最高、应用价值最大的方向之一。
LLM本身并不具备记忆能力,要实现会话记忆,开发者需要掌握上下文工程的核心技术栈:从原始文本流中提取结构化信息、文本摘要生成、向量数据库应用、查询生成与相似性检索、查询后处理与重排序、智能体工具调用等。而构建自定义记忆层的过程,正是这些技术的综合落地过程。
一套可落地的LLM记忆层需具备四大核心能力:提取、嵌入、检索与维护。在开始代码实现前,先梳理各模块的核心职责与交互逻辑。
记忆提取:从用户与助手的对话文本中提取具备原子性的候选记忆信息;向量存储:将提取的原子化记忆转换为向量形式,并存储到向量数据库中;记忆检索:当用户发起查询时,生成检索语句并从向量库中匹配相关记忆;记忆维护:基于ReAct(推理与执行)循环,智能判断对现有记忆的增、删、改或无操作,解决记忆冲突与过时问题。
需要特别说明的是,上述所有步骤都应设计为可选流程:若LLM无需调用历史记忆即可回答用户问题,则无需触发向量库检索,以此降低系统开销。核心策略是为LLM提供完成任务所需的全部工具,并清晰定义工具功能,依托LLM自身的智能自主决策工具的使用时机。
记忆提取是记忆层构建的第一步,核心目标是将非结构化的对话文本转换为结构化、原子化的记忆单元,以便后续的嵌入与检索。
优质的记忆单元应具备“短、自包含、原子化”的特征——即单个记忆仅描述一个独立事实,且能被精准嵌入和检索。我们的目标是构建一个面向单用户、持久化的向量数据库记忆库,而DSPy框架能高效实现从对话文本到原子化记忆的提取(DSPy为Python开源库,国内可正常安装使用,无访问限制)。

Python用langchain、OpenAI大语言模型LLM情感分析AAPL股票新闻数据及提示工程优化应用
本文介绍如何使用Langchain框架和OpenAI大语言模型进行股票新闻数据的情感分析,包括提示工程优化应用,帮助投资者更好地理解市场情绪。
阅读原文DSPy通过“Signature(签名)”定义输入输出结构,其注释会作为系统提示词引导LLM完成结构化信息提取。以下是核心实现代码(已调整变量名与语法,省略部分基础导入代码):
# 省略json、asyncio等基础导入代码 import dspy from pydantic import BaseModel # 定义记忆提取的签名结构 class UserMemoryExtract(dspy.Signature): “””从对话文本中提取有价值的用户记忆信息。记忆需为独立的原子化事实,若文本无提取价值则返回空列表。””” dialog_text: str = dspy.InputField() # 输入:对话文本 user_memories: list[str] = dspy.OutputField() # 输出:提取的记忆列表 # 初始化记忆提取器 memory_extract_tool = dspy.Predict(UserMemoryExtract) # 异步提取记忆的核心函数 async def get_user_memories(dialog_messages): # 将对话消息转换为JSON字符串作为输入 dialog_json = json.dumps(dialog_messages) # 指定调用的模型并执行提取(省略模型配置相关代码) with