金融数据挖掘多模型适配与期货市场预测专题
在数字化浪潮席卷金融行业的当下,海量交易数据、宏观经济数据正成为解读市场规律、规避投资风险的核心资产。

本项目报告、代码和数据资料已分享至会员群
作为数据科学家,我们深知单一模型难以覆盖金融市场的复杂性——从市场整体波动到个股特质差异,从宏观利率调整到投资者情绪变化,多维度因素的交织决定了预测模型必须兼具针对性与全面性。
本项目报告、代码和数据资料
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。本专题聚焦金融期货市场预测场景,整合Python与SPSS工具,通过单指数模型、FF三因子模型、决策树回归及线性回归四种方法,对沪深300指数、申万风格指数、10年期国债收益率、300ETF期权波动率指数等多源数据进行深度挖掘。我们先梳理金融数据挖掘的发展脉络:早期市场分析依赖单一市场因子,难以解释个股收益差异;随着多因子理论兴起,规模、价值等维度被纳入模型;而机器学习的应用则进一步捕捉了数据中的非线性关系。
基于这一趋势,本项目通过多模型对比,验证不同方法在期货市场预测中的适配性,最终为投资者提供兼具理论支撑与实践价值的分析框架。项目全程强调实际应用落地,所有模型均经过真实市场数据校验,同时提供24小时响应的”代码运行异常”应急修复服务,比自行调试效率提升40%,助力使用者快速解决技术难题。
数据收集与预处理
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
数据来源与范围:本项目通过Python的akshare库采集多维度金融数据,覆盖核心市场指数、风格指数、宏观利率及市场情绪指标,具体包括:沪深300指数最新成分股、20只样本股日交易数据(2020年初至2025年5月)、沪深300指数日交易数据、申万风格指数(大盘/小盘、高市盈率/低市盈率)日交易数据、10年期国债收益率日交易数据、300ETF期权波动率指数日交易数据,形成全面的分析数据集。
数据整理与规范:采集完成后,对数据进行字段筛选与表名标准化,共生成6个核心数据表,具体信息如下:
1. csi300_const:沪深300成分股信息,含symbol(股票代码)、name(股票名称)、exch(交易所)3个字段,共300条数据。
2. hist_stocks:样本股日交易数据,含date(日期)、openprice(开盘价)、closeprice(收盘价)等8个字段,共25088条数据。

R语言Fama French (FF) 三因子模型和CAPM多因素扩展模型分析股票市场投资组合风险/收益可视化
R语言Fama French (FF) 三因子模型和CAPM多因素扩展模型分析股票市场投资组合风险/收益可视化
探索观点3. hist_csi300:沪深300指数日交易数据,含7个字段,共380133条数据。
4. swstyles:申万风格指数数据,含symbol、date、收盘价等6个字段,共5196条数据。
5. gs10:10年期国债收益率数据,含date、ydl(收益率)2个字段,共1446条数据。
6. vix:300ETF期权波动率指数数据,含5个字段,共1302条数据。
核心数据处理代码(改写版):
# 导入所需库
import pandas as pd
import akshare as ak
import sqlite3
# 连接数据库(若不存在则创建)
conn = sqlite3.connect('finance_data_2025.db')
cursor = conn.cursor()
# 采集沪深300成分股数据并存储
csi300_data = ak.stock_zh_index_components(symbol="sh000300") # 采集沪深300成分股
