注意力机制约束Claude Code智能体协同优化:集成TDD与上下文管理——以软件开发过程数据为例
想象一下,你正面对一个庞大且不断演进的代码库,每天要处理数十个特性开发与缺陷修复。

成为新会员获取本项目完整教程文档、代码和数据资料
本文将带你深入探索如何通过一系列设计模式——从规划约束、上下文管理、指令系统优化,到测试驱动开发与钩子防护——将Claude Code从“随机的代码生成器”转变为“可预测的协同开发者”。 我们将结合来自Abnormal AI、incident.io、Trail of Bits等公司的生产实践,呈现一套经过验证的智能体协同工作流。无论你是刚入门还是希望进阶,都能从中找到提升开发效能的钥匙。下图概括了本文的核心脉络:
规划阶段
↓
注释循环(精准决策)
↓
CLAUDE.md指令系统(渐进披露)
↓
上下文管理(文档清除)
↓
测试驱动开发(TDD循环)
↓
钩子防护(确定性规则)
↓
成本优化与模型选型
↓
常见问题与故障排除
本项目完整教程文档、代码和数据资料
规划的力量:将模糊决策转化为精准规范 智能体在无引导下的单步决策准确率可能很高,但当面对包含20个决策点的特性开发时,即便每步准确率80%,最终完全正确的概率也仅有0.8²⁰≈1%。规划的核心作用就是将这20个模糊决策压缩成一份经过审查的规范,让每个决策点都接近100%的正确率——因为你在规划阶段已经做出了明确选择。
注释循环工作流
在大规模团队中效果最好的规划方法是注释循环,由Boris Tane提出。流程如下:
- 让Claude起草一份
plan.md。 - 在编辑器中打开,添加内联注释,指出错误或模糊之处:“使用
drizzle:generate,不要用原生SQL”“这里应该是PATCH而非PUT”。 - 将注释后的计划发回,并加上保护性短语“处理所有注释,暂不实现”。这个短语至关重要,否则智能体会跳过计划直接编码。
- 循环直至计划无歧义,然后让Claude实现。由于所有决策已预先敲定,实现过程中的错误大大减少。
# plan.md — 注释循环示例
## 步骤3:数据库迁移
为用户表创建新的迁移。
> 注意:使用 drizzle:generate,不要用原生SQL
> 注意:添加 created_at 字段,默认值为 NOW()
## 步骤4:API 端点
添加 PUT /users/:id 端点。
> 注意:这应该是 PATCH 而非 PUT,只允许部分更新。
# 注释完成后,发送:
# “处理所有注释,暂不实现”
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
使用Claude Code内置规划模式
如果注释循环显得繁重,Claude Code的规划模式提供了轻量替代:
- 按Shift+Tab两次进入规划模式。
- 在对话中迭代计划。
- 按Shift+Tab一次切换回自动接受模式。
计划会被持久化到~/.claude/plans/,即使会话压缩或重启也不会丢失,因此内置规划模式是大多数任务的可靠默认选择。对于大型特性,提前编写完整规范同样有效:某开发者花2小时编写12步规范,预计节省了6-10小时的实现时间。
拓展规划思维
无论采用何种方式,在请求计划时附上优秀的开源代码示例,能显著提升输出质量——智能体在有工作参考时比仅靠抽象描述表现更好。规划还能通过git工作树横向扩展。incident.io的工程师同时运行4-5个并行的Claude会话,每个会话在不同分支上独立执行计划。一位工程师仅花费8美元Claude信用额度,就实现了将团队每日使用的工具API生成时间缩短18%,每次节省30秒。有些开发者更进一步,并行运行多个工作树实现同一问题的不同方案,然后比较结果。
