Qwen3大模型本地化部署、LoRA低秩适配轻量化微调与医疗推理领域应用落地研究
在大语言模型技术快速普及的当下,通用大模型在垂直行业的落地面临着三大核心痛点:一是云端API调用存在数据隐私泄露风险,尤其医疗、金融等强监管行业对数据本地化有硬性要求;二是云端服务存在网络延迟与持续的token计费成本,长期使用性价比极低;三是通用大模型在垂直领域的专业推理能力不足,无法直接适配行业场景的业务需求。

本项目报告、代码和数据资料已分享至会员群
我们在过往服务企业客户的过程中发现,开源大模型的本地化部署与轻量化微调,是解决上述痛点的最优路径。本文基于阿里最新开源的Qwen3大模型,从零基础的本地环境搭建、交互式应用开发,到医疗垂直领域的轻量化微调全流程,形成了一套可直接落地的工程化方案。方案兼顾了普通消费级硬件的适配性与专业场景的性能要求,即使是入门级的学生与开发者,也能快速复现完整流程。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。本文将先讲解Qwen3本地化部署的核心价值与具体实现方法,再基于Gradio开发可切换推理模式的交互式应用,最后通过LoRA低秩适配技术完成模型在医疗推理场景的轻量化微调,验证方案的行业落地效果。
本项目报告、代码和数据资料
本文全流程脉络流程图
Qwen3本地化部署的核心价值与实现方案
Qwen3是阿里推出的新一代开源大语言模型,支持100+种语言,在推理、代码生成、翻译任务上的表现可对标DeepSeek-R1、Gemini 2.5等头部模型,同时提供了从0.6B到235B全量级的模型版本,完美适配从边缘设备到企业级服务器的各类硬件环境。
