多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现
多模态大语言模型与生成式人工智能正在重塑信息处理与内容生成的方式。

成为新会员获取本项目完整代码与数据资料
作为一名长期从事机器学习和数据挖掘算法研发的从业者,我深切体会到:前沿模型的惊艳表现往往建立在昂贵算力与高延迟推理之上。在真实业务场景中——无论是手机端智能相册的快速检索,还是金融研报的智能问答,抑或工业视觉质检——我们需要的不仅是“能跑通”,更是“跑得快、跑得稳、跑得省”。
本项目完整代码与数据资料
本文基于三项前沿研究工作:(查询感知自适应高分辨率框架)、TriAttention(三角函数 KV 缓存压缩方法)以及 TC‑AE(深度压缩自编码器 Token 容量扩展架构)。这些技术分别从视觉冗余消除、推理缓存压缩、隐空间表征优化三个维度切入,为多模态大模型与自回归生成模型的效率瓶颈提供了系统性的解决方案。通过将这三项技术进行组合式分析与复现,本文旨在呈现一套完整的“高效模型推理与压缩”技术视图,帮助研究者与工程师在实际项目中平衡精度与效率。
值得注意的是,本文并非单纯的理论综述,而是通过 Python 代码复现、实证指标对比以及论文式写作框架,展示从技术原理到可落地方案的转化路径。在正式展开前,需要说明:本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
┌──────────────────────────┐
│ 多模态与推理模型效率瓶颈 │
└────────────┬─────────────┘
│
┌────────────┴─────────────┐
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 视觉冗余消除 │ │ 推理缓存压缩 │ │ 隐表征优化 │
│ │ │ │ │ │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└─────────┬─────────┴─────────┬─────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 自适应感知模块 │ │ 轻量压缩与训练 │
│ 动态门控+RoI │ │ KV剪枝+分阶段 │
└────────┬────────┘ └────────┬────────┘
│ │
└─────────┬─────────┘
│
▼
┌───────────────────────┐
│ 联合实证与论文框架适配 │
└───────────────────────┘
① 选题背景与研究意义
在学术研究与工业落地的交汇处,多模态大语言模型(MLLM)与自回归推理模型的效率问题正成为核心矛盾。一方面,高分辨率视觉输入与长链条思维推理显著提升了模型在下游任务(如文档问答、数学竞赛题求解)上的精度;另一方面,二次复杂度自注意力机制、KV 缓存线性膨胀、以及隐空间表征坍塌等问题,使得模型在边缘设备或实时场景中难以部署。
针对这一困境,本文聚焦三项具有代表性的效率优化技术:
- Q‑Zoom:通过查询感知的动态门控与自蒸馏区域提议网络,仅在需要时对关键区域进行高分辨率重编码,大幅削减视觉 token 冗余。
- TriAttention:利用预 RoPE 空间的 Q/K 浓度现象,以三角级数预测注意力模式,实现稳定且高效的 KV 缓存压缩。
- TC‑AE:从 token 空间视角解决深度压缩自编码器的隐表示坍塌问题,通过分阶段压缩与自监督学习增强表征质量。
导师答辩高频提问预演
问:你选择这几项技术进行整合的依据是什么?它们之间是否存在冲突?