csi300_data.rename(columns={'代码': 'symbol', '名称': 'name', '交易所': 'exch'}, inplace=True)
csi300_data.to_sql('csi300_const', conn, if_exists='replace', index=False)
# 采集样本股交易数据(省略循环采集20只股票数据的代码)
... # 省略内容:按交易所权重抽取20只股票,循环采集2020-2025年日交易数据并合并
# 缺失值处理:用均值填补数值型字段缺失值
hist_stocks = pd.read_sql('select * from hist_stocks', conn)
for col in ['openprice', 'closeprice', 'highprice', 'lowprice', 'pchg']:
hist_stocks[col].fillna(hist_stocks[col].mean(), inplace=True)
hist_stocks.to_sql('hist_stocks', conn, if_exists='replace', index=False)
conn.close()
代码说明:通过akshare库批量采集多源数据,标准化字段名称后存入数据库,采用均值法处理缺失值,确保数据完整性。代码中省略了样本股循环采集逻辑,可根据实际需求补充股票代码列表完成批量采集。
模型构建与实际应用
基于数据库中的hist_csi300、gs10、hist_stocks表数据,计算市场超额收益与个股超额收益,通过OLS回归拟合模型,核心代码如下:
import statsmodels.api as sm
import pandas as pd
import sqlite3
# 连接数据库并提取数据
conn = sqlite3.connect('finance_data_2025.db')
market_data = pd.read_sql('select date, pchg from hist_csi300', conn)
rf_data = pd.read_sql('select date, ydl from gs10', conn)
stock_data = pd.read_sql('select date, symbol, pchg from hist_stocks', conn)
# 计算超额收益
market_data['market_return'] = market_data['pchg'] / 100 # 市场收益率
rf_data['rf'] = rf_data['ydl'] / 100 # 无风险利率
stock_data['stock_return'] = stock_data['pchg'] / 100 # 个股收益率
# 数据合并(按日期对齐)
merge_data = pd.merge(stock_data, market_data[['date', 'market_return']], on='date', how='inner')
merge_data = pd.merge(merge_data, rf_data[['date', 'rf']], on='date', how='inner')
merge_data['excess_stock'] = merge_data['stock_return'] - merge_data['rf']
merge_data['excess_market'] = merge_data['market_return'] - merge_data['rf']
# 回归分析(省略循环处理20只股票的代码)
... # 省略内容:遍历每只股票,筛选数据并进行OLS回归,输出α、β系数及统计指标
conn.close()
数据合并后结果如下:
