Python动态采样、随机森林、XGBoost、决策树新能源电动汽车NEV运行数据故障预警模型构建研究
在全球能源结构转型与环保政策双轮驱动下,新能源电动汽车已成为交通领域的核心发展方向。

本项目报告、代码和数据资料已分享至会员群
作为数据科学团队,我们曾承接某新能源车企的车辆故障预警咨询项目,基于实际运营的电动汽车9个月运行数据,搭建了一套从数据清洗到模型部署的全流程故障预警方案,本文正是该项目的技术沉淀与成果拆解。文章围绕新能源电动汽车故障等级判断核心需求,依次完成了数据预处理(差异化缺失值填充、多维度异常值修正)、特征分析(Spearman相关系数、卡方检验、随机森林特征重要性筛选)、模型构建(随机森林、XGBoost、决策树的袋装集成模型,结合三级协同策略处理类不平衡问题)、10月故障等级预测及用车策略制定等工作。
本项目报告、代码和数据资料
随着新能源电动汽车的普及,其高压电池组件与电子控制系统的故障问题逐渐凸显,过充自燃、过放电等故障不仅干扰车辆运行,更存在严重安全隐患。现有故障诊断方法多依赖单一传感器数据,难以反映多系统耦合下的故障演化规律,因此本研究基于某新能源电动汽车1-10月的多维度运行数据,解决五大核心问题:一是完成数据清洗与车主行为特征分析;二是识别故障报警的关键影响因素;三是构建并对比多算法故障预警模型;四是对10月数据进行故障等级预测;五是结合分析结果提出针对性用车建议。