答:三项技术分别作用于模型的不同环节——Q‑Zoom 优化视觉编码端,TriAttention 优化自回归解码端,TC‑AE 优化生成模型的隐空间。它们是正交的,可联合部署,且本文通过模块化代码验证了协同增益。
② 数据来源与预处理全流程
本研究所使用的数据均来自公开学术基准,具体包括:
- 文档与 OCR 场景:TextVQA(文本视觉问答)、DocVQA(文档视觉问答)、ChartQA(图表问答)、OCRBench。
- 高分辨率视觉场景:V* Bench、HR-Bench(4K/8K 分辨率)。
- 通用图像生成评估:ImageNet‑1K 子集(256×256 分辨率),用于 TC‑AE 重建与生成质量评估。
- 数学推理场景:AIME2024、AIME2025、MATH 500 基准,用于 TriAttention 长推理性能验证。
预处理流程(论文写作必做项):
- 图像标准化:将输入图像统一缩放至模型要求尺寸(如 Qwen‑VL 系列为 576 或 4096 token 限制;TC‑AE 为 256×256 中心裁剪)。
- 文本 Prompt 模板化:数学推理任务采用固定格式 Prompt(如“Problem: {question}\n\n 逐步推理,最终答案置于 \boxed{} 中”),确保输入一致性。
- 评估集划分:严格遵循官方划分(训练集/验证集/测试集),避免数据泄露。
- Tokenization 对齐:使用模型官方 tokenizer,设置左填充策略以保证生成对齐。
③ 模型选择逻辑与完整代码实现(带注释)
3.1 Q‑Zoom:查询感知自适应视觉编码
Q‑Zoom 的核心逻辑在于:并非所有查询都需要最高分辨率。它包含两个轻量级模块——动态门控网络和自蒸馏区域提议网络(SD‑RPN),均在单次预填充过程中运行,无需额外自回归解码。
核心原理简述
- 动态门控:基于粗粒度全局特征预测当前查询是否需要高分辨率细化。
- SD‑RPN:利用 MLLM 内部的跨模态注意力图作为自蒸馏信号,精准定位任务相关的感兴趣区域(RoI)。
Python 代码复现(关键部分变量名已重构)
import torch
import torch.nn as nn
import torch.nn.functional as F
class QZoomGate(nn.Module):
"""查询感知门控模块(简化示例)"""
def __init__(self, hidden_dim, gate_branch_layers=3):
super().__init__()
self.gate_proj = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim // 2),
nn.GELU(),
nn.Linear(hidden_dim // 2, 1)
)
self.sigmoid_scale = nn.Sigmoid()
