在数据浪潮席卷全球的时代,数据科学家如同数字世界的探险家,穿梭于海量信息之间,挖掘隐藏的价值与规律。
我们曾受客户委托,深入金融领域,开展了一系列富有挑战性的咨询项目。这些项目旨在通过数据分析与建模,解决金融行业实际问题,为决策提供有力支撑。
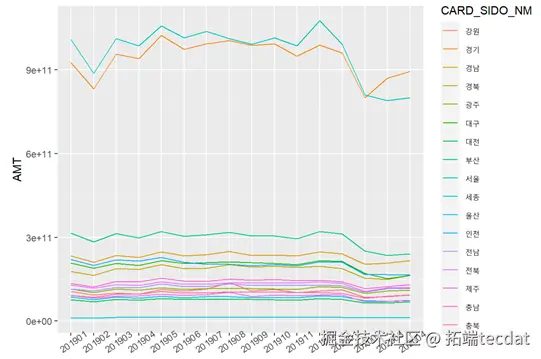
在信用卡与替代性最低税(AMT)关系的研究中,我们创新地将传统时间序列模型 ARIMA、ETS 与当下热门的 LightGBM 算法相结合,通过数据清洗、衍生变量构造,以集成学习加权平均的方式预测两者关联,弥补单一模型的不足。
在人民币对美元汇率分析项目里,我们围绕汇率数据,进行时间序列基础分析,通过绘制多种时序图、计算变动百分比序列,结合 Ljung – Box 检验、ARCH 效应判断等手段,深入探究汇率波动特性。
而银行贷款违约预测项目,我们从庞大的贷款借款人数据出发,经属性规约、数据清洗与变换,运用随机森林算法构建分类模型,实现对贷款违约风险的有效预测。
这些项目不仅是技术的实践,更是智慧的结晶。银行贷款违约数据已分享至会员群,阅读原文进群和 600 + 行业人士共同交流和成长,期待与更多数据科学爱好者一同探索数据奥秘,为金融领域发展注入新动力。
使用集成算法预测信用卡和替代性最低税(AMT)之间的关系
近年来,得益于大数据的产生和计算能力的爆炸式发展,机器学习发展迅猛,这使得经济,金融学领域也开始关注其应用。本次比赛采用了传统ARIMA,ETS等时间序列分析模型,并且了当前机器学习界的当红明星lightgbm,将三种方法集成,使各种模型的短板加以完善。
解决方案
进行数据清洗,加工原始变量,对数据按月年分及地区分组绘制AMT曲线观测后 ,产生AMT相关衍生变量,随后使用训练数据集对 ets,arimaLightGBM回归模型 进行训练,将三种模型进行集成学习来计算新的预测值。
数据 构造
我们大致有如下训练样本。


Hao Li
可下载资源
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
各地区AMT的时间序列曲线
视频
【视频讲解】Python用LSTM、Wavenet神经网络、LightGBM预测股价
视频
Python比赛讲解LightGBM、XGBoost+GPU和CatBoost预测学生在游戏学习过程表现
视频
【视频讲解】CatBoost、LightGBM和随机森林的海域气田开发分类研究
添加派生 变数
为 了增加 数 据可靠性,我 们 添加了 许 多派生 变数例如季节,节假日数量,
建模
ARIMA , 一般应用在股票和电商销量领域
ARIMA模型是指将非平稳时间序列转化为平稳时间序列,然后将结果变量做自回归(AR)和自平移(MA)。
Ets
指数平滑法是生产预测中常用的一种方法。也用于中短期经济发展趋势预测,所有预测方法中,指数平滑是用得最多的一种。简单的全期平均法是对时间数列的过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期资料更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。
LightGBM