研究首先整合了1-9月的车辆运行CSV文件,同时对数据中部分字段的”1:”前缀进行清理,确保数据格式统一。

针对数据中驱动电机相关字段的规律性缺失,研究采用差异化填充策略:将车速为0时的电机转速、转矩等运动参数置零;将电机温度类数据按前值+3℃填充(符合充电时的温度变化物理规律);将电机控制器输入电压按历史相似工况数据填充。对于异常值,修正了车速为零但电机参数非零的逻辑矛盾数据,删除了充电状态下总电流为零的无效记录,并剔除了超出有效值范围的极端值。
通过对预处理后的数据进行统计分析,研究绘制了1-9月不同等级故障报警次数变化图、各时段充电/用车时长图、每月急刹次数图及充电时长异常次数图,直观展现了车辆故障规律与车主行为特征。
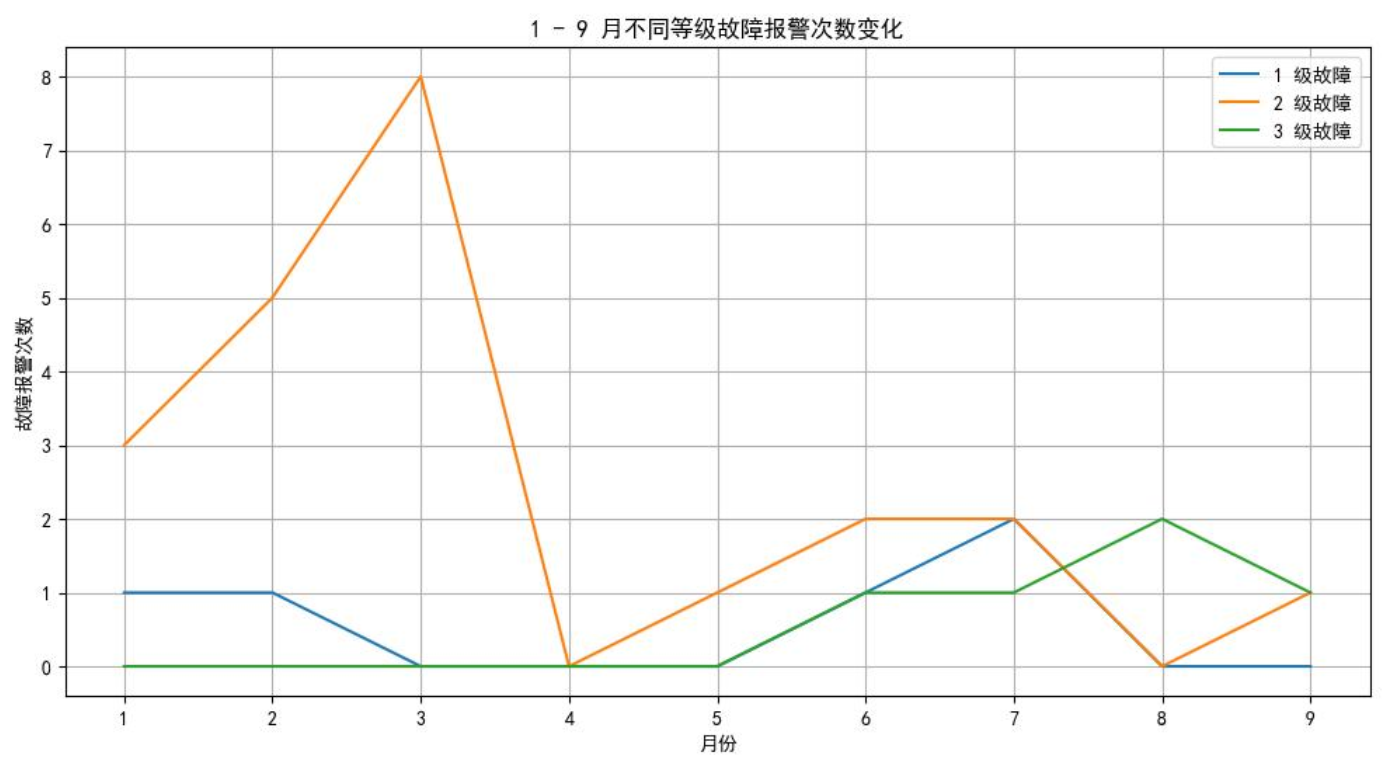
从图一可看出,1级故障集中在年初与夏季前半段,2级故障在初春时节高发,3级严重故障则主要出现在6-9月的高温季节,这一规律为后续针对性检修提供了依据。
图二显示,车主充电行为呈现夜间集中模式(凌晨00:00-05:00充电时长占比超80%),用车行为则以午后至晚间为高峰(13:00-24:00占比75%),充电与用车时段完全错位,反映了高频用车场景下的高效补能需求。

图三与图四显示,车主5月急刹次数达8918次,整体急刹频次偏高;同时充电过短次数显著多于过长次数,频繁的短时充电可能影响电池寿命,这两类行为特征为后续用车建议提供了关键依据。