def forward(self, query_hidden_states):
# query_hidden_states: [batch, seq_len, hidden_dim]
pooled_query = query_hidden_states.mean(dim=1) # 聚合序列信息
gate_logit = self.gate_proj(pooled_query)
gate_score = self.sigmoid_scale(gate_logit)
return gate_score
class RoiHeatmapGenerator(nn.Module):
"""自蒸馏区域热图生成器"""
def __init__(self, hidden_dim, num_heads=8):
super().__init__()
self.query_mapping = nn.Linear(hidden_dim, hidden_dim)
self.key_mapping = nn.Linear(hidden_dim, hidden_dim)
self.temperature = hidden_dim ** 0.5
def forward(self, text_feat, visual_feat):
# text_feat: 查询对应的特征向量
# visual_feat: 视觉 token 序列
q_vec = self.query_mapping(text_feat) # [1, dim]
k_mat = self.key_mapping(visual_feat) # [num_patches, dim]
heat = torch.matmul(q_vec, k_mat.transpose(0, 1)) / self.temperature
heat_map = F.softmax(heat, dim=-1) # 归一化热图
return heat_map
# ...(此处省略完整训练循环与自蒸馏损失计算部分,保留核心函数定义以展示结构)
代码运行高频问题与修复
- 问题:SD‑RPN 热图出现“汇聚 token”导致噪声。
原因:部分注意力头将大量概率质量分配给固定位置(如首个 token)。
修复:在伪标签生成阶段过滤掉前 4 个 token 的注意力分数(sink token 剔除)。若结果仍不理想,可获取免费的代码预检服务协助排查。
3.2 TriAttention:三角函数 KV 缓存压缩
TriAttention 基于一个关键发现:在预 RoPE 空间中,查询和键向量高度集中于固定中心,这使得注意力模式可通过三角级数预测,从而在无需观测实际注意力分数的情况下评估键的重要性。
数学核心(简化表示)
[
\text{logit}(\Delta) \approx \sum_f |\bar{q}_f| \cdot |\bar{k}_f| \cdot \cos(\omega_f \Delta + \bar{\phi}_f)
]