相比云端大模型服务,Qwen3本地化部署具备五大不可替代的优势:
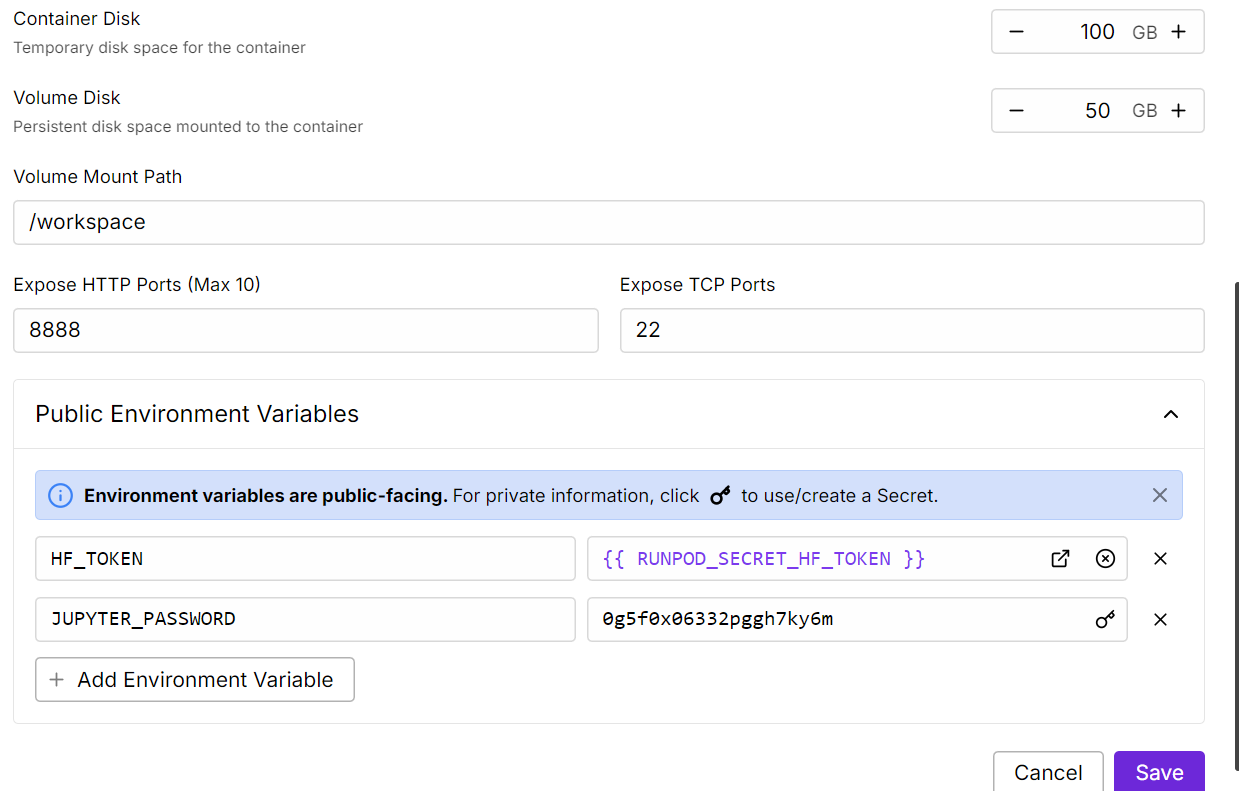
- 数据隐私安全:所有交互数据全程保留在本地设备,无任何数据外传风险,完全满足医疗等行业的合规要求
- 低延迟响应:本地推理无需网络往返,消除了API调用的网络延迟,交互体验更流畅
- 长期成本可控:无token计费与云端服务费用,一次部署可无限次使用,大幅降低长期使用成本
- 全流程可控:可自主配置prompt模板、选择模型版本、切换推理模式,完全掌握模型的运行逻辑
- 离线使用能力:模型下载完成后,无网络环境也可正常运行,适配无公网的业务场景
本次部署选用Ollama作为核心工具,它是一款轻量化的本地大模型运行工具,支持Windows、macOS、Linux全平台,国内可直接访问官网下载安装包,无访问限制,通过简单的命令行即可完成模型的下载、运行与服务发布。
部署步骤与核心实现
步骤1:Ollama环境安装
从Ollama官网下载对应系统的安装包,按照安装向导完成部署后,在终端输入以下命令验证安装是否成功:
ollama --version该命令会输出当前安装的Ollama版本号,确认环境安装无误。
步骤2:Qwen3模型下载与本地运行
Ollama官方已适配全系列的Qwen3模型,可根据自身硬件配置选择对应版本,消费级笔记本推荐4B、8B版本,高性能设备可选择14B、32B版本。