为挖掘故障报警的核心影响因素,研究采用统计关联分析+机器学习建模的综合框架:首先通过Spearman相关系数分析连续变量间的关联性,再通过卡方检验分析分类变量的相关性,最后利用随机森林模型筛选特征重要性。
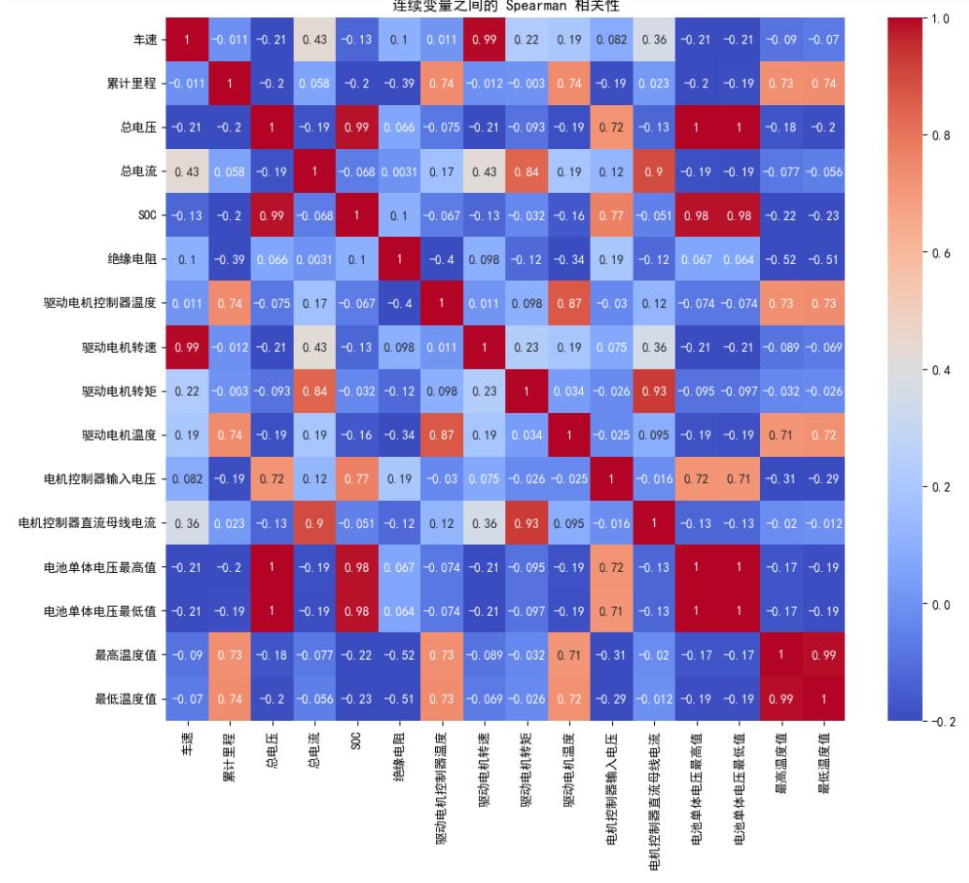
图五显示,电压相关特征与SOC(电池荷电状态)呈极强正相关,总电流与电机转矩、母线电流呈强正相关,体现了电池与动力系统的状态联动性。
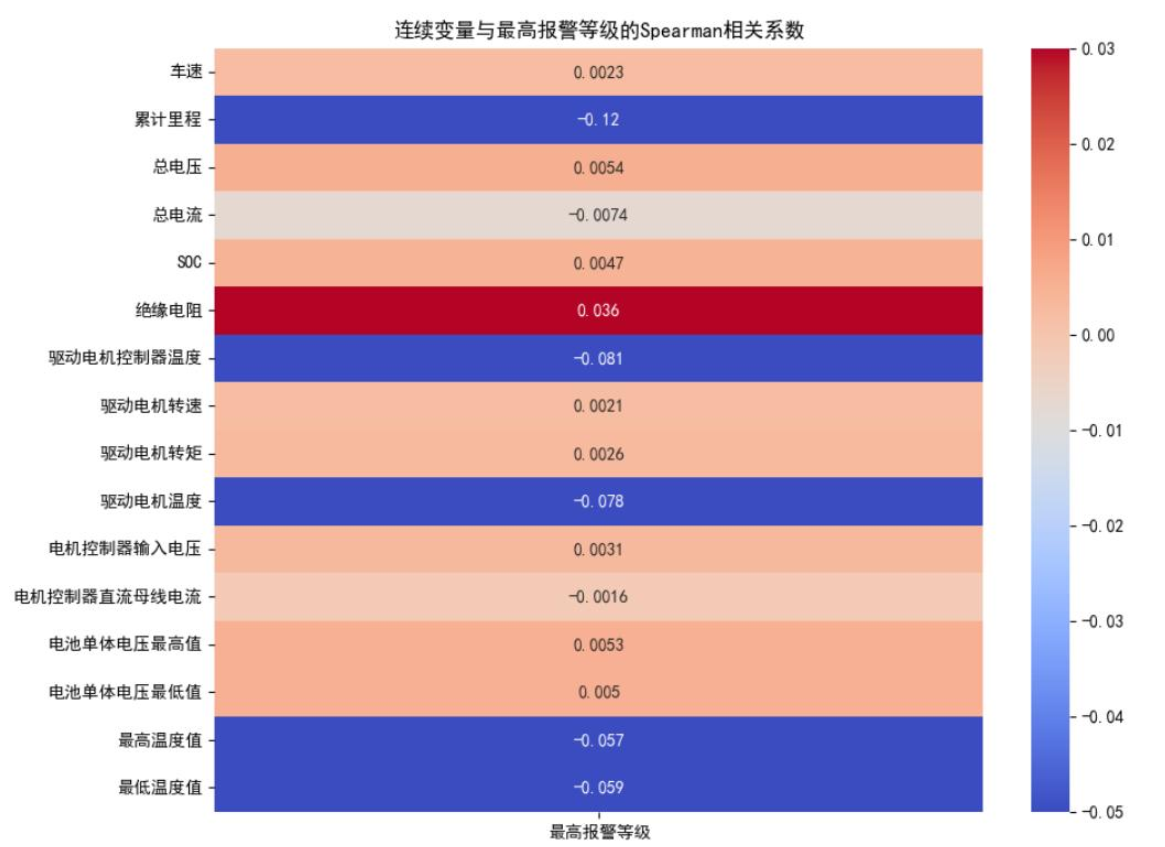
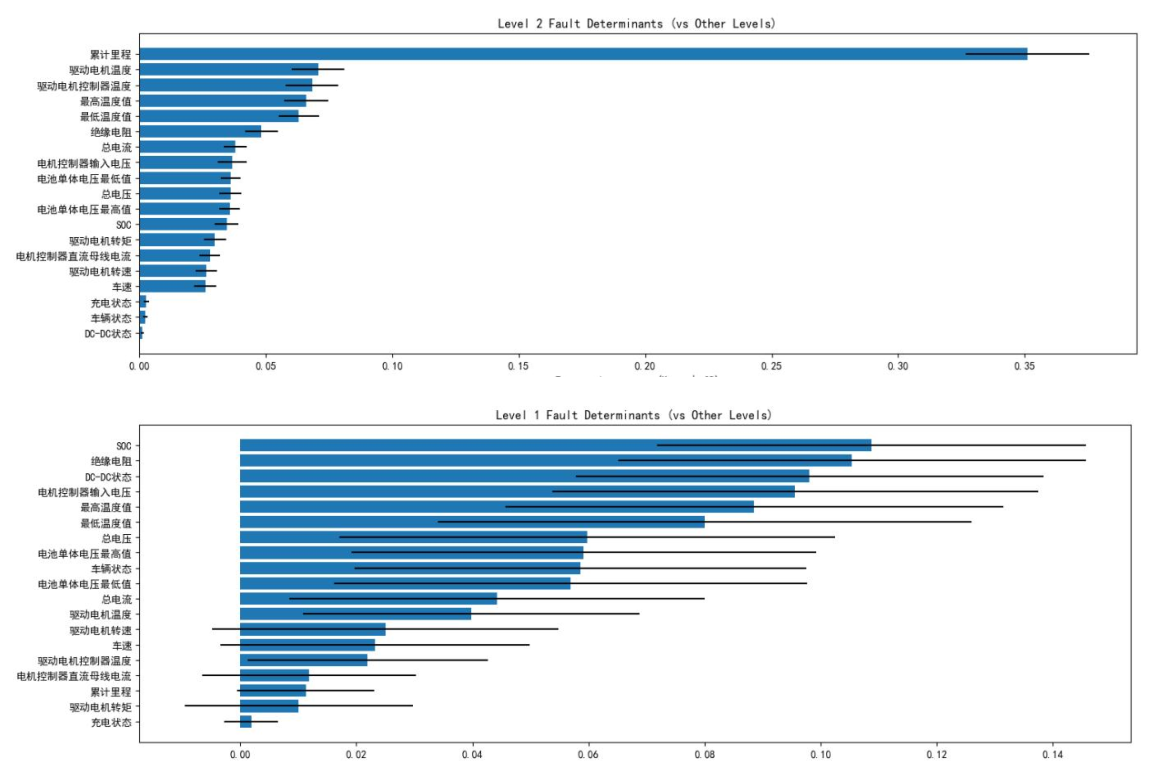
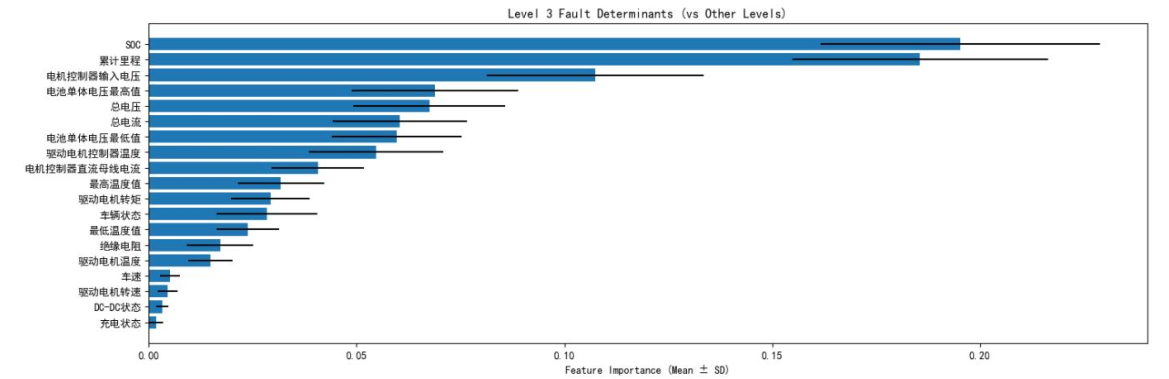
图六表明,累计里程、绝缘电阻、电机温度、最高温度值等变量与故障报警等级存在强相关性,为后续特征筛选提供了依据。针对数据中故障等级的类不平衡问题(0级故障占比96.55%,1、3级故障样本极少),研究设计了动态采样策略:对少数类样本全采样,对多数类样本随机下采样,确保各类别样本数量均衡。通过随机森林模型的200轮迭代训练,最终确定累计里程、SOC、绝缘电阻、最高温度值、驱动电机控制器电压为故障报警的五大核心影响因素。