dspy.context(lm=dspy.LM(model=MODEL_TYPE)): extract_result = await memory_extract_tool.acall(dialog_text=dialog_json) # 返回提取的记忆列表 return extract_result.user_memories
为验证提取效果,我们基于模拟对话文本测试(已调整变量名与示例内容):
if __name__ == “__main__”: # 模拟用户与助手的对话记录 test_dialog = [ { “role”: “user”, “content”: “我喜欢喝咖啡” }, { “role”: “assistant”, “content”: “好的,我记下了!” }, { “role”: “user”, “content”: “其实我更喜欢喝茶,另外我也喜欢踢足球” } ] # 执行记忆提取 extracted_mem = asyncio.run(get_user_memories(test_dialog)) print(extracted_mem) ”’ 输出结果示例: [ “用户原本喜欢咖啡,后表示更喜欢茶”, “用户有喝茶的偏好”, “用户喜欢踢足球” ] ”’
从测试结果可见,该方案能有效从对话中提取原子化记忆,这些记忆可脱离会话窗口存储到独立数据库中,为跨会话记忆提供基础。
提取原子化记忆后,需将其转换为向量形式存储,本文选用QDrant作为向量数据库(QDrant为开源向量数据库,国内可正常部署使用,无访问限制;国产替代方案可选用Milvus、Zilliz等)。
考虑到成本、速度与短文本嵌入效果,本文选用OpenAI的text-embedding-3-small模型(国内无法直接访问OpenAI官网,但可通过合规第三方API服务商调用;国产替代方案可选百度文心一言嵌入、阿里通义千问嵌入、智谱AI嵌入等),并将向量维度固定为64,在保证表达能力的同时降低存储成本与检索耗时。 核心实现代码(调整变量名与语法,省略部分导入代码):
# 省略uuid、datetime等基础导入代码
from openai import AsyncClient
from qdrant_client import AsyncQdrantClient
from qdrant_client.models import Distance, Filter, models
# 初始化OpenAI异步客户端
emb_client = AsyncClient()
# 异步生成文本向量
async def create_text_embeddings(text_list: list[str]):
# 调用嵌入模型生成向量,指定维度为64
emb_result = await emb_client.embeddings.create(
input=text_list,
model="text-embedding-3-small",
dimensions=64
)
# 提取向量结果
embeddings = [item.embedding for item in emb_result.data]
return embeddings