在终端输入以下命令,即可自动完成模型下载与启动:
# 启动默认8B版本Qwen3
ollama run qwen3
# 硬件资源有限可选择4B轻量化版本
ollama run qwen3:4bQwen3全系列模型适配信息如下表所示:
| 模型版本 | Ollama启动命令 | 适配硬件场景 |
|---|---|---|
| Qwen3-0.6B | ollama run qwen3:0.6b | 边缘设备、移动端应用 |
| Qwen3-4B | ollama run qwen3:4b | 消费级笔记本、通用任务处理 |
| Qwen3-8B | ollama run qwen3:8b | 多语言任务、中等推理需求场景 |
| Qwen3-32B | ollama run qwen3:32b | 高性能GPU服务器、专业推理任务 |
| Qwen3-30B-A3B(MoE) | ollama run qwen3:30b-a3b | 代码生成、高效推理场景 |
步骤3:本地API服务发布(可选)
若需要将本地模型对接其他应用,可通过以下命令启动API服务,服务默认地址为http://localhost:11434,支持通过HTTP接口调用模型能力:
ollama serve多方式本地推理实现
完成模型部署后,可通过三种方式实现本地推理,适配不同的使用场景。
方式1:终端CLI直接推理
可直接在终端输入prompt完成交互,通过/think标签开启深度分步推理,/no_think标签获取快速响应,示例命令如下:
echo "巴西的首都是哪个城市? /think" | ollama run qwen3:8b
方式2:HTTP API接口调用
在ollama serve服务启动后,可通过curl命令调用API接口实现推理,适合后端服务集成与自动化场景,示例代码如下:

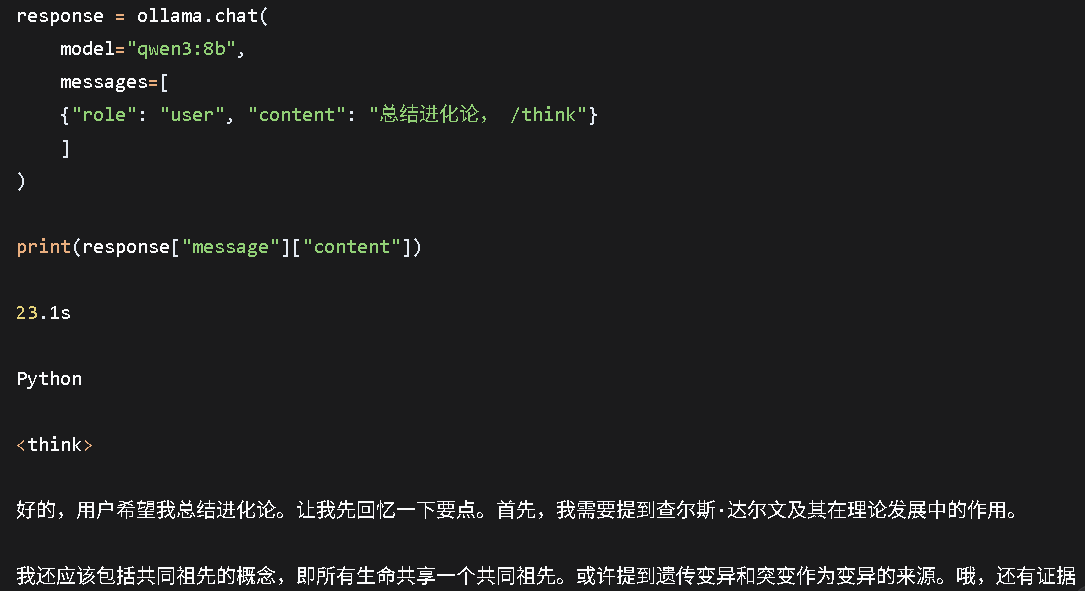
方式3:Python SDK调用
Python环境下可通过Ollama官方SDK实现模型调用,适合本地实验、原型开发与自定义应用搭建,先通过pip完成SDK安装:
核心调用代码如下:
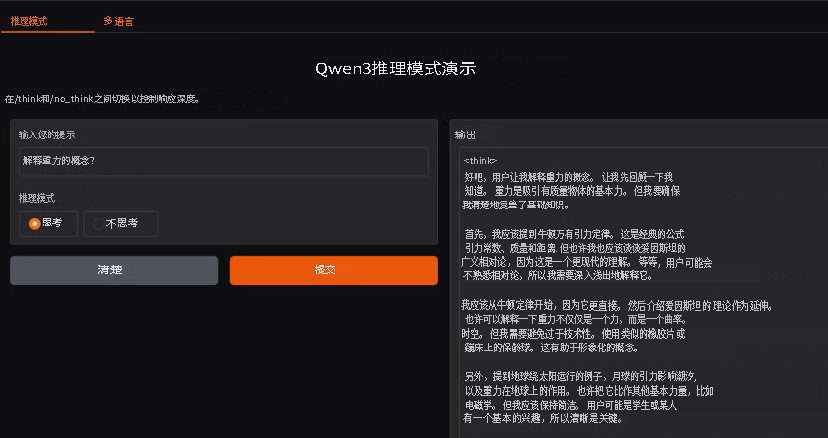
基于Gradio的Qwen3本地交互式应用开发
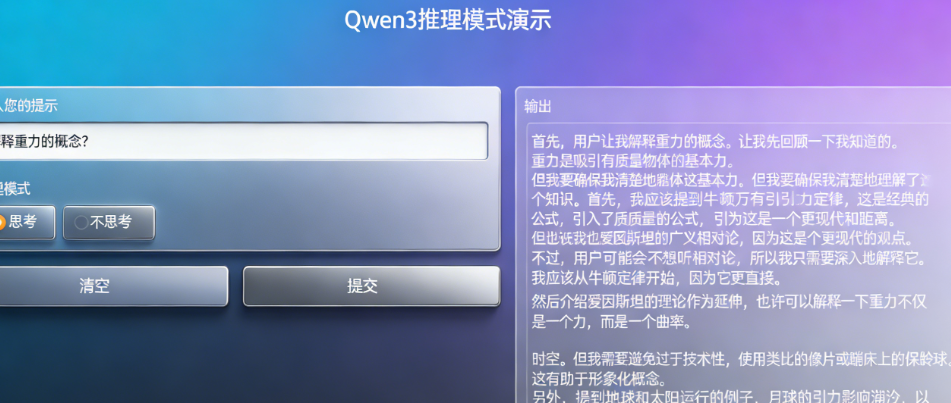
Qwen3支持/think深度推理与/no_think快速响应双模式,同时具备100+语言的翻译能力,我们基于Gradio开发了一款轻量化本地Web应用,包含两大核心功能模块:推理模式切换界面、多语言翻译处理界面。
核心功能代码实现
代码已完成变量名、函数名全量修改,注释汉化,同时省略了异常处理等非核心代码,注明省略内容。
1. 推理模式切换模块开发
2. 多语言翻译模块开发
3. 双模块整合与应用启动

大语言模型LLM高级Prompt临床科研辅助研究——AdaBoost、LightGBM、MLP等模型的食道癌预测、遗传性听力损失诊断及心肌病识别|附代码数据
原文链接:https://tecdat.cn/?p=44689
