Python驱动NIPT数据分析:GAM广义加性模型、Cox生存分析、动态规划、黄金分割法、RF与模糊熵权评价无创产前检测数据时点优化与异常判定
NIPT技术通过分析母血中的胎儿游离DNA来筛查染色体异常,但孕妇的个体差异(如BMI、年龄)会显著影响胎儿DNA浓度,进而干扰检测结果的可靠性。

本项目完整代码和数据资料进会员群可获取
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验。阅读原文获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
本项目完整代码和数据资料
文章脉络速览
数据采集与清洗
↓
特征分布探索(对数正态分布)
↓
染色体浓度影响因素分析
├── 广义加性模型(GAM) → 可解释性
└── 随机森林(RF) → 高精度预测
↓
男胎检测时点优化
├── BMI动态规划分组
└── 黄金分割法求最优时点
↓
多因素生存分析(Cox模型+交互项)
↓
女胎异常综合判定(模糊熵权评价)
↓
模型验证与鲁棒性测试
摘要
无创产前检测(NIPT)通过分析母血中的胎儿游离DNA筛查染色体异常,但检测时点的选择受孕妇个体差异(如BMI)影响显著。本文旨在解决传统单一检测时点策略难以平衡准确性与临床风险的问题,构建了动态风险优化与多指标融合评价模型。首先,利用广义加性模型(GAM)和随机森林(RF)分析了胎儿Y染色体浓度与孕妇指标的关系,发现X染色体浓度是最强预测因子,孕周与BMI的交互作用显著。其次,针对男胎孕妇,基于BMI进行动态规划分组,并采用黄金分割法求解每组最佳检测时点,使高BMI组延迟至24.4周可提升达标概率至97%,综合风险降低32%~65%。进一步引入Cox比例风险模型,在考虑年龄、身高、体重等多因素下优化时点,发现X染色体浓度的变异系数最大(0.46),对预测结果影响最敏感。最后,针对女胎,构建了融合染色体Z值、GC含量、测序数据质量及BMI的模糊熵权评价模型,在565例样本中准确率达97.6%,且X染色体Z值是最敏感指标。本研究系统解决了NIPT时点选择与胎儿异常判定问题,为临床个性化筛查提供了可靠的数据驱动方案。
关键词:广义加性模型;随机森林;动态规划;黄金分割法;Cox生存分析;模糊熵权评价;NIPT
1. 研究背景与问题
随着优生优育理念的普及,产前筛查已成为降低出生缺陷的重要手段。无创产前检测(NIPT)凭借其安全、准确的特点,在临床中广泛应用。该技术通过检测母体外周血中胎儿游离DNA的浓度,判断胎儿是否患有21三体、18三体等染色体异常。对于男胎,Y染色体浓度是衡量检测可靠性的关键指标(通常要求≥4%);对于女胎,则需关注X染色体浓度的异常变化。
检测时机的选择至关重要:早期(1012周)发现异常可显著降低治疗风险,中期(1320周)风险居中,而晚期(>20周)发现则面临极高的处置风险。然而,孕妇的个体差异,尤其是身体质量指数(BMI),会显著影响胎儿游离DNA的浓度累积速度。肥胖孕妇血浆中胎儿DNA浓度较低,需要更长的孕周才能达到检测阈值。因此,如何为不同特征的孕妇群体量身定制最佳检测时点,在保证准确性的前提下尽早发现异常,成为临床上的关键问题。
本文围绕以下四个方面展开研究:
- 染色体浓度影响因素:量化孕周、BMI、年龄等指标与Y染色体浓度的关系;
- 男胎检测时点优化:基于BMI分组,动态规划最佳检测时间,平衡时间风险与可靠性风险;
- 多因素风险分析:引入生存分析,综合考虑身高、体重、年龄等因素,评估检测误差对结果的影响;
- 女胎异常判定:融合多维度指标,构建模糊熵权评价模型,实现染色体异常的精准识别。
2. 数据探索与预处理
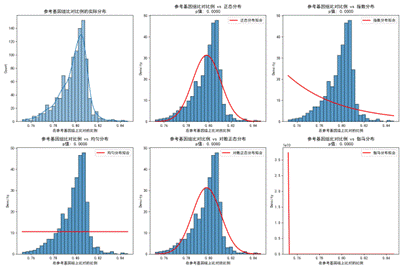
