多源特征融合新闻文本分类实战:LLM语义嵌入、TF-IDF与结构化元数据Scikit-learn端到端管道构建
在当今数据驱动的商业环境中,企业往往面对的是多源异构的数据——既有非结构化的文本,又有结构化的元数据,还有来自预训练模型的语义表示。

本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
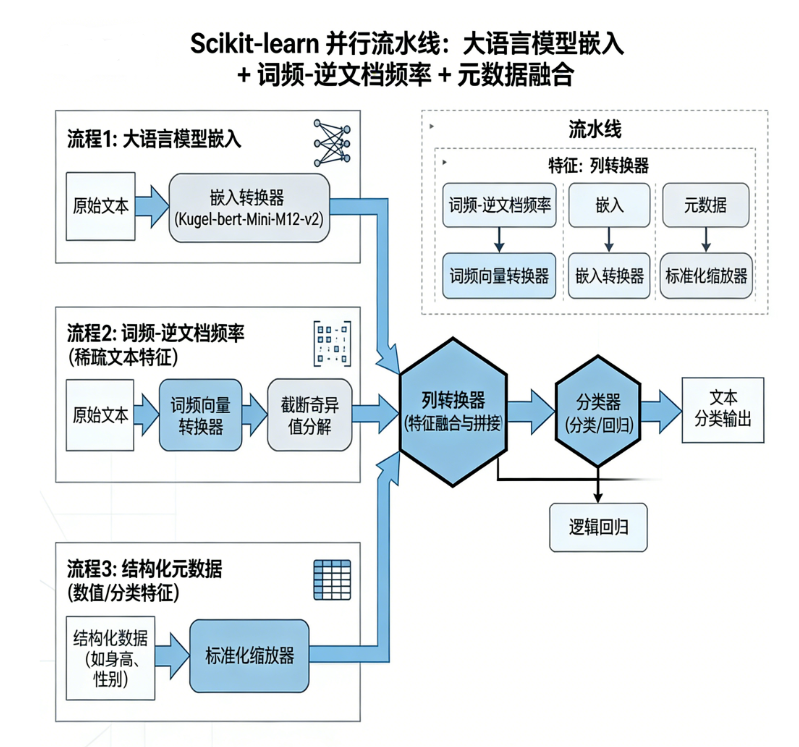
我们将以新闻文本数据集为例,通过合成元数据特征,分别构建三条特征处理分支,最后利用 ColumnTransformer 将它们无缝拼接,并训练一个逻辑回归分类器。整个过程既展示了 Scikit-learn 的灵活性与强大功能,也体现了多源信息融合在提升分类准确性上的巨大潜力。下图概括了本文的核心技术脉络:
数据加载
|
v
特征工程分支
+---------+---------+
| | |
v v v
TF-IDF LLM嵌入 元数据
| | |
v v v
降维(SVD) 直接使用 标准化
| | |
+---------+---------+
|
v
ColumnTransformer
|
v
特征融合
|
v
分类器(LogisticRegression)
|
v
模型评估成为新会员获取本项目完整代码和数据资料
数据准备与特征工程
数据集选择与加载
我们选用 Scikit-learn 内置的 20 数据集,它包含了来自不同新闻组的文章,非常适合文本分类演练。为了降低计算开销并突出多源特征融合的效果,我们仅选取四个具有代表性的类别:棒球、太空、计算机图形学和政治。下面的代码实现了数据加载与初步筛选:
本项目完整代码和数据资料
合成结构化元数据
现实场景中,文本数据往往伴随丰富的元信息,如文章长度、单词数、大小写比例等。本例中我们基于原始文本合成五类元数据特征,用以模拟真实业务中的结构化信息:
def build_metadata(text_list):
# 计算文本长度
char_cnt = [len(t) for t in text_list]
word_cnt = [len(t.split()) for t in text_list]
avg_word_len = []
upper_ratio = []
digit_ratio = []
for t in text_list:
words = t.split()
if words:
avg_word_len.append(np.mean([len(w) for w in words]))
else:
avg_word_len.append(0)
denom = max(len(t), 1)
upper_ratio.append(sum(1 for c in t if c.isupper()) / denom)
digit_ratio.append(sum(1 for c in t if c.isdigit()) / denom)
return pd.DataFrame({
'raw_text': text_list,
'char_len': char_cnt,
'word_num': word_cnt,
'avg_word_len': avg_word_len,
'upper_frac': upper_ratio,
'digit_frac': digit_ratio
})
# 生成完整DataFrame
news_df = build_metadata(texts_raw)
news_df['target'] = labels_raw
news_df.head()阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
训练/测试集划分
在构建任何特征之前,必须先将数据划分为训练集和测试集,以防止信息泄露。这里我们采用分层抽样确保类别分布一致:
from sklearn.model_selection import train_test_split
X_all = news_df.drop(columns=['target'])
y_all = news_df['target']
X_train, X_test, y_train, y_test = train_test_split(
X_all, y_all,
test_size=0.2,
random_state=2025,
stratify=y_all
)最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
构建多源特征处理分支
1. TF-IDF特征管道
TF-IDF能够捕捉词频与逆文档频率信息,是经典的文本统计特征。我们首先构建一个包含向量化与降维的管道:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
# TF-IDF + SVD降维管道
tfidf_flow = Pipeline([
('vectorizer', TfidfVectorizer(max_features=5000)),
('svd_reduce', TruncatedSVD(n_components=300, random_state=2025))
])2. LLM语义嵌入管道
使用预训练的 Sentence Transformer 模型将文本转换为稠密向量,这里我们封装了一个自定义的 Scikit-learn 转换器:
from sklearn.base import BaseEstimator, TransformerMixin