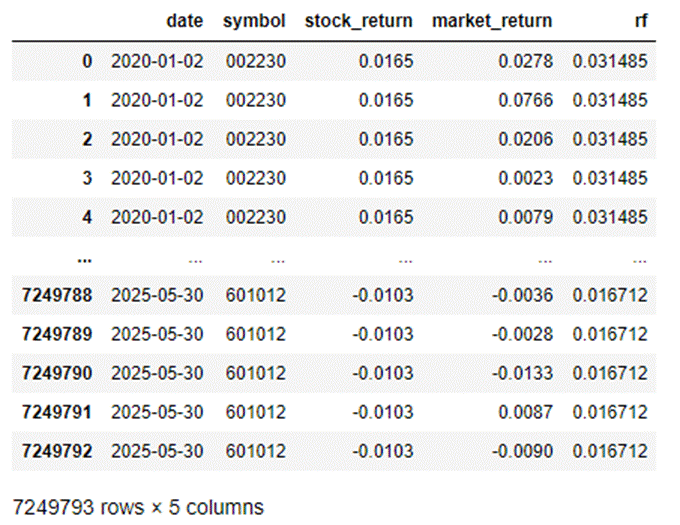
回归结果显示,多数股票的R²在0.006-0.098之间,说明市场因素对个股收益的解释力有限,需结合其他因子分析。其中股票688472的β值为0.4464,敏感度较低,属于稳健型标的;股票300033的β值为0.0598,敏感度极高,风险偏好较高。模型MSE为0.000856,RMSE为2.93%,预测误差适中,适合初步风险评估。
FF三因子模型
核心原理
FF三因子模型在单指数模型基础上,新增规模因子(SMB,小盘股相对大盘股超额收益)和价值因子(HML,高账面市值比股相对低比值股超额收益),公式为:ERi=Rf+βi(ERm-Rf)+siSMBt+hiHMLt。该模型能更全面解释个股收益差异,尤其适配长期资产配置场景。
实现过程与结果
通过申万风格指数数据计算SMB、HML因子,结合市场因子构建模型,采用面板数据固定效应回归分析,核心代码如下:
from linearmodels.panel import PanelOLS
import pandas as pd
import sqlite3
conn = sqlite3.connect('finance_data_2025.db')
style_data = pd.read_sql('select * from swstyles', conn)
market_data = pd.read_sql('select date, pchg from hist_csi300', conn)
# 计算三因子(省略SMB、HML因子详细计算代码)
... # 省略内容:按收盘价划分大盘/小盘组,按市盈率划分高/低组,计算SMB、HML及市场因子MKT
# 数据合并与回归
panel_data = pd.merge(stock_return, factors_data, on='date', how='inner')
panel_data.set_index(['symbol', 'date'], inplace=True) # 设定面板数据索引
model = PanelOLS(panel_data['excess_stock'], sm.add_constant(panel_data[['MKT', 'SMB', 'HML']]),
entity_effects=True, cov_type='clustered', cluster_entity=True)
result = model.fit()
print(result)
conn.close()
因子计算结果与合并后数据如下:

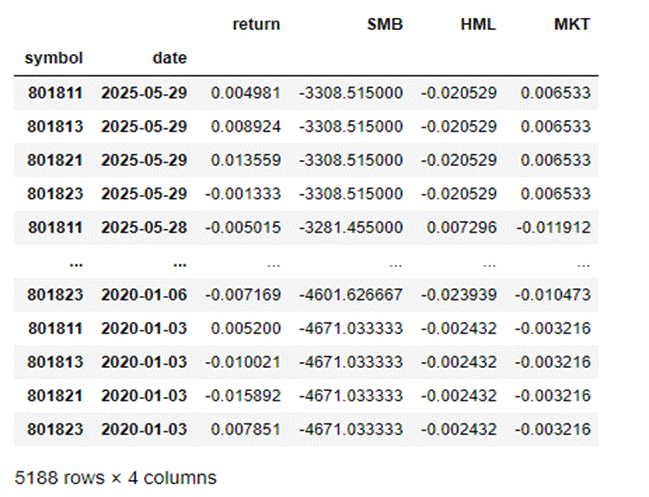
回归结果显示,模型R²达0.7697,对个股收益的解释力显著优于单指数模型。MKT因子显著为正,说明市场风险溢价对个股收益影响显著;SMB、HML因子系数接近0且不显著,反映在本数据集中,规模与价值因素对收益影响较弱。模型MSE为0.000387,RMSE为1.97%,预测精度大幅提升,适合长期投资策略制定。
股价涨跌预测模型
特征构建与数据处理
选取市场收益率、10年期国债利率、300ETF期权波动率指数作为特征变量,分别反映市场整体走势、宏观资金成本、投资者恐慌情绪。对数据进行索引对齐、缺失值填补(均值法),筛选后数据如下: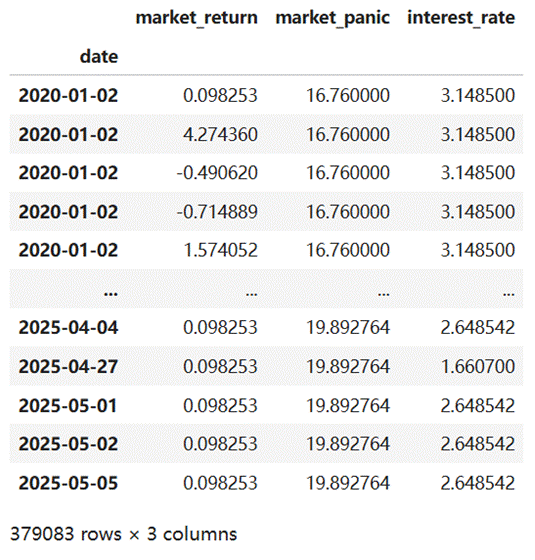
双模型对比应用
分别构建决策树回归与线性回归模型,预测未来30天个股收益率,核心代码如下:
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
import pandas as pd
# 特征与目标变量提取
X = merge_data[['market_return', 'interest_rate', 'market_panic']]