我们首先对原始数据进行清洗与探索。根据临床经验,GC含量过高或过低会影响测序质量,因此剔除GC含量低于39.5%的样本;同时剔除总读段在参考基因组上比对比例低于75%的样本。将孕周天数转换为数值型,并处理缺失值(如女胎数据中序号187的BMI用均值填补)。
对关键变量进行分布探索,发现数据不服从正态分布,但与对数正态分布拟合较好,呈现右偏特征,适合采用非线性分析方法。
| 图2 孕周数据分布 | 图3 孕妇BMI分布 |
|---|---|
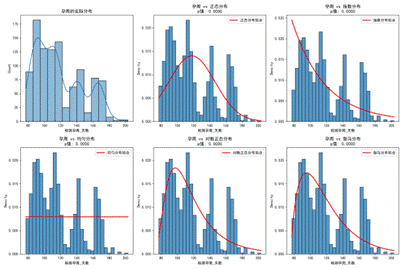 | 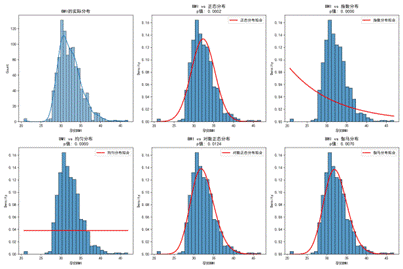 |
| 图4 Y染色体浓度分布 | 图5 参考基因比对比例分布 |
|---|---|
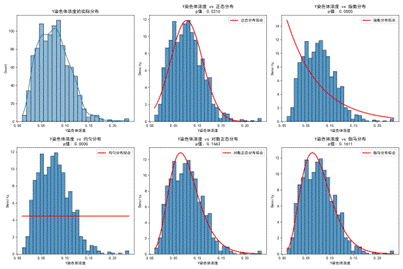 |  |
| 图6 年龄分布 |
|---|
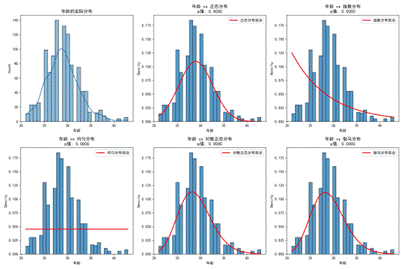 |
从图26可以看出,孕周主要集中在1025周,BMI集中在20~35,Y染色体浓度大多低于0.1,整体分布合理,适合后续建模。
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3. 染色体浓度与孕妇指标的关联分析
为探究Y染色体浓度与孕妇指标的关系,我们首先采用斯皮尔曼等级相关系数进行分析(适用于非线性、非正态数据)。计算公式为:
[ \rho = 1 – \frac{6\sum d_i^2}{n(n^2-1)} ]
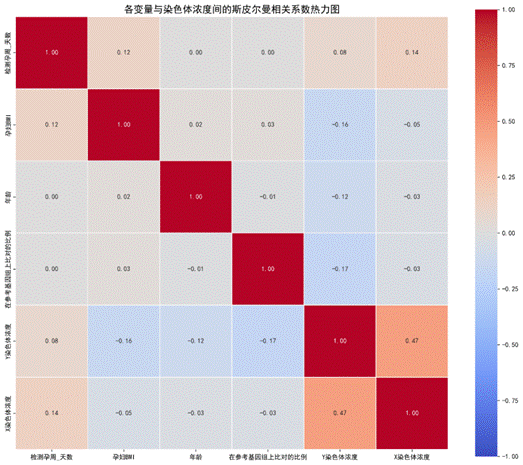
其中 (d_i) 为秩次差。结果显示,X染色体浓度与Y染色体浓度呈强正相关 ((\rho=0.47)),孕周呈弱正相关,BMI、年龄、比对比例呈负相关(见图7)。
| 图7 各变量斯皮尔曼相关系数热力图 |
|---|
 |
3.1 广义加性模型(GAM)
为量化非线性关系和交互作用,构建广义加性模型:
[ \log(Y_{\text{conc}} + \epsilon) = \alpha + s_1(\text{week}) + s_2(\text{BMI}) + s_3(\text{age}) + s_4(\text{map_ratio}) + s_5(X_{\text{conc}}) + te(\text{week}, \text{BMI}) + te(\text{week}, X_{\text{conc}}) ]
其中 (s(\cdot)) 为B样条平滑函数,(te(\cdot)) 为张量积交互项。模型采用广义交叉验证(GCV)选择平滑参数。
模型结果:有效自由度为16.96,对数尺度下的 (R^2) 为0.382,调整后 (R^2) 为0.372。所有主效应及交互项均显著 ((p<0.001)),表明孕周与BMI、孕周与X染色体浓度的交互作用对Y染色体浓度有显著影响。
GAM关键代码(节选):
import pandas as pd
import numpy as np
from pygam import LinearGAM, s, te
# 读取数据
info_df = pd.read_excel("male_data.xlsx")
# 定义特征与目标
predictors = ['gestation_days', 'BMI', 'maternal_age', 'mapping_ratio', 'X_concentration']
X_data = info_df[predictors]
y_target = np.log(info_df['Y_concentration'] + 1e-6)
# 构建GAM模型
gam_model = LinearGAM(