CLAUDE.md 架构最佳实践:在有限的注意力预算内传递关键指令 你的CLAUDE.md文件有一个你可能不知道的“预算”。HumanLayer对Claude Code内部的剖析发现,系统会在你的指令上方注入一条提醒:“此上下文可能与你的任务相关,也可能无关。”这意味着智能体会主动过滤它遵循的内容,而不是将所有指令视为永久命令。此外,前沿思维模型大约能遵循150-200条指令,之后依从性就会下降,而Claude Code自身的系统提示占用约50条。因此,你的规则大约剩下100-150条“插槽”。HumanLayer将其自身文件控制在60行以内。
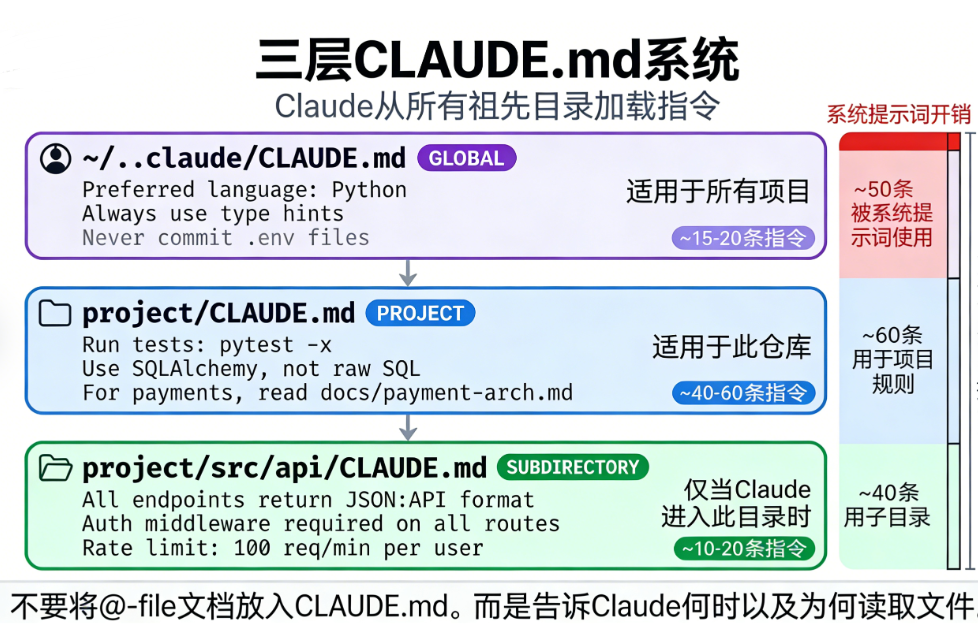
你可以观察这个预算的实际效果。在CLAUDE.md中添加一行“始终称呼我为Mr.Tinkleberry”,然后看智能体多久停止使用它——通常只需几千个token。当称呼消失时,你的指令已被注意力机制降级,CLAUDE.md中的其他规则也随之失去影响力。
渐进披露:指令引用的正确方式
在这个预算内工作的方式是渐进披露。你的根目录CLAUDE.md保持简短,聚焦于普遍适用的规则。对于任何领域特定的内容,引用外部文件而不内联:“处理支付系统时,先阅读docs/payment-architecture.md。”智能体只在进入代码库相应区域时才读取被引用的文件,从而为高优先级规则保留指令预算。一家每月消耗数十亿token的公司以这种方式组织其单体仓库的CLAUDE.md,每个团队分配一个token预算部分:
# 单体仓库 CLAUDE.md — 渐进披露示例
## Python 相关
- 函数签名必须使用类型提示
- 测试命令:pytest -x --tb=short
...阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。子目录中的CLAUDE.md文件进一步扩展了此方法。在src/persistence/中放置数据库特定指令,在src/api/中放置端点约定。Claude会自动从工作目录向上加载CLAUDE.md文件至项目根目录,因此子目录文件仅在智能体在该区域工作时激活。这使根文件保持通用,同时为智能体提供所需的有针对性指导。一个常见错误:不要在CLAUDE.md中使用@引用文档。这会将会话中嵌入整个文件,在对话开始前就消耗指令预算。
上下文管理:在200K token窗口中保持智能体清醒 Claude Code提供200K token的上下文窗口,但可用窗口比看起来小。一个新会话加载系统提示、工具定义和CLAUDE.md大约消耗20K token。每个MCP服务器添加的工具模式会永久占用上下文,因此实际限制约为5-8个服务器,否则会挤占实际工作空间。更糟的是,质量早在窗口满之前就开始下降。多位实践者独立得出相同阈值:不要让上下文超过60%容量。Claude的输出在窗口20%-40%时就开始退化,因为注意力机制随着上下文填充,早期指令的权重会降低。自动压缩在约83.5%触发,且是有损的:有开发者因此丢失了3小时的重构工作,压缩后只保留了约20%-30%的细节。

文档清除模式:最有效的防御策略
最佳防御是文档清除模式。当上下文变得臃肿时:
- 将当前计划和进度导出到markdown文件。
- 运行
/clear重置会话。 - 重新开始,让Claude读取该文件。
这样你获得完整的200K窗口,只包含你选择保留的信息,优于/compact,因为你可以精确控制哪些内容幸存。自定义/catchup命令使过渡更顺畅:清除后,它会读取当前git分支上所有已更改的文件,让Claude从你离开的地方继续,而不保留旧对话历史。
<!-- .claude/commands/catchup.md -->
# 在 /clear 后重建上下文
# 读取当前分支与 main 相比所有修改过的文件
# 理解每个文件的变更...用自定义技能转移上下文
我使用一个/transfer-context技能进一步扩展此模式。当会话开始退化时,该命令导出一个结构化交接文件,包含已完成工作、未决决策、需避免的陷阱和相关文件路径。下一个会话读取该文件,仅携带重要信息,没有会话臃肿。你也可以通过延迟加载工具来主动节省上下文。一个项目通过使用UserPromptSubmit钩子,仅在用户提示触发关键词时注入技能定义,而不是在启动时预加载所有内容,从而为每次会话节省约15,000 token。所有这些背后的简单规则:一次对话只处理一个任务。从头开始消耗20K token,与污染会话带来的质量损失相比微不足道。阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