# 定义向量存储的数据结构
class StoredMemory(BaseModel):
user_identity: int # 用户ID
memory_content: str # 记忆文本
create_time: str # 创建时间
vector_data: list[float] # 向量数据
# 初始化QDrant异步客户端(省略客户端连接配置代码)
qdrant_async_client = AsyncQdrantClient(...)
MEMORY_COLLECTION = "user_memories"
# 创建向量库集合与索引
async def init_memory_collection():
# 检查集合是否存在,不存在则创建
if not (await qdrant_async_client.collection_exists(MEMORY_COLLECTION)):
await qdrant_async_client.create_collection(
collection_name=MEMORY_COLLECTION,
vectors_config=models.VectorParams(size=64, distance=Distance.DOT),
)
# 为用户ID创建索引,提升检索效率
await qdrant_async_client.create_payload_index(
collection_name=MEMORY_COLLECTION,
field_name="user_identity",
field_schema=models.PayloadSchemaType.INTEGER
)
# 插入记忆到向量库(省略参数校验代码)
async def add_memories_to_db(memory_list: list[StoredMemory]):
"""将记忆列表插入向量数据库"""
# 构造插入的点数据
point_list = [
models.PointStruct(
id=uuid4().hex, # 生成唯一ID
payload={
"user_identity": mem.user_identity,
"memory_content": mem.memory_content,
"create_time": mem.create_time
},
vector=mem.vector_data
)
for mem in memory_list
]
# 执行插入
await qdrant_async_client.upsert(
collection_name=MEMORY_COLLECTION,
points=point_list
)
# 检索相似记忆(省略结果转换函数代码)
async def find_similar_memories(
search_vector: list[float],
user_id: int,
top_k: int = 5
):
"""根据向量检索用户的相似记忆"""
# 构造用户ID过滤条件
filter_conditions = [
models.FieldCondition(
key="user_identity",