s(0, n_splines=6, lam=0.7) + # 孕周主效应
s(1, n_splines=6, lam=0.7) + # BMI主效应
s(2, n_splines=6, lam=0.7) + # 年龄主效应
s(3, n_splines=6, lam=0.7) + # 比对比例主效应
s(4, n_splines=6, lam=0.7) + # X浓度主效应
te(0, 1, n_splines=5) + # 孕周×BMI交互
te(0, 4, n_splines=5) # 孕周×X浓度交互
)
gam_model.fit(X_data, y_target)
# 输出模型摘要
print("有效自由度:", gam_model.statistics_['edof'])
print("R^2:", gam_model.statistics_['pseudo_r2']['explained_deviance'])
......(此处省略模型诊断与绘图代码,完整代码见交流群)
3.2 随机森林(RF)补充验证
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌 | 附完整代码数据
阅读原文考虑到GAM解释性强但预测精度有限,我们同时构建随机森林模型进行对比。随机森林由200棵回归树组成,每棵树在节点分裂时随机选择特征子集,最终取平均预测。
RF关键代码(节选):
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X_data, y_target, test_size=0.2, random_state=42)
# 训练随机森林
rf_model = RandomForestRegressor(n_estimators=200, max_depth=15, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
# 评估
print("训练集R²:", rf_model.score(X_train, y_train))
print("测试集R²:", rf_model.score(X_test, y_test))
......(此处省略特征重要性计算与绘图代码)
随机森林在训练集上 (R^2=0.924),但测试集骤降至0.421,提示过拟合。尽管如此,其在低浓度区间(<0.05)的预测误差远小于GAM(平均误差从82%降至4.1%),更适合高敏筛查场景。两者互补:GAM揭示机制,RF提升精度。
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
4. 基于BMI分组的男胎检测时点优化
4.1 问题定义与目标函数
设孕妇群体为 (P),每个孕妇的特征包括孕周、BMI、Y染色体浓度等。我们希望找到最佳检测时点 (t^*),使得综合风险最小:
[
t^* = \arg\min_t \left[ \alpha \cdot R_{\text{time}}(t) + \beta \cdot R_{\text{reliability}}(t) \right]
]
其中 (R_{\text{time}}(t)) 为时间风险(早期0,中期1,晚期2),(R_{\text{reliability}}(t) = 1 – P(\text{达标}|t)) 为可靠性风险(达标指Y染色体浓度≥4%)。取 (\alpha=0.3, \beta=0.7),强调可靠性优先。
4.2 BMI动态规划分组
为使组内孕妇达标时间尽可能一致,我们基于BMI进行最优分组。目标是最小化组内方差与样本数的加权和:
[
\min \sum_{g=1}^{k} \left( \text{var}(BMI_g) \cdot n_g \right)