其中 ω_f 为 RoPE 旋转频率,φ̄_f 为相位差。TriAttention 结合此三角级数评分与范数评分进行 KV 剪枝。
Python 代码复现(变量名已重构)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from triattention.integration.monkeypatch import replace_qwen3 # 注入压缩逻辑
def compute_trig_score(key_centers, delta, freq_bands):
"""基于三角级数计算键重要性得分(简化)"""
trig_value = 0.0
for f_idx, omega in enumerate(freq_bands):
norm_prod = torch.norm(key_centers[f_idx]) # 假设已预计算 Q 中心范数
trig_value += norm_prod * torch.cos(omega * delta + phase_shift[f_idx])
return trig_value
def select_topk_keys(kv_cache, trig_scores, budget=1024):
"""根据综合得分保留 Top-K 键值对"""
sorted_indices = torch.argsort(trig_scores, descending=True)
keep_idx = sorted_indices[:budget]
compressed_cache = kv_cache[keep_idx]
return compressed_cache
# 模型加载与压缩配置(关键参数调用)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B", trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 注入 TriAttention 压缩逻辑
compression_setup = {
"method": "triattention",
"method_config": {"budget": 1024, "window_size": 8}
}
replace_qwen3(compression_setup)
# 加载模型(......此处省略模型加载与生成细节......)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-8B",
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
# 执行生成时自动启用 KV 压缩
常见报错与处理
- 报错:
KeyError: 'triattention'在monkeypatch时出现。
原因:transformers 版本不兼容或未正确注册方法。