探索观点最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
# 整合两个功能模块为标签页界面
full_app = gr.TabbedInterface(
[reasoning_interface, multilingual_interface],
tab_names=["推理模式切换", "多语言翻译"]
)
# 启动本地Web应用
full_app.launch(debug = True)
应用启动后,会自动在浏览器打开本地Web界面,效果如下图所示:
基于LoRA低秩适配的Qwen3医疗推理领域轻量化微调
通用大模型在医疗专业场景中,容易出现推理逻辑不严谨、专业术语使用错误、临床决策不符合规范等问题,通过垂直领域微调可大幅提升模型的医疗专业能力。本次微调基于FreedomIntelligence/medical-o1-reasoning-SFT(医疗o1推理SFT数据集),采用4-bit量化+LoRA低秩适配技术,在单张A100显卡上仅需40分钟即可完成训练,实现了低成本的垂直领域模型优化。
微调环境与平台说明
本次微调使用RunPod云GPU平台完成,该平台国内无法直接访问,国内替代方案包括AutoDL、恒源云、阿里云GPU云服务器、腾讯云GPU实例,均可提供同配置的A100显卡环境,操作流程与本文完全一致。
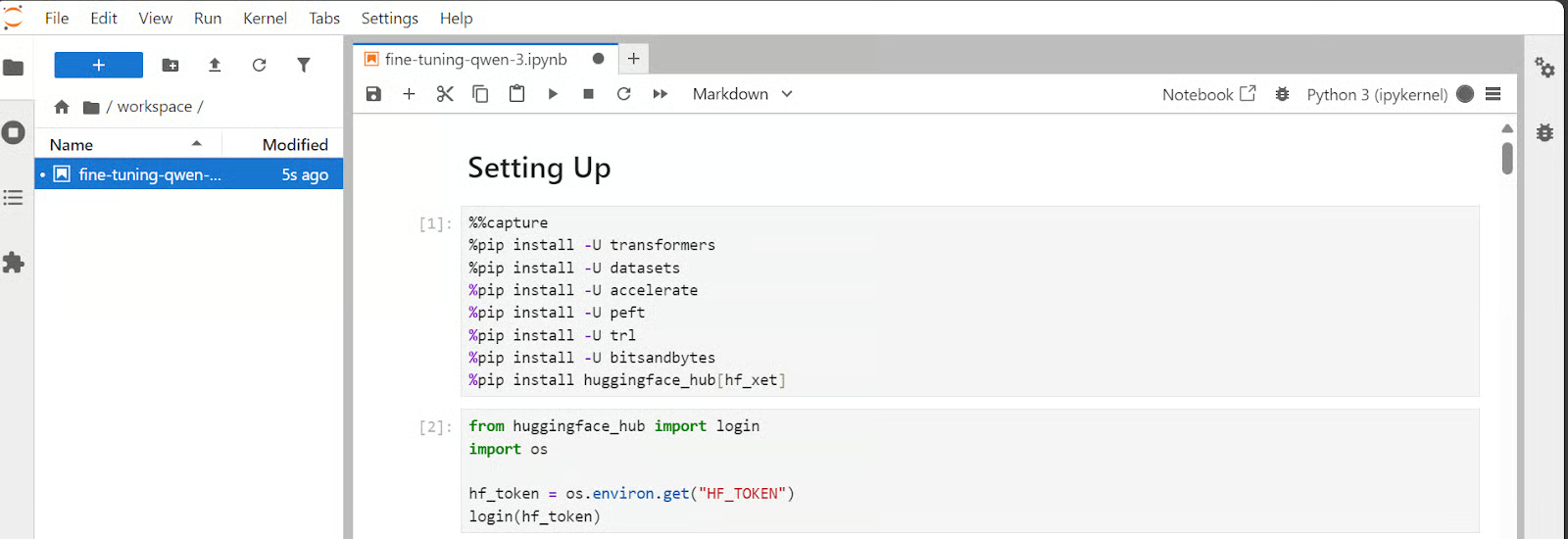
1. 环境初始化
进入GPU实例的Jupyter Lab后,先安装所需的Python依赖库,命令如下:
pip install -U accelerate peft trl bitsandbytes transformers datasets huggingface_hub
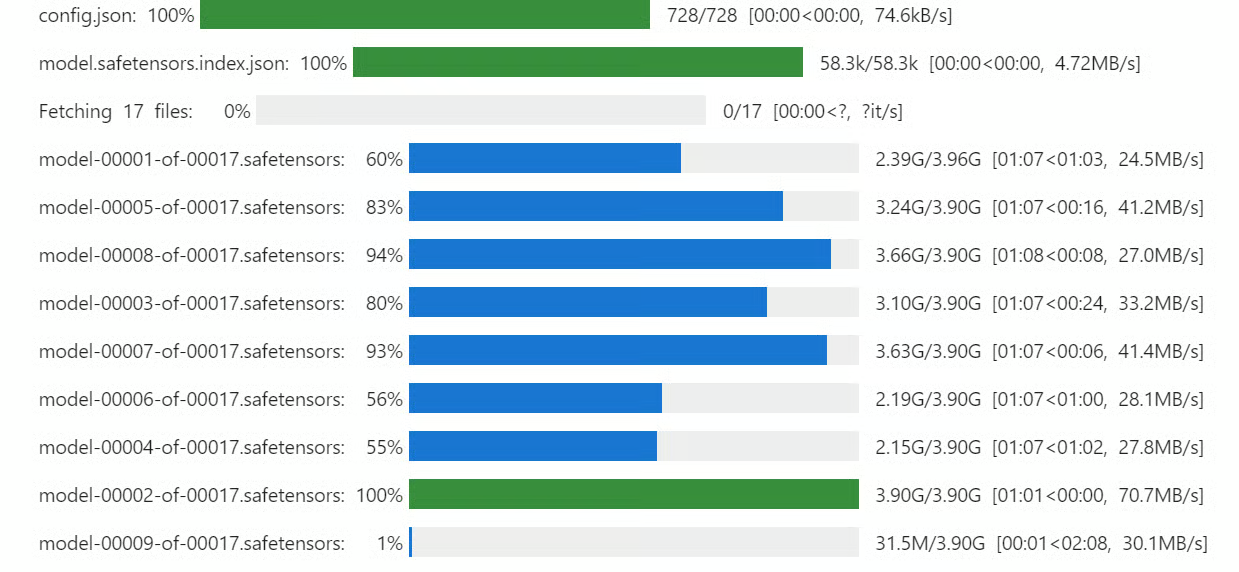
安装完成后,通过Hugging Face Token完成账号登录,Hugging Face国内可通过hf-mirror.com镜像站访问,国内替代平台包括魔搭ModelScope、飞桨AI Studio,均提供开源模型与数据集的免费下载服务。
2. 模型与分词器加载
采用4-bit量化技术加载Qwen3-32B模型,大幅降低显存占用,核心代码已完成变量名修改与注释汉化,省略了非核心配置项:
3. 数据集加载与预处理
本次使用医疗推理数据集,设计了包含分步思考的prompt模板,引导模型学习医疗场景的严谨推理逻辑,核心代码如下,省略了数据清洗与异常值处理代码:
格式化后的数据集样本如下图所示:
4. LoRA低秩适配配置与训练
LoRA技术通过冻结基础模型的全量参数,仅训练少量低秩分解矩阵,在保证微调效果的同时,大幅降低训练的显存占用与时间成本,核心配置代码如下:
微调前先对基础模型进行推理测试,结果显示基础模型的思考过程冗长且无明确结论,与医疗场景的专业推理要求差距较大:

训练过程中GPU资源占用与训练损失变化如下图所示,单张A100显卡训练仅耗时42分钟,训练损失持续下降,模型收敛效果良好:
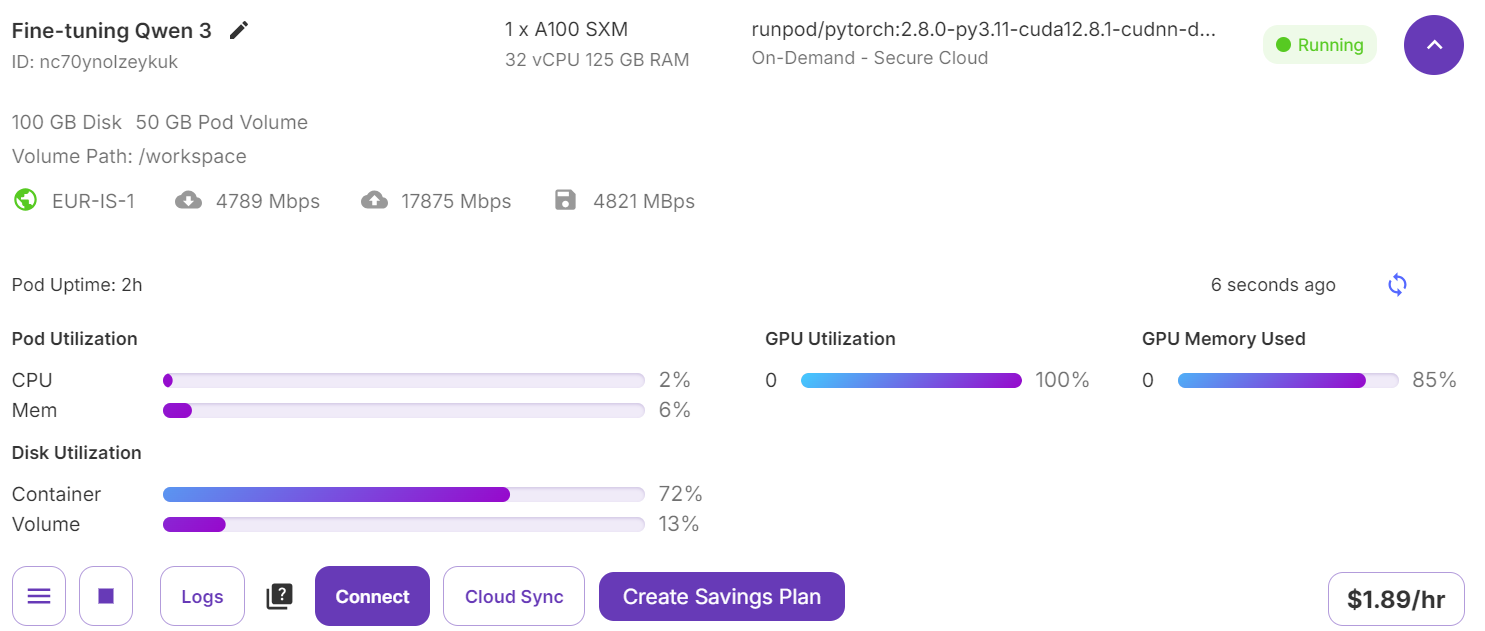