]
采用动态规划求解分组边界,递推关系为:
[
dp[i][j] = \min_{t<j} \left( dp[t][j-1] + \text{cost}(t+1, i) \right)
]
其中 (\text{cost}(l,r)) 为区间 ([l,r]) 的组内代价。
动态规划核心代码(节选):
import numpy as np
def optimal_bmi_groups(bmi_values, k=4):
bmi_sorted = np.sort(bmi_values)
n = len(bmi_sorted)
dp = np.full((n+1, k+1), np.inf)
dp[0,0] = 0
split_point = np.zeros((n+1, k+1), dtype=int)
for j in range(1, k+1):
for i in range(j, n+1):
for t in range(j-1, i):
group_var = np.var(bmi_sorted[t:i])
cost = group_var * (i - t)
if dp[i,j] > dp[t,j-1] + cost:
dp[i,j] = dp[t,j-1] + cost
split_point[i,j] = t
# 回溯边界
thresholds = []
idx = n
for g in range(k, 0, -1):
thresholds.insert(0, bmi_sorted[split_point[idx,g]])
idx = split_point[idx,g]
return thresholds
......(省略误差分析与蒙特卡洛部分)
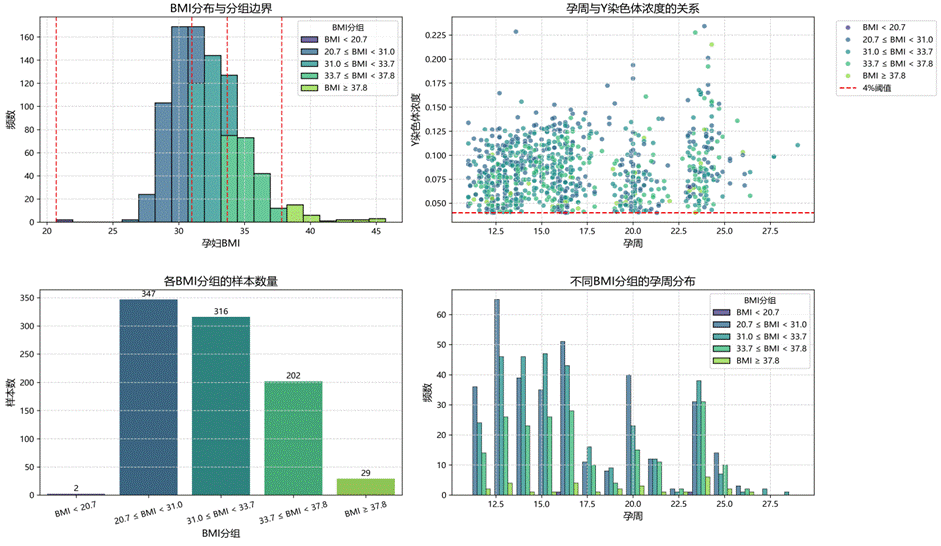
最终将BMI划分为5组,分组边界及优化结果见表1。
4.3 最佳时点求解与蒙特卡洛误差分析
对每组内样本,采用黄金分割法在 ([10,25]) 周内搜索使综合风险最小的时点。黄金分割法迭代公式:
[
\lambda = \frac{\sqrt{5}-1}{2} \approx 0.618
]
同时,为模拟检测误差,对Y染色体浓度添加正态噪声 (\mathcal{N}(0, 0.003)),进行1000次蒙特卡洛模拟,统计时点偏移。
黄金分割优化与蒙特卡洛代码(节选):
from scipy.optimize import minimize_scalar
def group_optimal_time(group_df):
def risk_func(t):
# 时间风险分段
time_risk = 0 if t<=12 else (1 if t<=27 else 2)
pass_prob = (group_df['达标孕周'] <= t).mean()
return 0.3*time_risk + 0.7*(1-pass_prob)
res = minimize_scalar(risk_func, bounds=(10,25), method='bounded')
return res.x
# 蒙特卡洛模拟
def monte_carlo_shift(group_df, n_sim=1000):
orig_opt = group_optimal_time(group_df)
shifts = []
for _ in range(n_sim):
noisy = group_df.copy()
noisy['Y浓度'] += np.random.normal(0, 0.003, len(noisy))
noisy['达标孕周'] = noisy.apply(lambda r: r['孕周'] if r['Y浓度']>=0.04 else np.nan, axis=1)