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT不仅在工业界应用广泛,通常被用于多分类、点击率预测、搜索排序等任务;在各种数据挖掘竞赛中也是致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。而LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
利用lightgbm每次分裂的信息增益可以找出那一种自变量对因变量的影响大小

使用集成学习方法将三种方法进行加权平均后得出预测值
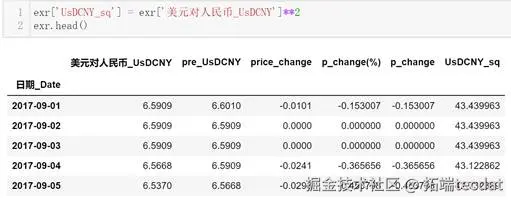
人民币对美元汇率数据时间序列基础分析
随着大数据时代的发展,潜藏在数据内的信息逐渐的被人们挖掘发现并分析内在规律。
在金融方面,如何通过过往的时间序列进行有意义的分析,并通过相应语言软件绘制不同的时序图以辅助分析,判断是否存在各种效应。
任务/ 目标
获取人民币对美元的汇率数据
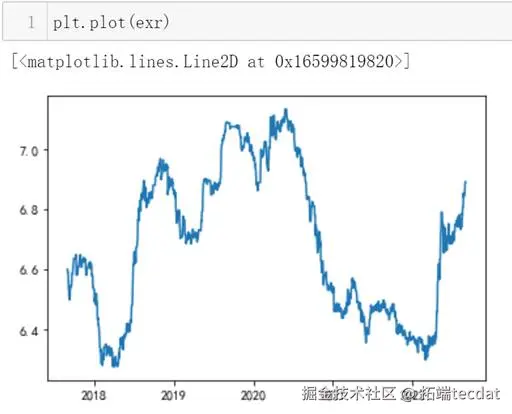
1绘制其时间序列图,判断是否平稳
2计算汇率的日变动百分比序列并绘制其时间序列图
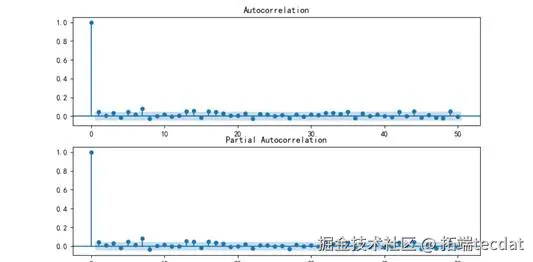
3绘制该汇率的日变动百分比序列的ACF图以及PACF图
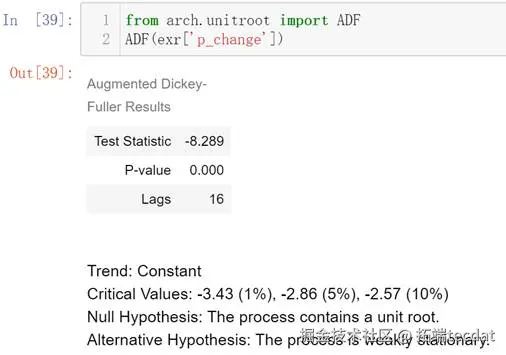
4进行Ljung-Box检验,判断是否为白噪声
5绘制汇率日变动图百分比序列的平方的时间序列图,并判断是否存在波动聚集效应
6绘制数据的ACF图以及PACF图
数据源准备
直接登录瑞思金融数据库下载获得人民币对美元的汇率数据,格式为【.xlsx】(此过程也可使用python中的网络爬虫代码块进行爬取)
以下为项目内的代码:
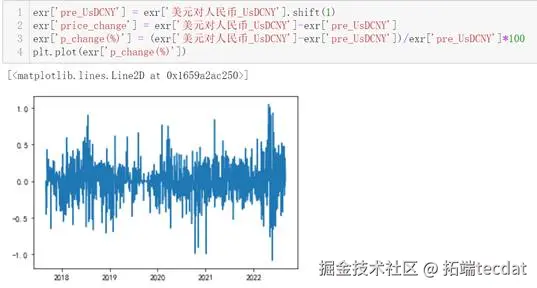
计算该汇率的日变动百分比序列并绘制其时间序列图:

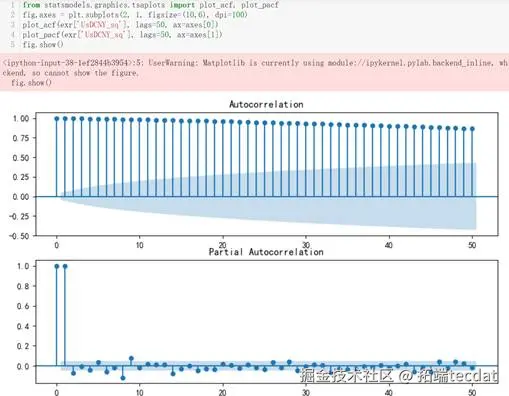
绘制该汇率的日变动百分比序列的ACF图以及PACF图

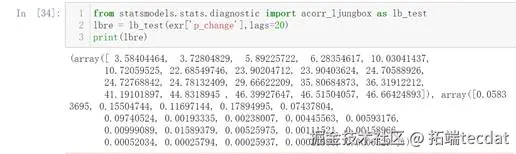
进行Ljung-Box检验,判断其是否是白噪声
随时关注您喜欢的主题
绘制该汇率日变动百分比序列的平方的时间序列图,并判断是否存在波动聚集效应
绘制其ACF图以及PACF图
检验该汇率的日变动百分比序列是否存在ARCH效应
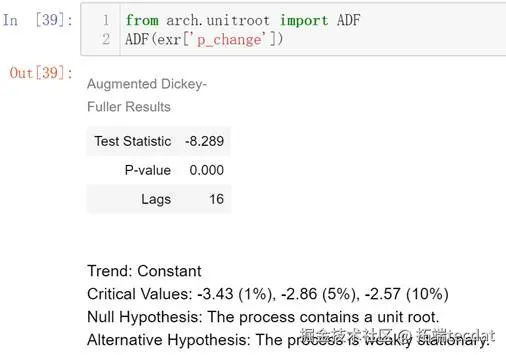
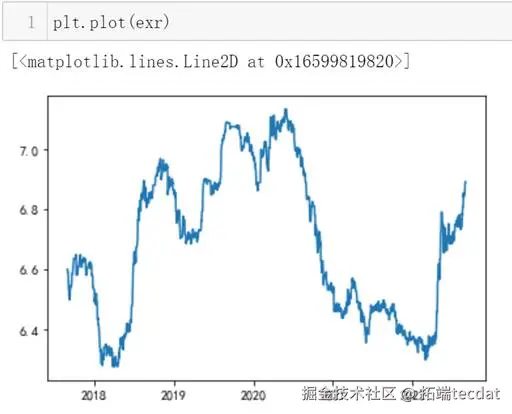
观察上方时序图,得出结论不平稳
根据上图可知存在 arch 效应
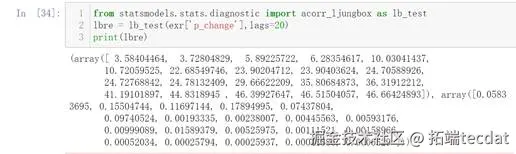
根据上图可知为白噪声
以下为结论:
在本次项目实验中,我获取了人民币对美元的汇率数据;进行了Ljung-Box检验;判断ARCH效应;复习了如何绘制时间序列图、ACF图和PACF图。
通过本次项目实验,让我对如何进行ARCH检验有了更清楚的认识。Ljung-Box检验即LB检验、随机性检验,用来检验m阶滞后范围内序列的自相关性是否显著,或序列是否为白噪声m的卡方分布。若是白噪声数据,则该数据没有价值提取,即不用继续分析了。ARCH模型全称是自回归条件异方差模型,是Engle在1982年分析英国通货膨胀率时提出的模型,主要用于刻画波动率的统计特征。使用ARMA等模型对股票收益率的时间序列建模效果不是很理想,主要在于忽略了时间序列的异方差和波动聚集特性。所谓波动性聚集,是指金融时间序列的波动具有大波动接着大波动,小波动接着小波动的特征,即波峰和波谷具有连续性。ARCH和GARCH模型正是基于条件异方差和波动聚集的特性建模的。