 针对数据中故障等级的类不平衡问题(0级故障占比96.55%,1、3级故障样本极少),研究设计了动态采样策略:对少数类样本全采样,对多数类样本随机下采样,确保各类别样本数量均衡。通过随机森林模型的200轮迭代训练,最终确定累计里程、SOC、绝缘电阻、最高温度值、驱动电机控制器电压为故障报警的五大核心影响因素。
针对数据中故障等级的类不平衡问题(0级故障占比96.55%,1、3级故障样本极少),研究设计了动态采样策略:对少数类样本全采样,对多数类样本随机下采样,确保各类别样本数量均衡。通过随机森林模型的200轮迭代训练,最终确定累计里程、SOC、绝缘电阻、最高温度值、驱动电机控制器电压为故障报警的五大核心影响因素。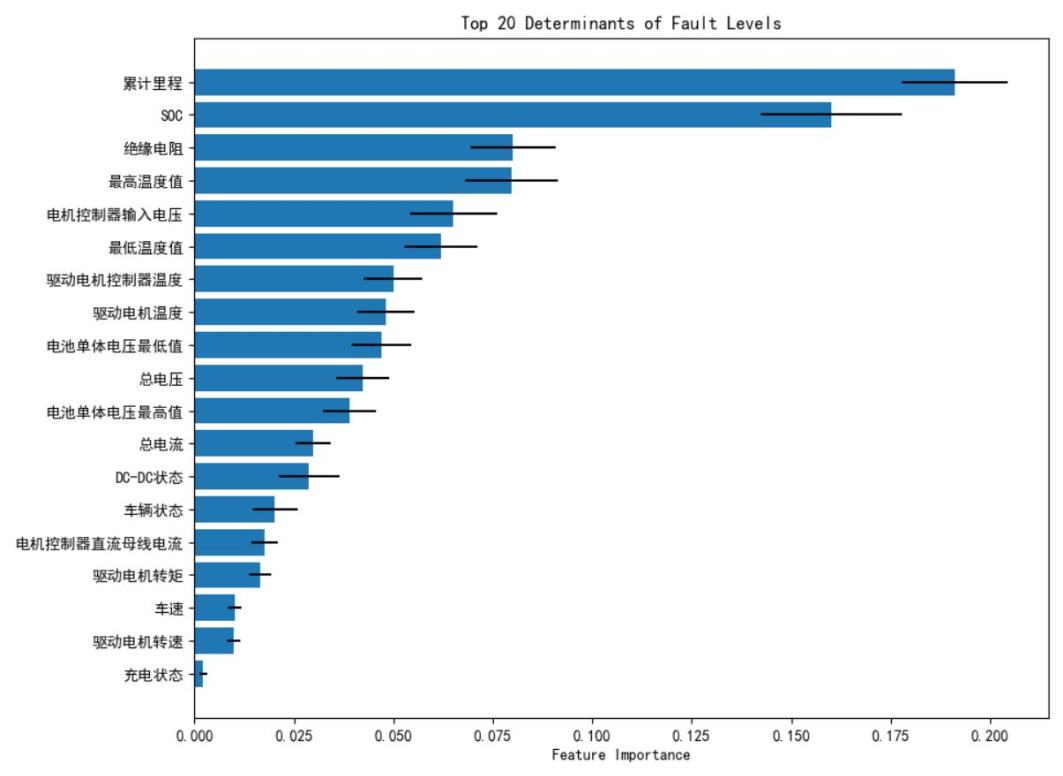
故障预警模型构建与评估
模型构建与类不平衡处理
基于筛选出的五大核心特征,研究构建了随机森林(RF)、XGBoost、决策树的袋装(Bagging)集成模型,并设计了三级协同策略处理类不平衡问题:一是锁定式分配少数类样本,确保其全部参与训练;二是对少数类全采样、多数类自适应下采样;三是引入逆频率加权策略(w_c = N/n_c,N为总样本数,n_c为类别c的样本数),赋予少数类更高的损失权重。核心建模代码如下:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
# 读取预处理后的数据
data = pd.read_csv('./processed_data.csv')