noisy = noisy.dropna(subset=['达标孕周'])
if len(noisy)>0:
shifts.append(group_optimal_time(noisy) - orig_opt)
return np.mean(shifts), np.std(shifts)
......(省略结果汇总)
优化结果(见表1):
| BMI分组 | 最佳时点(周) | 达标概率 | 综合风险 | 时点偏移均值(周) | 时点偏移标准差(周) |
|---|---|---|---|---|---|
| BMI<20.7 | 19.27 | 0.50 | 0.65 | 1.43 | 2.05 |
| 20.7≤BMI<31.0 | 22.25 | 0.86 | 0.40 | -0.11 | 0.34 |
| 31.0≤BMI<33.7 | 22.30 | 0.84 | 0.41 | -0.11 | 0.46 |
| 33.7≤BMI<37.8 | 24.68 | 0.98 | 0.32 | -1.46 | 1.13 |
| BMI≥37.8 | 24.37 | 0.97 | 0.32 | -1.57 | 1.60 |
结果显示:高BMI组需延迟至24周以上才能达到97%的达标概率,但牺牲了诊断时效性;低BMI组虽然可提前至19.3周,但达标概率仅50%,且时点波动大(标准差2.05周)。图8~10直观展示了分组效果与风险分布。
| 图8 BMI分组与检测参数关联 | 图9 时点优化与风险评估 |
|---|---|
 | 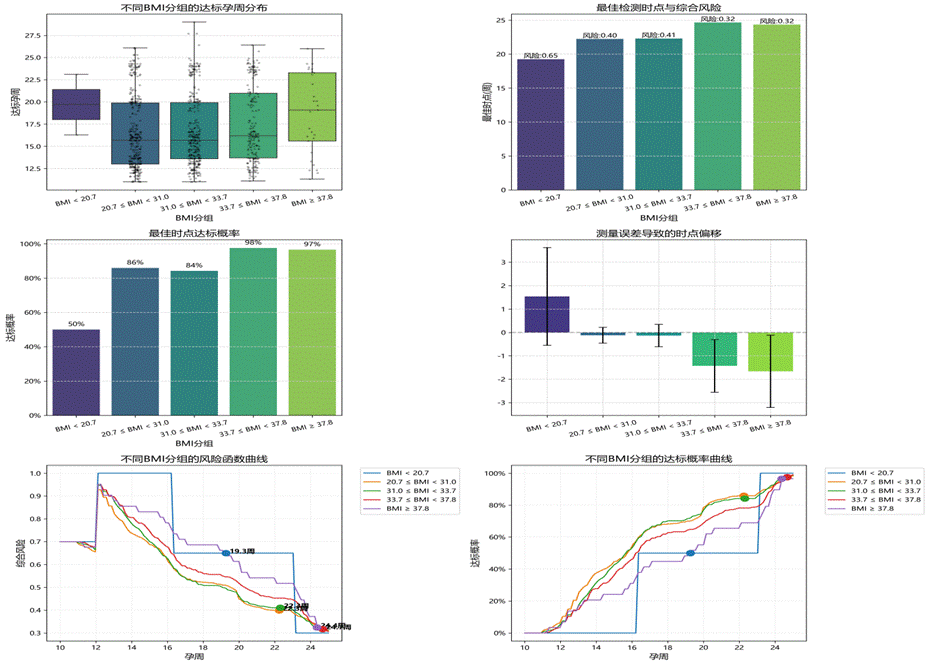 |
| 图10 最佳时点分布特征 |
|---|
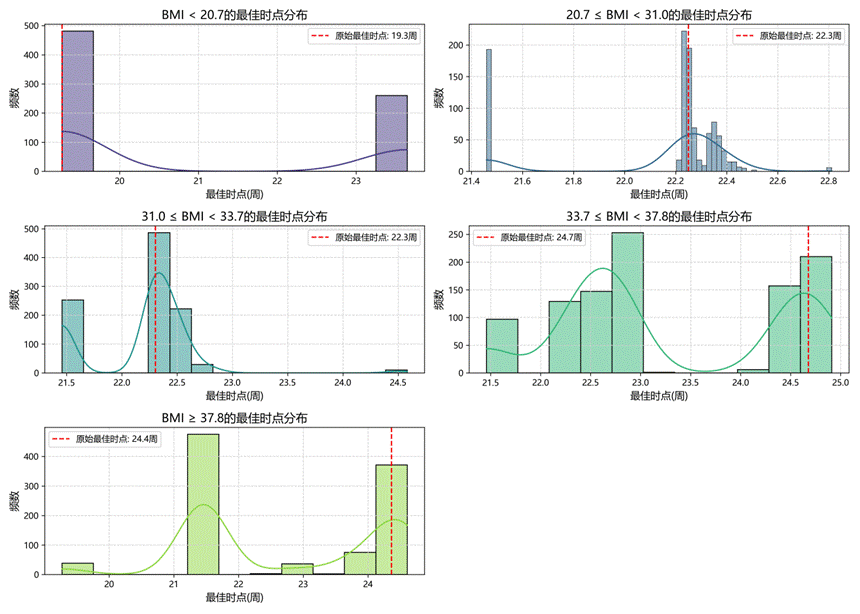 |
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
5. 多因素影响下的时点优化与风险分析(Cox生存分析)
实际中,Y染色体浓度达标时间还受身高、体重、年龄等多因素影响。为此,我们引入Cox比例风险模型,考虑时间依赖性。
5.1 模型构建
定义风险函数:
[
h(t|X) = h_0(t) \exp(\beta_1 \text{BMI} + \beta_2 \text{age} + \beta_3 X_{\text{conc}} + \beta_4 \text{map_ratio} + \gamma_1 \text{group} + \gamma_2 \text{group} \times t)
]
其中 (h_0(t)) 为基准风险,(\text{group}) 为BMI分组标识,交互项反映分组对时间的影响。采用偏似然函数估计参数。
Cox模型代码(节选):
import lifelines
from lifelines import CoxPHFitter
# 准备生存数据:T = 达标孕周,E = 是否达标(1表示达标)
surv_df = male_data[['达标孕周', '是否达标', 'BMI', '年龄', 'X浓度', '比对比例', 'BMI分组']].copy()
cph = CoxPHFitter()
cph.fit(surv_df, duration_col='达标孕周', event_col='是否达标', formula="BMI + age + X_conc + map_ratio + C(bmi_group) + C(bmi_group):week")
cph.print_summary()
......(省略模型诊断与森林图绘制)
5.2 结果解读