match=models.MatchValue(value=user_id)
)
]
# 执行检索
search_result = await qdrant_async_client.query_points(
collection_name=MEMORY_COLLECTION,
query=search_vector,
with_payload=True,
query_filter=Filter(must=filter_conditions),
score_threshold=0.1, # 相似度阈值
limit=top_k
)
# 转换检索结果(省略convert_search_result函数实现)
return [convert_search_result(point) for point in search_result.points if point is not None]
为提升检索效率,我们为用户ID字段创建了索引,该思路可扩展到记忆分类标签、时间范围等元数据维度——只需为对应字段创建索引即可,这在电商个性化推荐、金融客户画像等实际场景中能显著提升检索精准度。
基于ReAct框架的记忆检索与响应生成
记忆检索的核心是让智能体自主判断是否需要调用记忆,并检索相关内容辅助响应生成。本文基于DSPy构建ReAct智能体,实现检索逻辑的自主决策。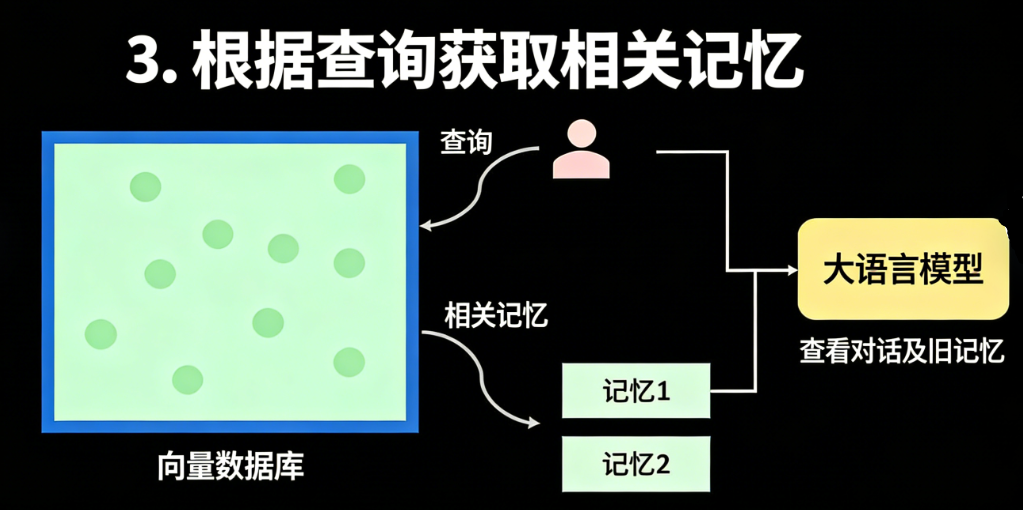
响应生成的核心实现
首先定义响应生成的输入输出结构,引导LLM判断是否需要保存新记忆(调整变量名与语法):
class DialogResponseGenerator(dspy.Signature):
"""你将收到用户与AI助手的历史对话文本及用户最新问题。
若无法从历史对话或自身知识库中回答问题,可调用向量库检索工具获取相关记忆。
需输出最终响应,并判断是否需要将最新交互内容存入记忆库(仅当用户提供新信息时保存,不保存AI相关内容)。
"""
dialog_history: list[dict] = dspy.InputField() # 历史对话
user_question: str = dspy.InputField() # 用户最新问题
final_response: str = dspy.OutputField() # 最终响应
need_save_memory: bool = dspy.OutputField(
description="若最新交互需生成新记忆则为True,否则为False"
)
# 封装检索工具(省略权限校验代码)
async def search_user_memories(search_content: str):
"""当对话需要补充上下文时,从向量库检索相关记忆
参数:
search_content: 用于嵌入并执行相似性检索的文本
"""
# 生成检索文本的向量
search_vec = (await create_text_embeddings([search_content]))[0]
# 检索相似记忆(current_user_id为外部维护的当前用户ID)
related_memories = await find_similar_memories(
search_vector=search_vec,