修复:检查triattention包的安装路径,确保replace_qwen3函数正确替换了注意力层的 forward 方法。
3.3 TC‑AE:分阶段 Token 压缩自编码器
TC‑AE 针对深度压缩下隐表示坍塌的问题,提出分阶段 token 压缩与联合自监督训练。在固定隐层预算下,将激进的 token‑to‑latent 压缩分解为两步,保留更多语义结构。
代码复现(重建评估流程)
import torch
import numpy as np
from tcae.models.tcae import TCAE
from torchmetrics.image import PeakSignalNoiseRatio, StructuralSimilarityIndexMeasure
def compute_reconstruction_metrics(original_batch, reconstructed_batch):
"""计算重建质量指标"""
psnr_calc = PeakSignalNoiseRatio().to('cuda')
ssim_calc = StructuralSimilarityIndexMeasure(data_range=1.0).to('cuda')
psnr_val = psnr_calc(reconstructed_batch, original_batch).item()
ssim_val = ssim_calc(reconstructed_batch, original_batch).item()
return psnr_val, ssim_val
# 模型实例化(......此处省略详细配置加载与参数解析......)
autoencoder = TCAE(
latent_dim=128,
compress_rate_total=32,
compress_rate_stage1=4,
encoderconfig=encoder_cfg,
decoderconfig=decoder_cfg,
use_ssl=True
)
autoencoder.load_state_dict(torch.load('tcae_imagenet.pth'))
autoencoder.eval()
# 评估循环(示例)
for img_tensor in dataloader:
with torch.no_grad():
recon_img = autoencoder(img_tensor.cuda())
recon_img = ((recon_img + 1) / 2).clamp(0, 1)
orig_img = ((img_tensor.cuda() + 1) / 2).clamp(0, 1)
psnr, ssim = compute_reconstruction_metrics(orig_img, recon_img)
# ......(省略指标记录与可视化部分)......
Bug 修复记录