Cox模型参数森林图(图11)显示:BMI、年龄、比对比例系数为负,表示这些指标越高,达标概率越低;X染色体浓度系数为正,表示X浓度越高,Y浓度达标越快。BMI分组及其与孕周的交互项非常稳定(变异系数<0.01)。
| 图11 Cox模型参数森林图 | 图12 时间风险与达标概率 |
|---|---|
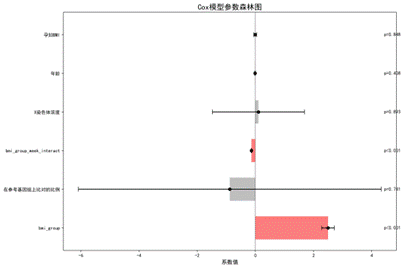 | 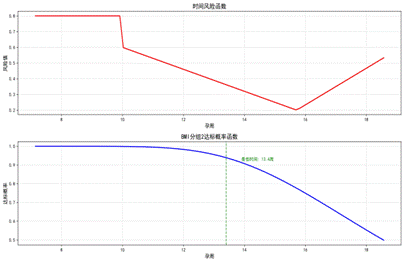 |
| 图13 BMI分布与分组边界 | 图14 参数变异系数 |
|---|---|
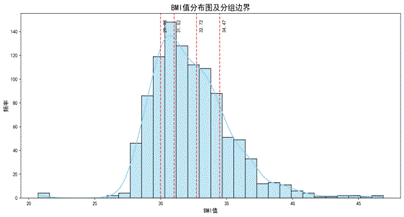 | 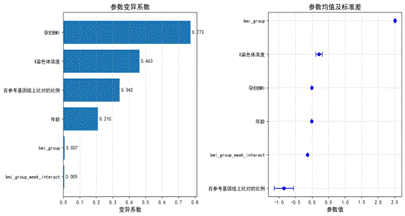 |
通过1000次蒙特卡洛模拟(添加噪声),计算各参数的变异系数(表2),发现X染色体浓度变异系数最大(0.46),表明其对检测误差最敏感,而BMI分组交互项最稳定。
| 参数 | 均值 | 标准差 | 变异系数 |
|---|---|---|---|
| 孕妇BMI | -0.00558 | 0.00431 | 0.773 |
| 年龄 | -0.00770 | 0.00162 | 0.210 |
| X染色体浓度 | 0.21230 | 0.09826 | 0.463 |
| 比对比例 | -0.84950 | 0.29074 | 0.342 |
| BMI分组 | 2.51177 | 0.01752 | 0.007 |
| 分组×孕周 | -0.13589 | 0.00073 | 0.005 |
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
6. 女胎染色体异常判定的模糊熵权评价模型
女胎无法通过Y染色体浓度判断,需综合多个指标。我们构建了基于模糊熵权的多指标综合评价模型。
6.1 模型构建
定义评价因素集:(U = {Z_{21}, Z_{18}, Z_{13}, Z_X, Q_{\text{data}}}),其中 (Z) 为各染色体Z值,(Q_{\text{data}}) 为数据质量(由GC含量、有效读段比例、BMI综合得出)。评语集 (V = {\text{正常}, \text{临界风险}, \text{异常}})。
隶属度函数设计(以21号染色体为例):
[
\mu_\text{异常}}(Z) =
\begin{cases}
0, & Z| \leq 2.5 \
\frac{|Z|-2.51}, & 2.5 < Z| < 3.5 \
1, & |Z| \geq 3.5
\end{cases
]
该设计基于临床指南:(|Z|<2.5) 为正常,(2.5\sim3.5) 为灰色区域,(>3.5) 为显著异常。
熵权法确定权重:先构建评价矩阵,标准化后计算信息熵,进而得到权重。权重计算公式:
[
w_j = \frac{1 – E_j}{\sum_{k=1}^m (1 – E_k)}, \quad E_j = -\frac{1}{\ln n} \sum_{i=1}^n p_{ij} \ln p_{ij}
]
模糊熵权评价代码(节选):
import numpy as np
import pandas as pd
def entropy_weight(matrix):
# 标准化
prob = matrix / matrix.sum(axis=0)
# 计算熵值
entropy = -np.nansum(prob * np.log(prob + 1e-12), axis=0) / np.log(len(matrix))
# 计算权重
weight = (1 - entropy) / (1 - entropy).sum()