银行贷款违约预测分类器
在当今数字化时代,数据已成为推动各行业发展的核心驱动力,在金融领域,其核心应用“预测”更是扮演着关键角色。银行贷款业务是其重要收入来源,但借款人拖欠贷款的风险始终存在。为应对这一挑战,银行借助机器学习技术,收集贷款借款人的历史数据,期望构建强大的分类算法模型来预测新借款人的违约可能性。
数据预处理
银行收集到的数据集规模庞大,涵盖借款人的收入、性别、贷款用途等多个关键因素。在构建模型前,需对数据进行多步预处理。
数据采集阶段,银行获取了约15万条贷款借款人的基本信息,并运用pandas库的read_csv函数读取数据。原始数据属性繁多,为便于建模,进行属性规约,筛选出对判断借款人是否拖欠贷款起关键作用的属性,去除不相关、弱相关或冗余的部分。
经过仔细分析,确定了六个重要的借款人属性作为模型指标,具体如下:
- 第一列“Gender”代表借款人的性别;
- 第二列“loan_purpose”表示借款人的贷款目的;
- 第三列“loan_amount”指借款人的贷款金额;
- 第四列“property_value”是借款人的总资产;
- 第五列“income”为借款人的收入;
- 第六列“Credit_Score”代表借款人的信用评分;
- 第七列“Status”用于表明该借款人是否拖欠(0表示没拖欠,1表示拖欠)。
观察数据时发现,不少属性列存在空值,这会影响模型的准确性,因此必须进行数据清洗。通过编写程序,删除存在空值的行,对于性别列中“Sex Not Available”(即未知性别)的行也一并删除。
数据清洗关键代码如下:
import pandas as pd
# 读取数据
data = pd.read_csv('loan_data.csv')
# 删除存在空值的行
data = data.dropna()
# 删除性别未知的行
data = data[data['Gender'] != 'Sex Not Available']
print(f"清洗后的数据记录数: {len(data)}")
经过数据清洗,原本148670条记录减少到93596条。 清洗后的数据如下:
清洗后的数据中,第一列和第二列的数据为字符型,为方便后续建模,需进行数值化处理。数值化规则设定为:{“p1”:1, “p2”:2, “p3”:3, “p4”:4} ,{“Male”:0, “Joint”:1, “Female”:2},其中“Joint”表示男女共同贷款。
数值化后的数据如下:
由于六个指标的取值范围差异较大,为消除数量级数据带来的影响,还需进行数据标准化处理。
标准化后的数据如下:
随机森林算法实现
随机森林是机器学习中常用的算法,属于bagging集成策略,其原理是将多个基础模型(如决策树)组合,最终取平均值。Bagging中的boostrap是一种有放回的简单随机抽样方法。
数据预处理完成后,开始模型训练。为确保训练的准确性,先打乱数据顺序,再将80%的数据作为训练集用于模型训练,20%的数据作为测试集评估模型效果。
模型训练关键代码如下:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 提取特征和目标变量
features = data.drop('Status', axis=1)