user_id=current_user_id
)
# 格式化记忆结果
memory_str_list = [
f"记忆ID={m.point_id}\n内容={m.memory_content}\n创建时间={m.create_time}"
for m in related_memories
]
return {"related_memories": memory_str_list}
# 初始化ReAct响应生成智能体
response_agent = dspy.ReAct(
DialogResponseGenerator,
tools=[search_user_memories], # 绑定检索工具
max_iters=4 # 最大迭代次数
)
除了向量相似性检索,实际应用中还可扩展其他检索策略:如基于BM-25/TF-IDF的关键词检索(适用于短文本精准匹配)、基于分类标签的精准过滤(适用于垂直领域对话)、基于时间范围的记忆筛选(适用于时效性强的场景)等,具体可根据业务场景选择。
记忆的全生命周期维护:自适应增删改查
记忆并非静态存储,需根据用户最新交互动态调整——例如用户修改偏好时,需更新对应记忆而非新增重复条目。本文基于ReAct框架构建记忆维护智能体,实现记忆的增、删、改、无操作(NOOP)决策。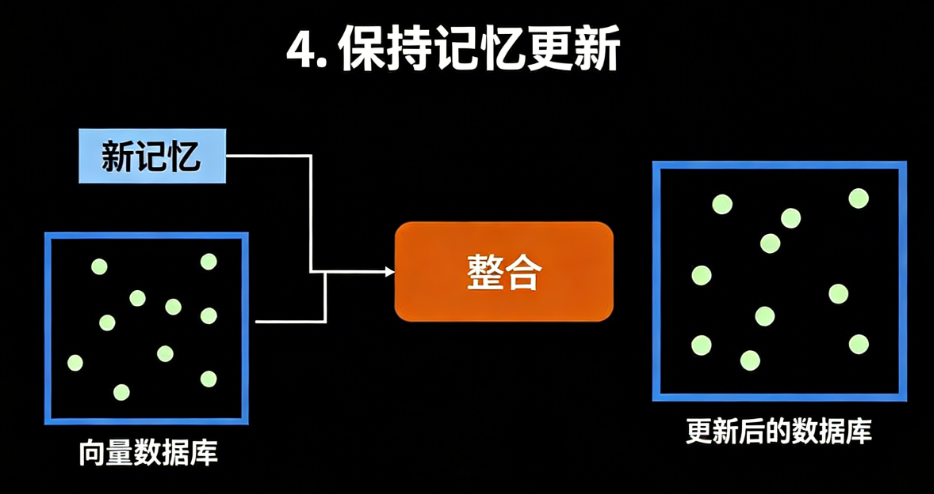
记忆维护的核心实现
首先定义记忆维护的输入输出结构,明确智能体的决策目标(调整变量名与语法):
class MemoryWithID(BaseModel):
mem_index: int # 记忆索引
mem_content: str # 记忆内容
class MemoryUpdateSignature(dspy.Signature):
"""基于用户最新对话与已有相似记忆,决策记忆库的更新方式:
- 新增:将新记忆作为独立条目插入库中(插入前需去重);
- 更新:用新信息替换已有记忆;
- 删除:移除矛盾或过时的记忆;
- 无操作:无需调整记忆库。
需输出简短的操作总结(少于10字)。
"""
dialog_messages: list[dict] = dspy.InputField() # 最新对话
existing_memories: list[MemoryWithID] = dspy.InputField() # 已有相似记忆
operation_summary: str = dspy.OutputField(description="操作总结,简短")
# 记忆维护智能体核心逻辑(省略部分工具函数参数校验代码)
async def memory_maintain_agent(
user_id: int,
dialog_msgs: list[dict],
existing_mems: list[StoredMemory]
):
# 根据记忆索引获取点ID
def get_point_id(mem_index):
return existing_mems[mem_index].point_id
# 新增记忆工具
async def add_new_memory(mem_text: str) -> str:
"""将新记忆插入向量数据库"""