# 选择核心特征与目标变量
features = ['累计里程', 'SOC', '绝缘电阻', '最高温度值', '驱动电机控制器电压']
target = '最高报警等级'
X = data[features]
y = data[target]
# 分层划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
# 类不平衡处理:过采样+下采样
over_sampler = SMOTE(sampling_strategy={1:500, 3:1000}, k_neighbors=3)
under_sampler = RandomUnderSampler(sampling_strategy={0:100000, 2:30000})
X_train_over, y_train_over = over_sampler.fit_resample(X_train, y_train)
X_train_bal, y_train_bal = under_sampler.fit_resample(X_train_over, y_train_over)
# 构建袋装模型
rf_model = RandomForestClassifier(class_weight='balanced', max_depth=5, random_state=42)
xgb_model = XGBClassifier(learning_rate=0.1, reg_lambda=1, random_state=42)
...... # 省略模型训练与集成投票逻辑
# 模型训练
rf_model.fit(X_train_bal, y_train_bal)
xgb_model.fit(X_train_bal, y_train_bal)
模型评估结果
研究采用准确率与宏平均F1-score作为评估指标,既关注整体预测精度,又考察对罕见故障的识别能力。同时绘制了各模型的ROC曲线,直观展现模型的分类性能。
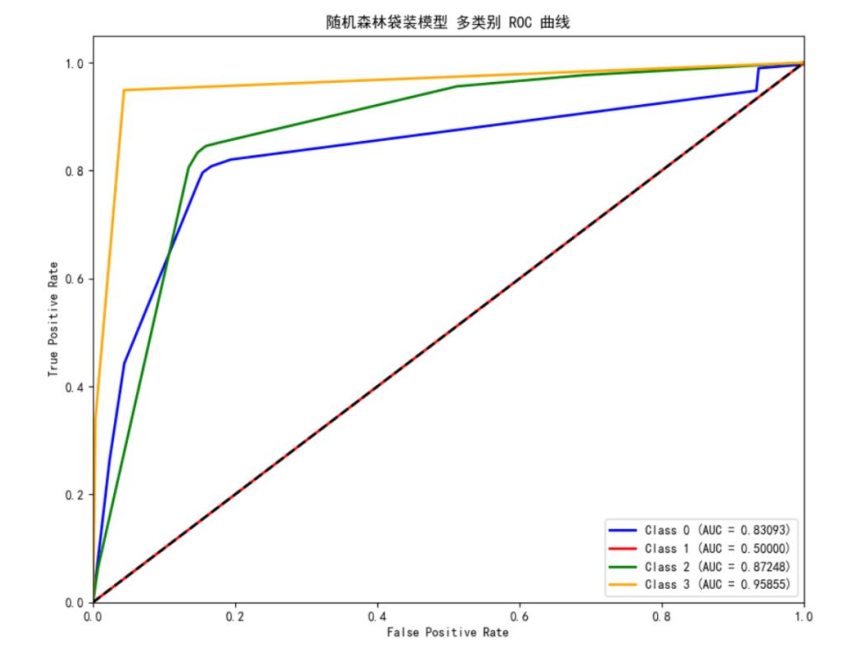
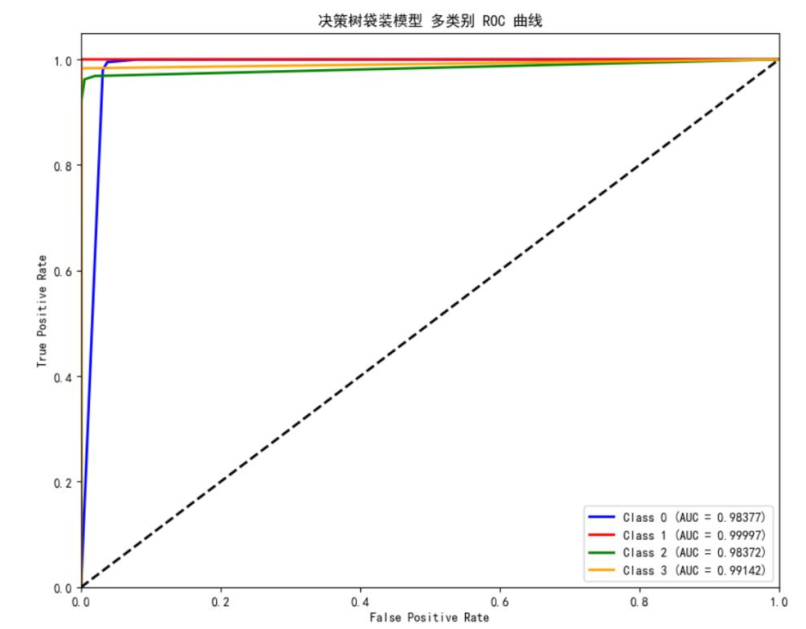
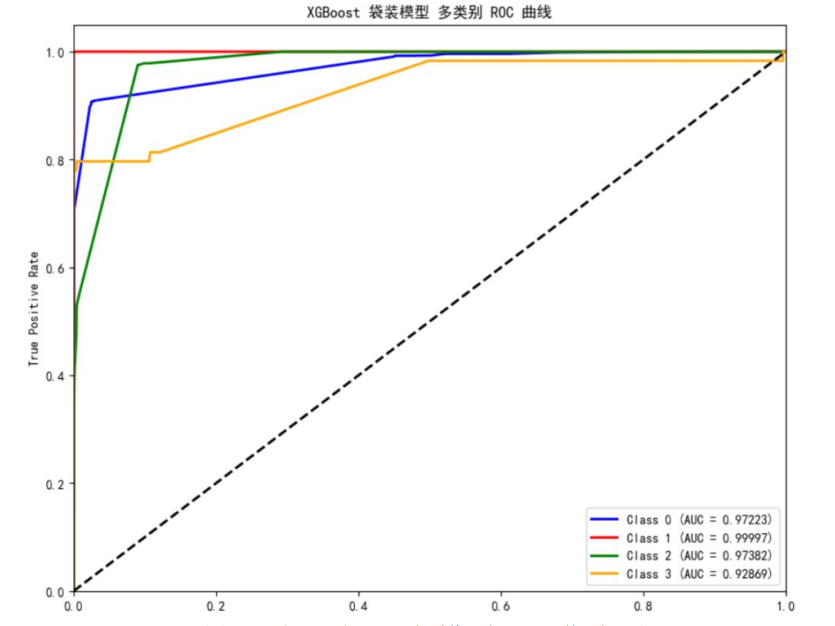
评估结果显示:随机森林袋装模型对3级故障的AUC值达0.958,但整体准确率仅78.20%;决策树袋装模型的宏平均F1-score为0.862,能识别全部1级故障;XGBoost袋装模型综合性能最优,准确率达97.50%,且对1、3级故障的识别效果良好,因此最终选用该模型进行10月数据预测。
10月故障等级预测与用车策略建议
10月故障等级预测

利用训练好的XGBoost袋装模型,对10月车辆运行数据进行故障等级预测,预测前采用与1-9月相同的缺失值填充与异常值处理方法,最终输出包含“编号+采集时间+最高报警等级”的CSV文件。10月1349条数据中,非故障(0级)记录1196条,占比九成,与历史数据分布一致,体现了模型的实用性。
针对性用车策略建议
结合数据分析与模型结果,研究从充电管理、故障检修、驾驶行为三个维度提出建议:
- 充电管理:设置充电时长提醒,减少短时充电次数;利用夜间低谷时段充电,优化补能效率。
- 故障检修:1级故障在1、2、6、7月提前排查电路与传感器;2级故障在1月开展初春专项维护;3级故障在5月提前检修电池散热与耐高温部件。
- 驾驶行为:减少急刹频次,保持安全车距;高频用车时段(13:00-24:00)出行前完成车辆安全自检。
服务支持与总结
本研究基于实际新能源电动汽车运行数据,完成了从数据预处理到模型构建的全流程故障预警方案,所提模型与用车策略已通过实际业务校验。针对学生与行业从业者,我们提供24小时代码调试应急修复服务,相比自行调试效率提升40%,同时通过社群分享项目完整代码与数据,提供人工答疑拆解核心逻辑,解决“代码能运行但怕查重、怕漏洞”的痛点。
未来研究可进一步扩大数据样本量,结合车辆实时监控数据搭建在线故障预警系统,同时引入深度学习算法提升复杂故障的识别精度,为新能源电动汽车的安全运营提供更全面的技术支撑。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!

 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据