from sentence_transformers import SentenceTransformer
class TextEmbedder(BaseEstimator, TransformerMixin):
def __init__(self, model_id="all-MiniLM-L6-v2"):
self.model_id = model_id
self.encoder = None
def fit(self, X, y=None):
self.encoder = SentenceTransformer(self.model_id)
return self
def transform(self, X):
# 生成嵌入向量,省略进度条显示
embeddings = self.encoder.encode(
X.tolist(),
show_progress_bar=False
)
return np.array(embeddings)
embed_flow = Pipeline([
('embedder', TextEmbedder())
])阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3. 元数据标准化管道
元数据特征具有不同的量纲,需要标准化处理:
from sklearn.preprocessing import StandardScaler
# 元数据特征列名
meta_cols = ['char_len', 'word_num', 'avg_word_len', 'upper_frac', 'digit_frac']
meta_flow = Pipeline([
('scaler', StandardScaler())
])
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
探索观点特征融合与分类器集成
使用 ColumnTransformer 合并多源特征
ColumnTransformer 允许我们将不同列(或数据源)分别应用不同的转换器,然后将结果横向拼接:
from sklearn.compose import ColumnTransformer
# 融合三个分支
feature_union = ColumnTransformer(
transformers=[
('tfidf_branch', tfidf_flow, 'raw_text'),
('embed_branch', embed_flow, 'raw_text'),
('meta_branch', meta_flow, meta_cols)
],
remainder='drop' # 丢弃未指定的列
)构建端到端分类管道
最后,将特征融合步骤与分类器组合成一个完整的管道,实现从原始数据到预测的无缝衔接:
from sklearn.linear_model import LogisticRegression
final_pipeline = Pipeline([
('assemble', feature_union),
('classifier', LogisticRegression(max_iter=2000))
])
# 训练模型(此处省略部分超参数调优代码)
final_pipeline.fit(X_train, y_train)
......阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
模型评估与结果分析
在测试集上评估融合模型的表现,输出详细的分类指标:
from sklearn.metrics import classification_report
y_pred = final_pipeline.predict(X_test)
print(classification_report(y_test, y_pred, target_names=raw_news.target_names))下图直观展示了整个管道的构建流程:
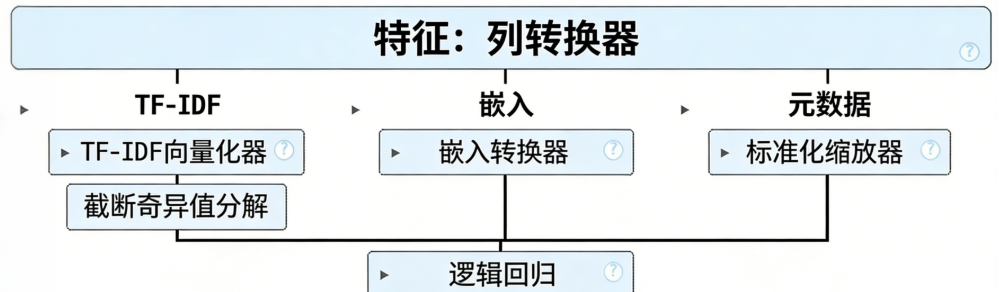
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
结语
本文详细阐述了如何在 Scikit-learn 中融合大语言模型嵌入、TF-IDF 统计特征与结构化元数据,构建一个统一、高效的文本分类管道。通过 ColumnTransformer 与 Pipeline 的巧妙组合,我们不仅避免了繁琐的手动特征拼接,还确保了交叉验证、超参数搜索等环节的严谨性。这种多源信息融合的思路可以广泛推广到各类实际业务场景,例如用户评论分析、工单分类、舆情监控等。希望本文能为您的机器学习项目提供一些有价值的参考。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载
2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载 Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据
Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据 Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据
Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据