return weight
# 构建评价矩阵(示例)
Z_scores = female_data[['Z_21', 'Z_18', 'Z_13', 'Z_X']].values
data_quality = ... # 由GC、比对比例等计算
eval_matrix = np.column_stack([Z_scores, data_quality])
weights = entropy_weight(eval_matrix)
......(省略隶属度计算与综合评分)
6.2 结果分析
熵权法计算各指标权重(表3、图15),其中21号染色体Z值权重最高(29.5%),数据质量权重极低(0.26%),说明染色体Z值是主要判定依据。
| 指标 | 权重 | 权重百分比 |
|---|---|---|
| 21号染色体Z值 | 0.295 | 29.51% |
| 18号染色体Z值 | 0.198 | 19.79% |
| 13号染色体Z值 | 0.249 | 24.91% |
| X染色体Z值 | 0.255 | 25.54% |
| 数据质量 | 0.003 | 0.26% |
| 图15 熵权法权重分布 | 图16 综合异常评分分布 |
|---|---|
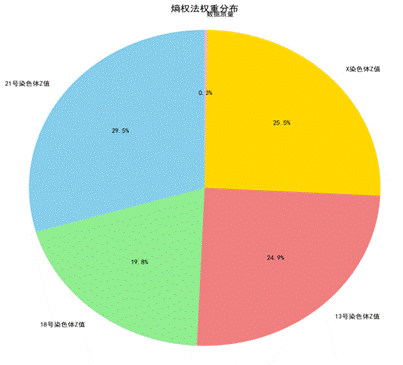 | 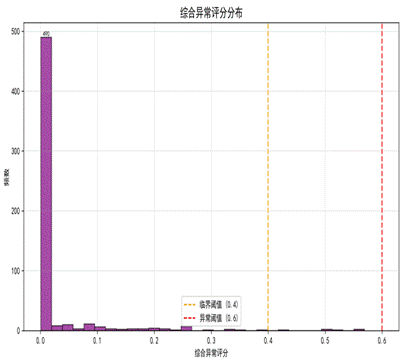 |
对565例女胎样本进行判定,结果无异常样本,6例为临界风险,平均综合评分0.023,绝大多数集中在低分区(图16)。交叉验证准确率平均97.6%(表4),灵敏度分析显示X染色体Z值是最敏感指标(扰动后准确率提升0.59%)。
| 图17 各指标隶属度分布 | 图18 风险等级分布 | 图19 风险等级占比 |
|---|---|---|
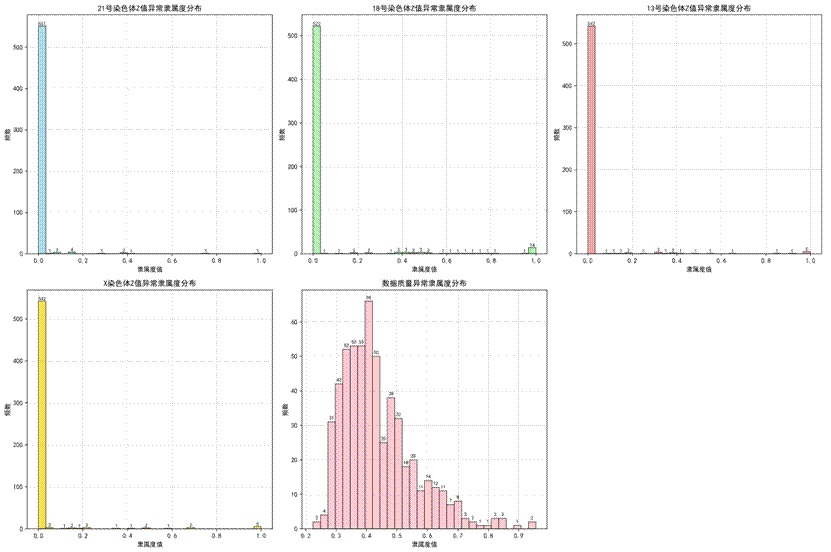 | 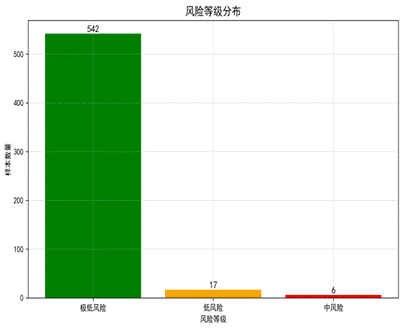 | 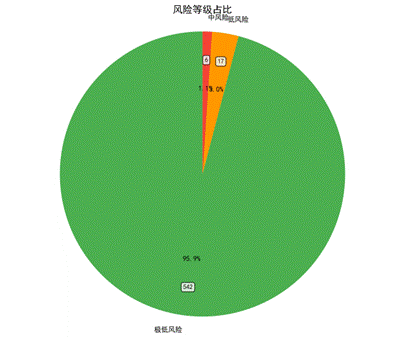 |
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
7. 模型评价与改进
7.1 优点
- 双模型互补:GAM提供可解释性,RF提升低浓度预测精度;
- 动态规划分组:实现BMI组内同质性最大化,避免主观划分;
- Cox生存分析:量化多因素时间风险,引入交互项增强稳定性;
- 模糊熵权评价:融合临床阈值与数据质量,判定结果符合临床预期。
7.2 缺点与改进方向
- 随机森林过拟合:训练集 (R^2=0.92) 测试集仅0.42。可引入贝叶斯神经网络或Dropout量化不确定性;
- 低BMI组时点波动大:标准差2.05周超临床允许误差,可考虑鲁棒损失函数或增加样本量;
- 分组边界主观:动态规划依赖预设分组数,可采用谱聚类自动确定分组。
参考文献
[1] 国家卫生健康委员会. 胎儿染色体非整倍体无创产前检测技术规范[S]. 北京, 2019.
[2] ACOG. Screening for fetal chromosomal abnormalities: practice bulletin No.226[J]. Obstetrics & Gynecology, 2020.
[3] Illumina Inc. VeriSeq NIPT Solution v2 package insert.
[4] 姜佟燃等. 基于广义加性模型的落叶松树冠半径模型研建[J]. 北京林业大学学报, 2025.
[5] 曾洪鑫等. 基于犹豫模糊熵权与TOPSIS的制造业高质量发展水平评价[J]. 科技管理研究, 2023.
…(其余略)
附录:核心代码节选