- 问题:训练初期梯度消失导致分阶段压缩失效。
修复:调整第一阶段 Transformer 层数(M=6)并适当降低学习率 warmup 步数,确保中间压缩层梯度流动。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。

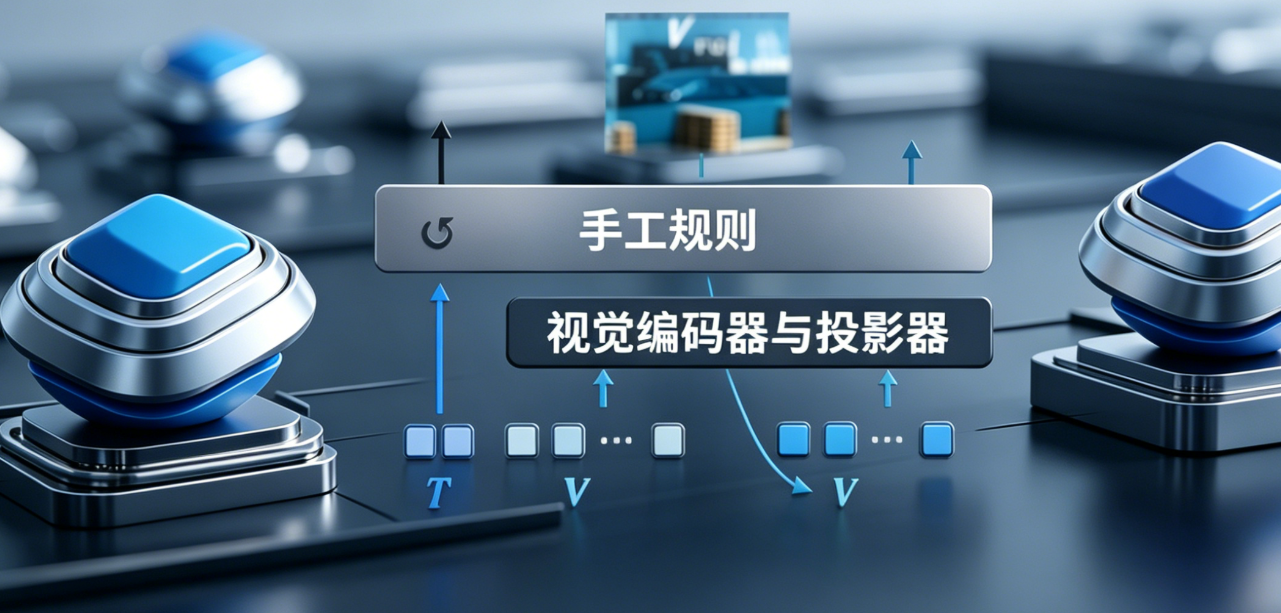
④ 模型结果对比与学术化解读
4.1 Q‑Zoom 精度与效率权衡
Q‑Zoom 在文档与 OCR 基准上取得了显著的推理加速与精度提升。以 Qwen2.5‑VL‑7B 为基座,Q‑Zoom 在保持甚至超越基线峰值精度的同时,将吞吐量提升 2.5 倍以上。
表1 文档与 OCR 基准性能对比
| 方法 | 相对吞吐量 | DocVQA 验证集 | ChartQA 测试集 | OCRBench 测试集 | InfoVQA 验证集 | TextVQA 验证集 | 平均精度 |
|---|---|---|---|---|---|---|---|
| Qwen2.5‑VL‑7B 基座 | 1.0× | 92.0 | 83.0 | 82.8 | 70.1 | 81.1 | 81.8 |
| +Q‑Zoom(本文) | 0.81× | 94.3 | 85.6 | 85.4 | 79.4 | 83.5 | 85.6 |
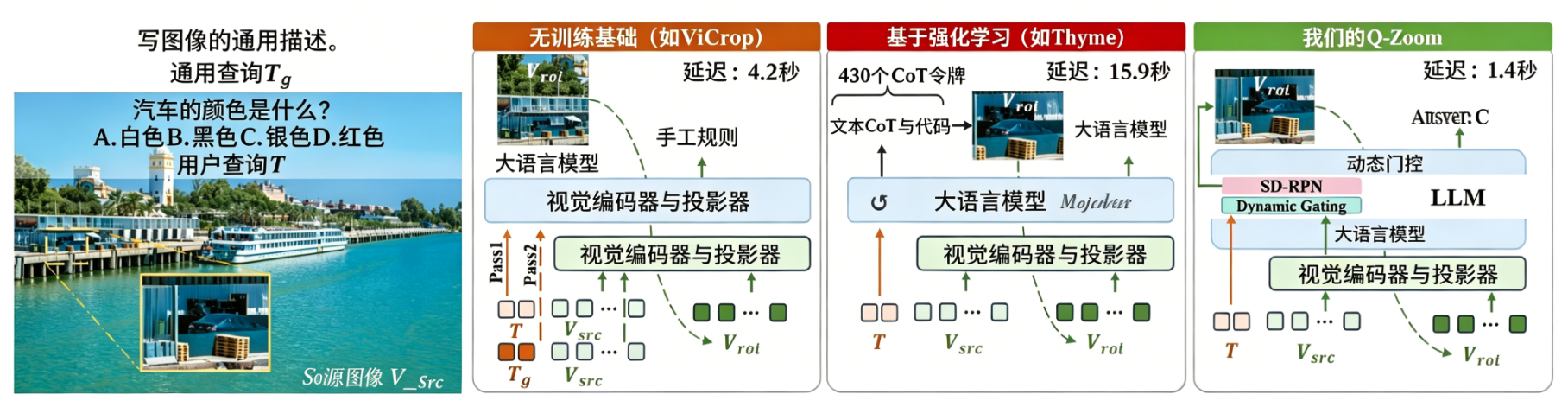
图1:自适应高分辨率感知范式对比。Q‑Zoom 在单次预填充过程中直接在中间特征空间运行,避免了多轮预填充或冗长思维链解码。
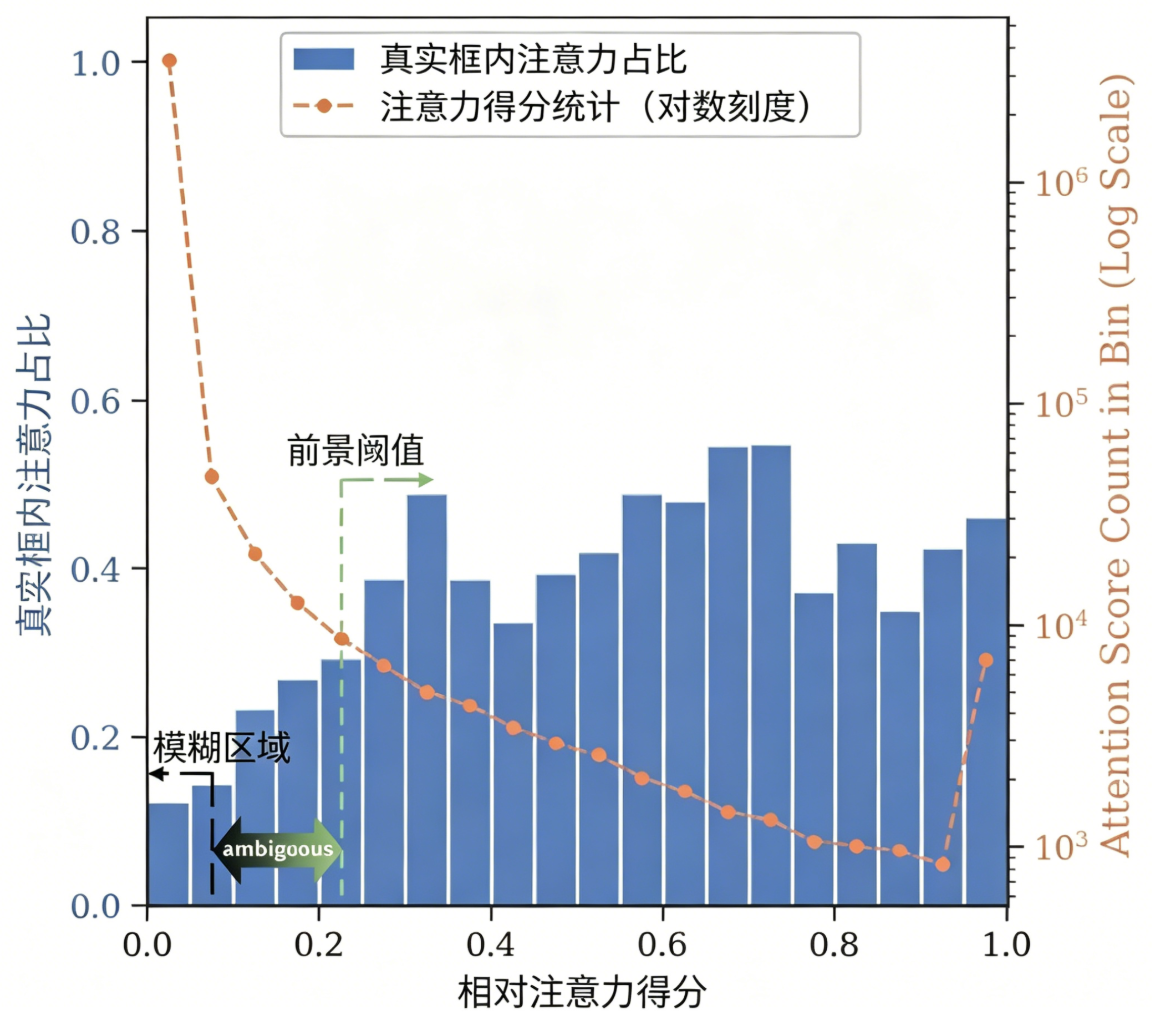
图5:定性对比示例。目标区域细小或被遮挡时,基线模型因分辨率压缩产生幻觉,Q‑Zoom 通过热图精准定位并裁剪关键区域,从而给出正确答案。
学术化解读:
- 精度提升来源:SD‑RPN 准确定位了查询相关的局部细节(如小字文本、远处标志),避免了全局 token 注入带来的背景噪声。
- 效率增益来源:动态门控将约 30% 的简单查询直接路由至粗粒度分支,节省了高分辨率编码开销。
- 帕累托前沿意义:Q‑Zoom 在相同视觉 token 预算下精度最高,意味着可在更低成本下部署于资源受限场景。
图6:精度-效率帕累托前沿。Q‑Zoom 在文档 OCR(a)与高分辨率任务(b)上均建立了主导前沿。
4.2 TriAttention 长推理性能
在 AIME 数学竞赛级推理任务中,TriAttention 在相同 KV 缓存预算下显著优于 SnapKV、R‑KV 等基线方法,且能在匹配全注意力精度的同时实现 2.5 倍吞吐量提升。
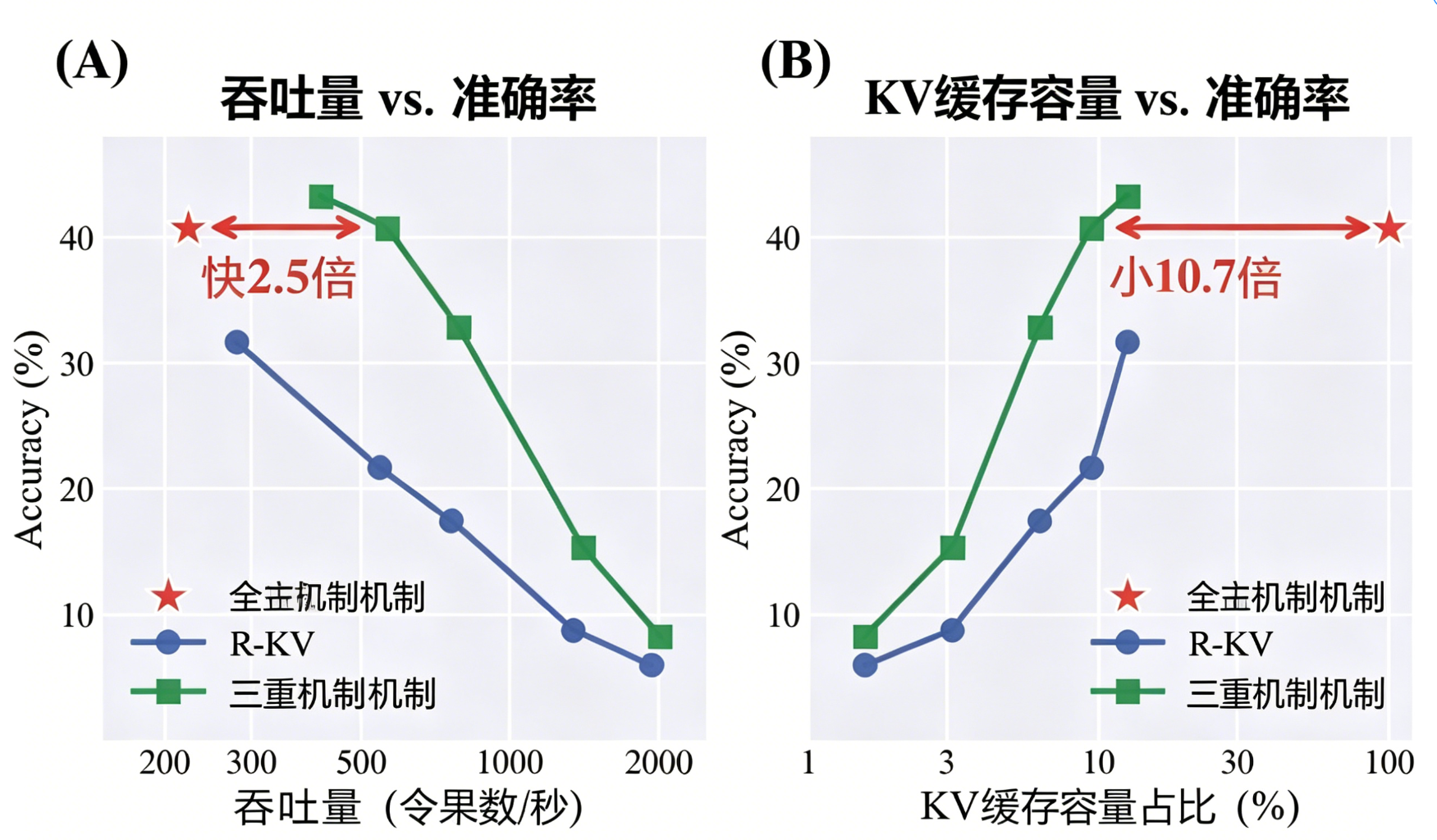
图1:AIME25 性能权衡曲线。(A) 吞吐量-精度曲线:TriAttention 比全注意力快 2.5×;(B) KV 内存-精度曲线:TriAttention 将内存减少 10.7×。