钩子:将70%的遵循度提升至100%的确定性防护 即使是精心构造的CLAUDE.md,智能体遵循度也只有约70%。对于编码风格偏好,这可以接受;但对于安全规则如“不要推送到main”或“不要删除生产数据”,这远远不够。钩子通过在工作流关键点执行shell脚本,将遵循度提升至100%。
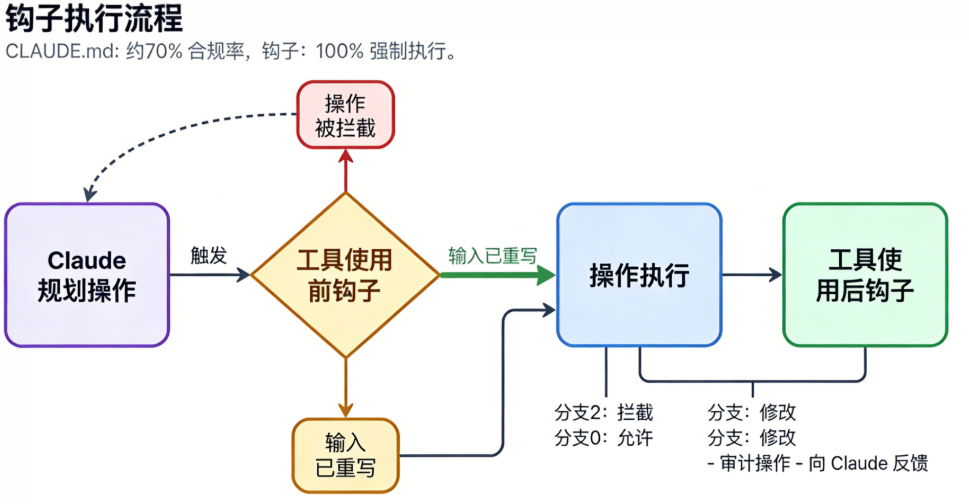
有两种类型值得了解:阻塞型钩子作为PreToolUse事件运行,能直接阻止操作(退出码2阻止操作并强制智能体尝试其他方案);提示型钩子提供非阻塞反馈,如每次编辑后运行linter并将输出返回给智能体,而不中断其流程。最全面的公开钩子配置实现了以下功能:阻止rm -rf命令(建议改用trash)、禁止直接推送到main分支、记录所有变更及时间戳、运行反合理化检查。该检查使用Haiku模型审查智能体的响应,捕捉“预先存在的问题”或“超出范围”等推诿言辞。当检测到智能体过早宣布胜利时,会拒绝响应并提供具体反馈,强制其继续工作。一个轻量级设置可在每次文件编辑后自动运行Prettier和TypeScript检查:阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。一个需避免的陷阱:不要在规划中期阻塞Edit或Write工具。写入时阻塞会破坏多步推理,因为智能体会失去上下文。让它完成写入,然后通过PostToolUse钩子或预提交检查进行验证。
测试驱动开发:智能体编码的最优策略 没有测试时,智能体验证自身工作的唯一方式是依赖自身判断,而随着上下文填充,判断力会下降。测试创建了一个外部“神谕”,无论会话运行多久都保持准确。每个红-绿循环为智能体提供明确反馈,且它可以在无需人工干预的情况下迭代整个测试套件,这使得测试驱动开发成为与智能体编码工具协作的最强模式。Anthropic推荐的流程遵循特定顺序:先写测试、确认测试失败、将失败的测试作为检查点提交、实现直至全绿。最后一条指令比看起来更重要。智能体有时会修改测试以使其通过,而不是修复实现。提前提交测试提供了一个安全网:如果智能体修改了测试,diff会精确显示变更,你可以轻松回滚。对于前端工作,视觉变体同样有效:给智能体设计稿加上Puppeteer MCP服务器,它在实现后会截图,与设计稿比较,然后迭代。当智能体可以将自己的输出与视觉目标对照时,质量能提升2-3倍。阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
探索观点成本经济学与模型选择 Anthropic官方数据显示,Claude Code平均成本约为每天每开发者6美元(按API定价),每月约100-200美元(使用Sonnet 4.6)。Max订阅计划则完全改变了成本结构。一位开发者追踪了8个月约100亿token的使用情况,发现API等效成本超过15,000美元,而其实际Max订阅费用仅约800美元,节省了93%。超过90%的token是缓存读取,这就是计量API定价比固定订阅贵得多的原因。Max计划的盈亏平衡点约为每月100-200美元的API等效使用量,任何日常用户都会很快跨过这个门槛。
| 定价模式 | 月成本 | 适用场景 |
|---|---|---|
| API(Sonnet 4.6) | ~100-200美元 | 轻度使用,每天<30分钟 |
| API(Opus 4.6) | ~300-800美元 | 复杂多文件任务 |
| Max(100美元/月) | 100美元 | 日常用户,盈亏平衡约100美元API等效 |
| Max(200美元/月) | 200美元 | 重度用户,每天>5小时 |