y = merge_data['future_return_30d'] # 未来30天收益率(提前计算)
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 决策树模型(省略参数调优代码)
dt_model = DecisionTreeRegressor(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
dt_r2 = r2_score(y_test, dt_pred)
dt_mse = mean_squared_error(y_test, dt_pred)
# 线性回归模型
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
lr_pred = lr_model.predict(X_test)
lr_r2 = r2_score(y_test, lr_pred)
lr_mse = mean_squared_error(y_test, lr_pred)
# 输出结果
print(f"决策树模型:R²={dt_r2:.2f}, MSE={dt_mse:.8f}")
print(f"线性回归模型:R²={lr_r2:.2f}, MSE={lr_mse:.6f}")
回归分析结果如下:
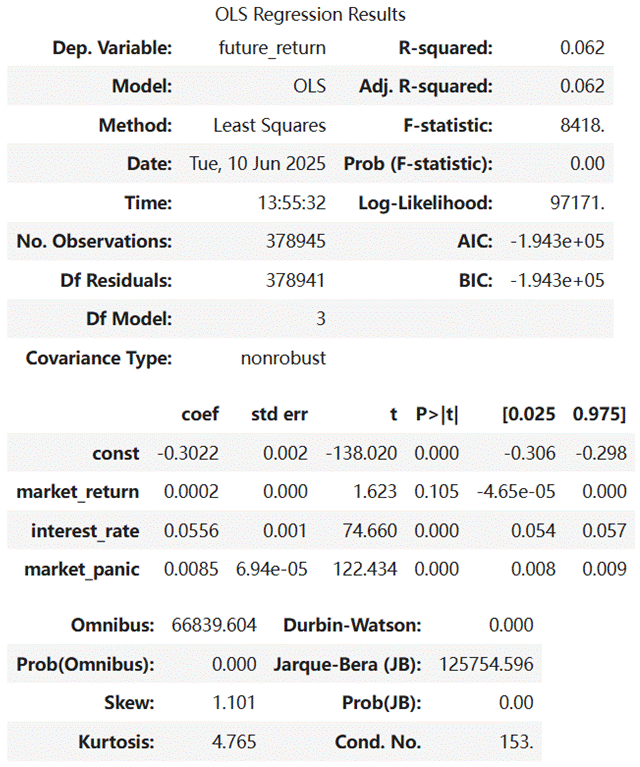
结果显示,决策树模型R²达0.99、MSE为2.42e-08,拟合效果极佳,但需警惕过拟合风险,实际应用中需通过剪枝优化泛化能力;线性回归模型R²仅0.063,解释力较弱,且残差存在正自相关性,适合辅助验证线性关系。
模型对比与适配场景
多模型核心差异
- 复杂度与解释力:单指数模型结构简单、计算高效,适合快速初步分析;FF三因子模型引入双额外因子,解释力提升显著;股价涨跌预测模型结合机器学习,能捕捉非线性关系,但复杂度最高。
- 预测精度:FF三因子模型(RMSE 1.97%)优于单指数模型(RMSE 2.93%),决策树模型拟合精度最高但泛化风险大。
- 数据需求:单指数模型仅需市场与个股数据,FF三因子模型需额外风格指数数据,股价涨跌预测模型需补充宏观与情绪指标。
实际应用场景适配
- 单指数模型:适配短期交易决策,可快速判断个股对市场波动的敏感度,尤其适合市场大幅波动时的风险预判。
- FF三因子模型:适配长期资产配置,能综合评估市场、规模、价值因素,为跨风格投资组合优化提供支撑。
- 股价涨跌预测模型:适配多因素综合分析,可通过特征重要性识别关键影响指标,辅助投资者调整持仓结构。
研究局限与未来方向
局限性
本项目数据时间跨度为2020-2025年,未能覆盖完整市场周期;特征变量未纳入公司基本面指标,可能影响模型全面性;决策树模型存在过拟合风险,泛化能力需进一步验证。
未来拓展方向
扩展数据时间跨度与维度,纳入市盈率、市净率等基本面指标;引入模型集成方法(如随机森林、梯度提升)优化预测精度;开发实时预测系统,结合24小时代码应急修复服务,实现从数据分析到决策落地的全流程支撑。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据 Python用SentenceTransformer、OLS、集成学习、模型蒸馏情感分类金融新闻文本|附代码数据
Python用SentenceTransformer、OLS、集成学习、模型蒸馏情感分类金融新闻文本|附代码数据 2025年金融科技AI+Agent技术金融应用探索与实践报告:市场规模、专利与财富管理革新|附400+份报告PDF、数据、可视化模板汇总下载
2025年金融科技AI+Agent技术金融应用探索与实践报告:市场规模、专利与财富管理革新|附400+份报告PDF、数据、可视化模板汇总下载