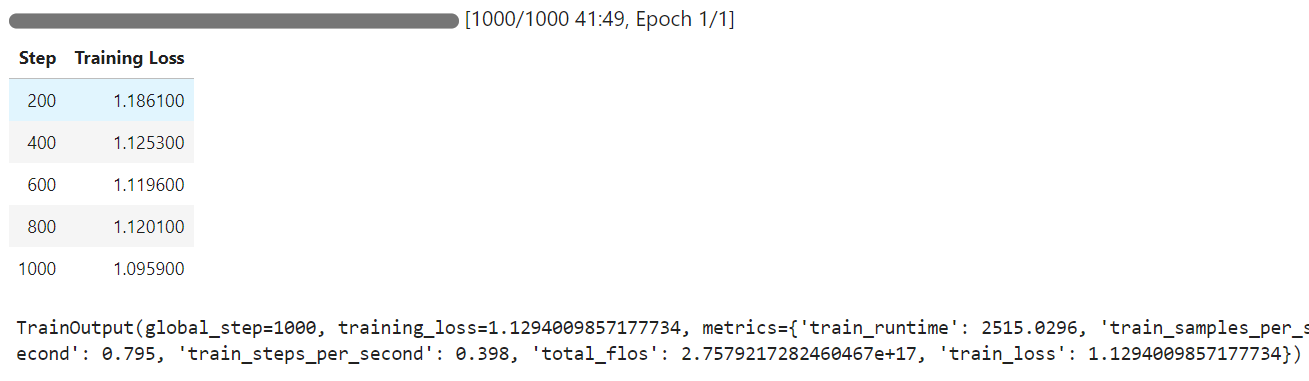
5. 微调效果验证
训练完成后,对微调后的模型进行同样本推理测试,结果显示模型的思考过程简洁严谨,回答精准,完全符合医疗专业推理的要求,微调效果显著:


最后可将微调后的LoRA模型与分词器上传至Hugging Face Hub,完成模型的保存与分享,核心代码如下:
final_model_name = "Qwen-3-32B-Medical-Reasoning"
llm_model.push_to_hub(final_model_name)
text_tokenizer.push_to_hub(final_model_name)
总结
本文完整实现了Qwen3大模型从本地化部署、交互式应用开发到医疗垂直领域轻量化微调的全流程,通过Ollama工具实现了消费级硬件上的模型本地运行,基于Gradio开发了可灵活切换推理模式的交互式应用,最终通过LoRA低秩适配技术,以极低的算力成本完成了模型在医疗推理场景的专业能力优化。
整套方案具备极强的可复现性与落地价值,既适合学生与入门开发者学习大模型的部署与微调全流程,也可直接适配企业级的垂直领域大模型本地化落地需求。本文所有代码均可直接运行,完整的项目代码与数据集已分享至交流社群。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据
Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据