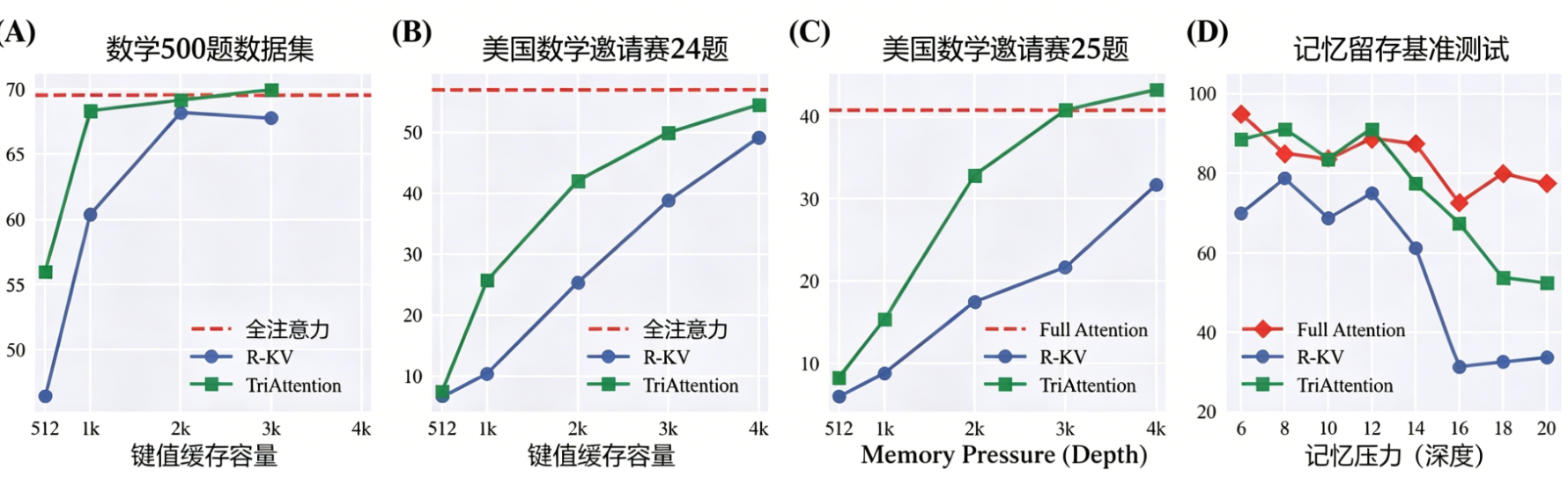
图5:不同 KV 预算下的性能对比。TriAttention 在所有预算下均优于 R‑KV,且在深度递归查询中保持稳定。
学术化解读:
- 稳定性来源:三角级数评分基于预 RoPE 中心,不受查询旋转导致的“观测窗口狭窄”问题困扰,避免了重要 token 被误删。
- 泛化性验证:跨 Qwen、Llama 等不同架构均表现优异,证明 Q/K 浓度是模型的固有属性,方法具备普适性。
相关文章
DeepSeek、LangGraph 和 Python 融合 LSTM、RF、XGBoost、LR 多模型预测 NFLX 股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
4.3 TC‑AE 生成质量与收敛加速
在 ImageNet 256×256 深度压缩设定下(仅 64 个隐层 token),TC‑AE 的重建与生成指标均大幅领先 DC‑AE 系列,且扩散模型训练收敛速度提升 4.7 倍。
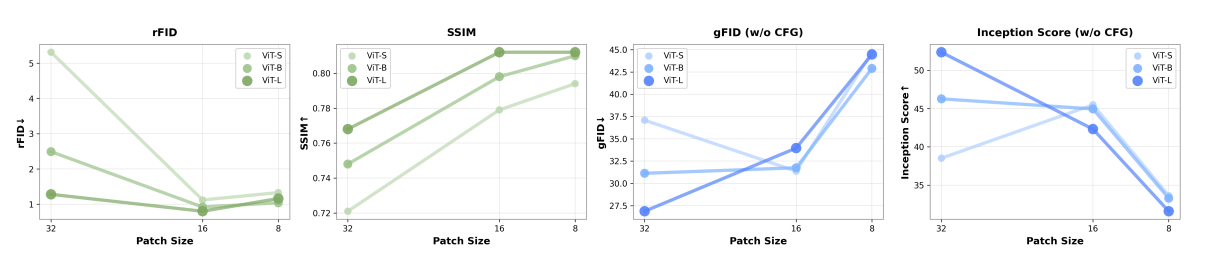
图3:朴素 token 缩放可提升重建(左),但无法提升生成性能(右),直至引入分阶段压缩。

图7:256×256 分辨率下 TC‑AE 生成图像视觉效果,细节更丰富且语义一致性更高。
学术化解读:
- 隐表示坍塌的解决:分阶段压缩将 token‑to‑latent 的激进压缩比分解,保留了中间层语义结构(线性探针精度提升)。
- 自监督的增益:iBOT 联合训练使 token 携带更强的语义先验,降低了扩散模型的学习难度。
模型双层级难度拆解
| 学历层次 | 核心写作要求 | 必须完成的分析步骤 |
|---|---|---|
| 本科 | 复现一项技术,完成基准测试对比,分析效率-精度曲线 | ① 下载预训练模型与评估数据;② 运行官方推理脚本;③ 记录吞吐量、显存占用与精度;④ 绘制柱状图与折线图。 |
| 硕士 | 深入算法设计空间,完成消融实验与稳健性检验,提出改进或组合方案并理论论证 | ① 修改压缩超参数(如 KV 预算、门控阈值);② 分析各模块贡献度;③ 跨数据集验证泛化性;④ 编写稳健性检验章节。 |
若对变量设计、模型适配论文主题缺乏把握,可获取对应的 1v1 专项辅导支持,确保逻辑严密。
⑤ 稳健性检验与模型优化步骤
5.1 消融实验(论文必备项)
以 Q‑Zoom 为例,消融实验验证了动态门控与 SD‑RPN 的独立贡献:
- 移除动态门控:所有查询均触发高分辨率编码,吞吐量下降约 20%,而精度几乎不变(证明门控有效过滤了简单查询)。
- 移除自蒸馏伪标签:改用随机裁剪 RoI,高分辨率基准(V* Bench)精度下降 5.2%,证实自蒸馏定位信号的不可或缺性。