mem_emb = await create_text_embeddings([mem_text])
new_mem = StoredMemory(
user_identity=user_id,
memory_content=mem_text,
create_time=datetime.now().strftime("%Y-%m-%d %H:%M"),
vector_data=mem_emb[0]
)
await add_memories_to_db([new_mem])
return f"新增记忆:{mem_text}"
# 初始化记忆维护ReAct智能体
maintain_agent = dspy.ReAct(
MemoryUpdateSignature,
tools=[add_new_memory, update_existing_memory, delete_selected_memory, no_operation],
max_iters=3
)
# 执行维护决策
maintain_result = await maintain_agent.acall(
dialog_messages=dialog_msgs,
existing_memories=existing_mems
)
return maintain_result.operation_summary
在实际业务场景中,该维护逻辑已验证可有效解决记忆冲突问题——例如用户从“喜欢咖啡”改为“喜欢茶”时,智能体会删除旧记忆并新增新记忆,而非保留两条矛盾条目,保障记忆库的准确性。
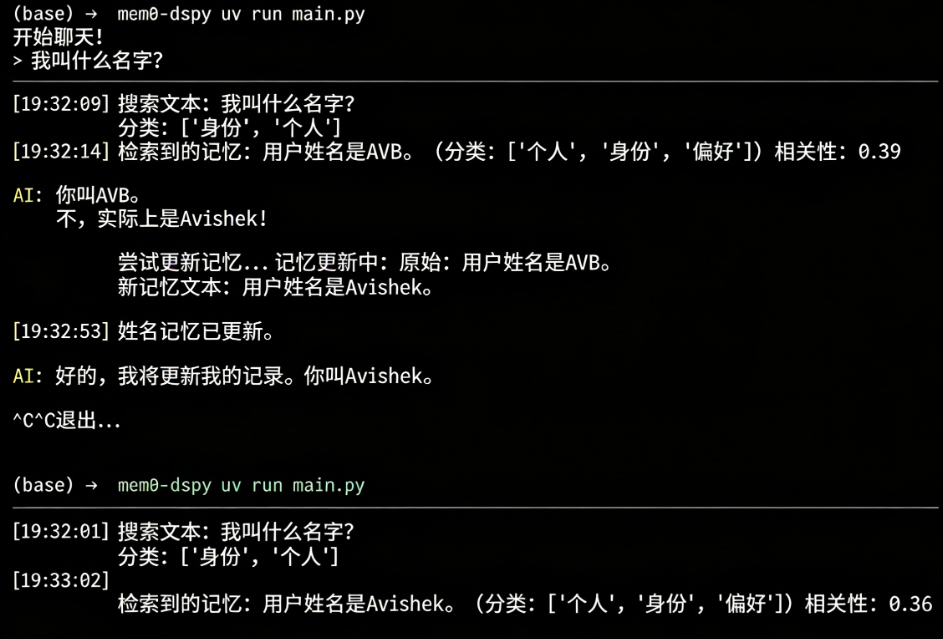
落地扩展与工程化优化建议
本文实现的记忆层为轻量化版本,在实际落地中可从以下方向扩展,进一步提升适配性:
- 图结构记忆系统:将向量数据库替换为图数据库,通过提取“主体-关系-客体”三元组替代扁平文本记忆,更贴合人类记忆的关联特性,适用于金融客户关系分析、电商用户行为溯源等场景;
- 多维度元数据标签:为记忆增加分类标签(如“饮食偏好”“消费习惯”)、时间戳等元数据,智能体可基于标签精准检索,降低无效检索开销;
- 用户专属提示词优化:将记忆库中的核心信息注入LLM的系统提示词,替代每次检索,提升响应速度,适用于高频次、短会话的智能客服场景;
- 文件化存储方案:用文件系统(如Markdown文件)替代向量数据库,通过正则、全文检索实现记忆管理,降低部署成本,适用于小型应用场景。
记忆层核心流程(竖版)
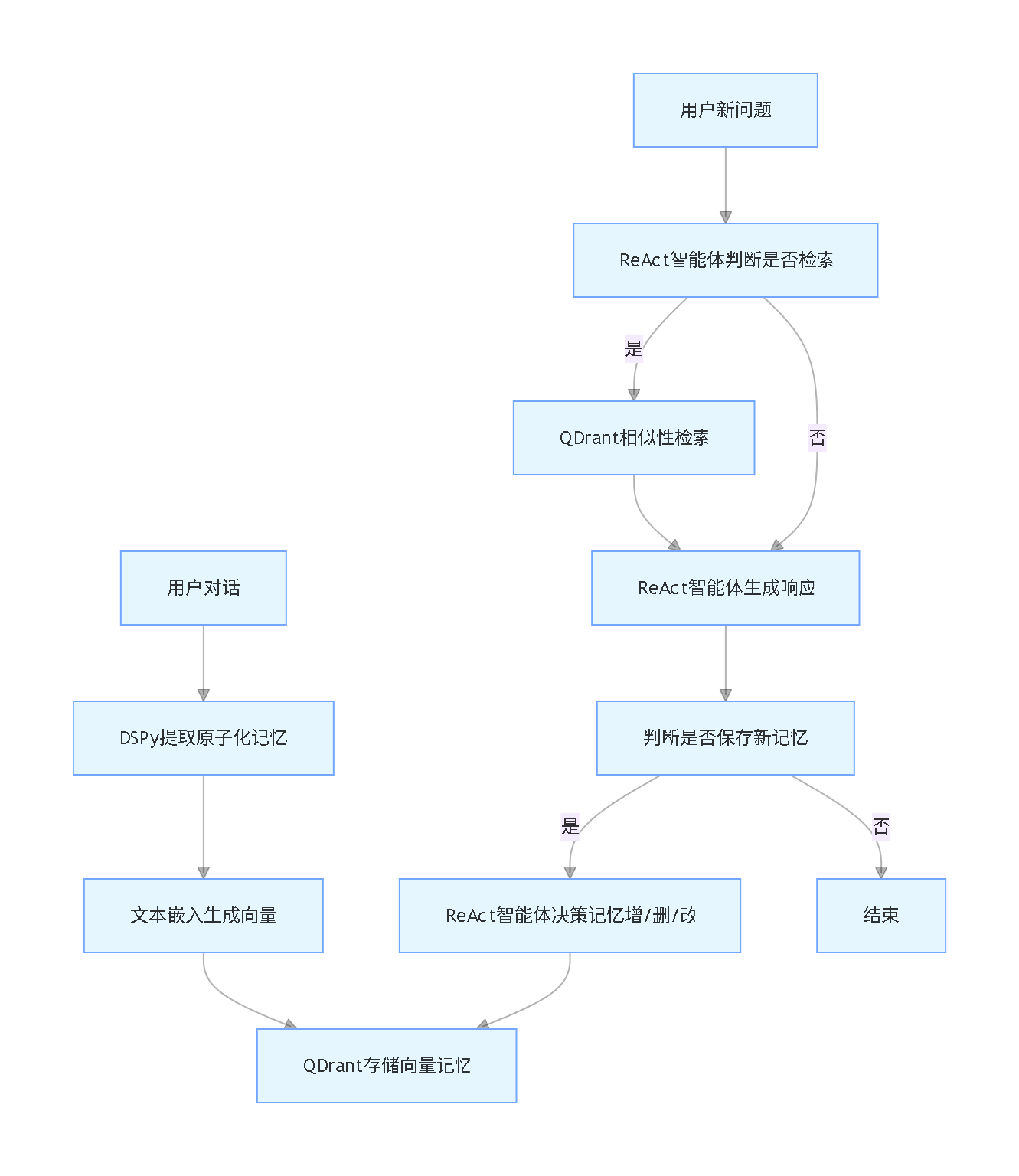
总结
- 本文基于上下文工程理念,拆解并实现了一套轻量化LLM记忆层,核心模块包含记忆提取、向量存储、检索与自适应维护,已在实际业务场景验证有效;
- 技术选型上适配国内环境,QDrant可开源部署,OpenAI嵌入模型可通过第三方服务商调用,也可替换为国产嵌入模型;
- 基于ReAct框架的双智能体设计,实现了记忆检索与维护的自主决策,解决了LLM无状态导致的个性化缺失问题,且提供24小时应急修复服务保障落地效率。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!