target = data['Status']
# 数据标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 划分训练集和测试集
train_features, test_features, train_target, test_target = train_test_split(scaled_features, target, test_size=0.2, random_state=42)
# 训练随机森林模型
rf_model = RandomForestClassifier(n_estimators=1000, random_state=42)
rf_model.fit(train_features, train_target)
# 预测
train_pred = rf_model.predict(train_features)
test_pred = rf_model.predict(test_features)
模型训练完成后,计算训练样本和测试样本的预测结果。由于模型设定树的数量为1000棵,最终预测结果是1000个小模型结果的平均值,呈现为小数,通过四舍五入处理。模型的混淆矩阵如下:
通过混淆矩阵可计算模型在训练样本和测试样本上的预测准确率:
结果显示,模型在训练集和测试集上的准确率均高于0.8,表明模型较为准确,构建成功。
研究总结
本研究通过对贷款借款人数据的多步预处理,并应用随机森林算法,成功构建了贷款违约预测模型。该模型能有效预测借款人的违约可能性,为银行贷款决策提供有力支持。
在数据预处理环节,属性规约、数据清洗、数据变换和数据标准化等操作提升了数据质量与可用性。模型构建过程中,随机森林算法展现出良好性能,能有效处理高维数据和非线性关系。
未来研究可进一步探索梯度提升树、神经网络等其他机器学习算法,以提升模型预测准确率。同时,考虑引入借款人历史还款记录、负债情况等更多特征变量,丰富模型输入信息,增强模型预测能力。
关于分析师
在此对 Hao Li 对本文所作的贡献表示诚挚感谢,他在庆应义塾大学完成了统计专业的博士学位,专注数据分析、机器学习、数据采集领域。擅长 R 语言、Python 。

在此对 ZhiXiang Wang 对本文所作的贡献表示诚挚感谢,他完成了数据科学与大数据技术专业的学业,专注于机器学习(深度挖掘)、金融数据分析以及网络爬虫基础领域。擅长 Python、Java。

在此对 YuChen Bian 对本文所作的贡献表示诚挚感谢,他毕业于杭州电子科技大学信息与计算科学专业。他专注于深度学习、数据分析和数据采集等领域,擅长使用 Python、MySQL、R、SPSS、MATLAB 等软件工具 。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 专题:OpenClaw+DeepSeek智能体自动化部署与成本优化集成实践|附2案例代码教程
专题:OpenClaw+DeepSeek智能体自动化部署与成本优化集成实践|附2案例代码教程 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 注意力机制约束Claude Code智能体协同优化:集成TDD与上下文管理——以软件开发过程数据为例|附教程文档
注意力机制约束Claude Code智能体协同优化:集成TDD与上下文管理——以软件开发过程数据为例|附教程文档