模型选择也是一项优化。Claude Code的“opusplan”模式将Opus 4.6用于规划,自动切换至Sonnet 4.6进行代码生成,在关键规划环节获得Opus级推理,同时利用Sonnet便宜5倍的token进行实现。Sonnet 4.6在Anthropic内部测试中被59%的Claude Code用户首选,且倾向于生成更简洁的代码,避免过度工程。对于子智能体密集型工作流,设置CLAUDE_CODE_SUBAGENT_MODEL="claude-sonnet-4-5-20250929"使子智能体运行在Sonnet上,同时保留Opus作为协调者。务必避免三大token浪费源:任务间不清除上下文、因CLAUDE.md结构不佳导致的冗余文件读取、模糊提示使智能体陷入试错循环。仅修复这三项通常能将token消耗减半。阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
常见问题与故障排除 上下文丢失:最严重的失败模式是上下文丢失。前文介绍的文档清除模式正是为此而生:绝不让长时间会话成为决策的唯一记录。频繁提交,将进度导出到文件,将每次会话视为可丢弃的。处理小众技术时的幻觉:智能体对不熟悉的技术会生成自信但看似合理的代码。如果你使用的语言或框架无法亲自验证,每个输出都需要额外审查。如一位开发者所言:“用LLM处理我不熟悉的技术,我给自己惹了一大堆麻烦;但处理熟悉的技术时,LLM极大地提升了我的效率。”过度工程是常见倾向。智能体会编写多余的抽象、未经请求的辅助函数、过早的重构,除非你明确禁止。在CLAUDE.md中添加“使用尽可能简单的方法”会有所帮助,同时按问题领域而非技术层组织代码库,也能降低智能体和人类的认知负担。关键数据丢失:有记录的最严重故障:在构建自然拼读应用时,智能体删除了开发者已获授权使用的每个音素音频文件,并用AI生成的声音替换。它重命名文件,并“确信自己标记错误,尽管它本身根本无法区分相关音素。”教训:在允许智能体访问不可替代的文件之前,务必提交或备份。无效会话:Anthropic对偏离轨道的会话的建议非常坦诚:在让智能体工作前保存状态,让它运行,然后要么接受结果,要么重新开始,而不是费力纠正。对提交的信任程度取决于测试覆盖率和风险承受能力。有些开发者每天通过斜杠命令提交数十次,以PR审查作为把关;对于有付费用户的生产代码库,审查每个diff值得付出额外努力。
资源与实践 如果你想进一步探索,以下资源值得关注:Anthropic官方Claude Code最佳实践 – 权威上游来源。阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
结论 本文中的每一个模式都指向同一核心理念:在执行前对Claude进行积极约束,然后赋予它验证自身输出的方式。规划消除歧义,CLAUDE.md和钩子划定边界,测试提供验证,上下文卫生确保跨会话的连续性。如果你只能选择一项改进开始,那就选择文档清除模式。会话间上下文腐烂的代价远大于重新开始所需的20K token。之后:添加一个在测试失败时阻止提交的预提交钩子、在接触代码前为每个多文件任务制定计划、保持CLAUDE.md指令数少于100条,使用子目录文件处理领域特定规则。阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载
2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载 2026年数字化数智化转型趋势报告:价值、AI落地与风险平衡 | 附200+报告、数据合集下载
2026年数字化数智化转型趋势报告:价值、AI落地与风险平衡 | 附200+报告、数据合集下载 2026年Agent智能体深度研究报告:问答到行动—产业化路径与风险全景|附150+报告、数据合集下载
2026年Agent智能体深度研究报告:问答到行动—产业化路径与风险全景|附150+报告、数据合集下载 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