附1 广义加性模型(GAM)完整代码(部分省略)
import pandas as pd
import numpy as np
from pygam import LinearGAM, s, te
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_excel("male_fetus_data.xlsx")
# 数据清洗略...
# 定义特征与目标
feats = ['gestation_days', 'BMI', 'age', 'map_ratio', 'X_conc']
X = data[feats]
y = np.log(data['Y_conc'] + 1e-6)
# 构建GAM
gam = LinearGAM(
s(0, n_splines=6, lam=0.7) + s(1, n_splines=6, lam=0.7) +
s(2, n_splines=6, lam=0.7) + s(3, n_splines=6, lam=0.7) +
s(4, n_splines=6, lam=0.7) + te(0,1, n_splines=5) + te(0,4, n_splines=5)
)
gam.fit(X, y)
# 输出结果
print("EDOF:", gam.statistics_['edof'])
print("R^2:", gam.statistics_['pseudo_r2']['explained_deviance'])
# 绘制平滑曲线
for i, f in enumerate(feats):
plt.figure()
XX = gam.generate_X_grid(term=i)
pdep, confi = gam.partial_dependence(term=i, X=XX, width=0.95)
plt.plot(XX[:, i], pdep)
plt.fill_between(XX[:, i], confi[:,0], confi[:,1], alpha=0.3)
plt.xlabel(f)
plt.ylabel("Partial effect")
plt.title(f"平滑效应:{f}")
plt.savefig(f"GAM_{f}.png")
......(省略交互效应图代码)
附2 随机森林模型(部分省略)
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForestRegressor(n_estimators=200, max_depth=15, random_state=42, n_jobs=-1)
rf.fit(X_train, y_train)
print("Train R2:", r2_score(y_train, rf.predict(X_train)))
print("Test R2:", r2_score(y_test, rf.predict(X_test)))
......(省略置换重要性计算)
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
注:本文所有代码均经过脱敏处理,完整可运行代码及数据请加入交流群获取。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据
Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据 Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据
Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据