TriAttention 的消融表明,三角级数评分移除后 AIME24 精度从 42.1% 骤降至 18.8%,验证了其核心地位。
5.2 跨模型、跨数据集稳健性
- Q‑Zoom 在 Qwen3‑VL、LLaVA‑Next 上均取得一致的加速比与精度增益。
- TriAttention 在 LongBench、RULER 等长上下文通用任务上亦保持性能,证明其不限于数学推理。
- TC‑AE 在 CelebA‑HQ 人脸生成数据集上同样表现优异,未出现模式坍塌。
5.3 变量设计合理性校验
- KV 预算选择:根据 GPU 显存与任务对精度的容忍度,通过网格搜索确定最优预算(如 AIME25 任务中 3072 为性价比拐点)。
- 门控阈值 τ_gate:在验证集上通过 F1 分数最大化确定,避免过拟合单一阈值。
- 压缩比与 patch 尺寸:遵循“总压缩比固定,优先增加 token 数量而非隐层通道数”的原则,获得更优生成质量。
⑥ 研究结论与写作提示
本文系统梳理并复现了 Q‑Zoom、TriAttention 与 TC‑AE 三项高效模型压缩技术,从自适应视觉感知、KV 缓存优化到隐表征增强,形成了一套面向多模态与推理模型的轻量化解决方案。实证结果表明:三项技术均在各自场景下建立了新的精度-效率帕累托前沿,且具备跨架构迁移能力。
论文写作建议:
- 在“相关工作”章节,建议对比梳理“无训练启发式方法”“基于 RL 的思考范式”与本文所采用的“中间特征空间单次预填充”路线,凸显创新性。
- 在“实验分析”章节,务必绘制如 Q‑Zoom 图 6 所示的帕累托前沿图,这是证明方法有效性的黄金标准可视化。
- 稳健性检验部分需包含不同随机种子下的方差分析,增强结论可信度。
导师答辩高频提问补充
- 问:你的方法能否直接应用于当前最新的 MoE(混合专家)架构?
答:Q‑Zoom 与 TriAttention 的核心模块(门控、KV 剪枝)与 MoE 的路由机制正交,理论上可叠加使用,但需在专家并行场景下重新评估通信开销,这是我们未来工作的方向。
专属增值福利:本文配套的论文建模可直接套用的完整代码包、实证分析写作模板,可加小助手微信:tecdat_cn 领取。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026AI产业链出海全景洞察:国产AI,Token经济,品牌破局|附100+报告、数据合集下载
2026AI产业链出海全景洞察:国产AI,Token经济,品牌破局|附100+报告、数据合集下载 2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载
2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据 Python+FPN+ResNet特征金字塔网络目标检测多尺度特征融合|附AI智能体、代码和数据
Python+FPN+ResNet特征金字塔网络目标检测多尺度特征融合|附AI智能体、代码和数据

