在经济发展的大背景下,居民消费结构至关重要。本文围绕居民消费结构展开深入研究,运用 SPSS25.0 和 R 语言,以因子分析法和主成分分析法对东北三省居民消费价格指数及全国城镇居民消费性支出指标进行分析。
通过数据标准化、效度检验等步骤,找到公共因子,揭示居民消费结构特点。
在东北三省分析中,明确了消费结构的因子及变化趋势。全国范围的研究(附代码数据)则指出娱乐教育文化服务等是影响消费的主要因素,且发现消费大小与经济发达程度相关。
这些分析和建议为优化居民消费结构、促进地区经济发展提供了科学依据,对政府、企业和居民都具有重要参考价值,有助于推动经济可持续发展。
居民消费结构数据统计分析
由于直接对居民消费结构的各相关因素变量进行分析会受到多重共线性的影响,使得所得模型并不稳定,甚至与我们所认知的实际经济现象有所出入。因此本文将运用SPSS25.0软件,以多元统计学中的因子分析法为基础,通过对居民消费的各指标进行分析,从而找到具有一定一致性的公共因子,之后以此为变量进行后续的数据分析。
解决方案
任务/目标
运用 SPSS 软件,对东北三省居民消费价格指数数据进行消费实例分析并得到公共因子,以此为变量研究居民消费结构质量及其变化趋势。
数据选取
在各种关于居民消费的指标中,居民消费价格指数最能体现消费水平的波动,即能够反映居民在商品劳务等的消费过程中的满足程度。按照上一章描述的统计分析方法步骤,对东北三省的居民消费价格指数近三年数据取平均数后进行后续的分析,本文数据来源于国家统计局网站的分省月度数据。
数据标准化
对原始数据做标准化处理,使得原始数据化为均值为0,方差为1的数据。之后步骤皆以标准化后的数据作为样本进行分析。
效度检验
首先以标准化后的数据为变量进行运算得到它们的样本相关性系数矩阵
表相关性矩阵

Ting Mei
可下载资源
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | ||
| 相关性 | x1 | 1.000 | -0.623 | -0.739 | -0.472 | -0.469 | -0.090 | -0.419 | 0.935 |
| x2 | -0.623 | 1.000 | 0.914 | 0.847 | 0.619 | 0.641 | 0.179 | -0.548 | |
| x3 | -0.739 | 0.914 | 1.000 | 0.934 | 0.790 | 0.692 | 0.487 | -0.632 | |
| x4 | -0.472 | 0.847 | 0.934 | 1.000 | 0.847 | 0.856 | 0.527 | -0.366 | |
| x5 | -0.469 | 0.619 | 0.790 | 0.847 | 1.000 | 0.580 | 0.765 | -0.490 | |
| x6 | -0.090 | 0.641 | 0.692 | 0.856 | 0.580 | 1.000 | 0.308 | 0.107 | |
| x7 | -0.419 | 0.179 | 0.487 | 0.527 | 0.765 | 0.308 | 1.000 | -0.408 | |
| x8 | 0.935 | -0.548 | -0.632 | -0.366 | -0.490 | 0.107 | -0.408 | 1.000 | |
| 显著性(单尾) | x1 | 0.000 | 0.000 | 0.002 | 0.002 | 0.299 | 0.005 | 0.000 | |
| x2 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.144 | 0.000 | ||
| x3 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | ||
| x4 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.013 | ||
| x5 | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | ||
| x6 | 0.299 | 0.000 | 0.000 | 0.000 | 0.000 | 0.032 | 0.264 | ||
| x7 | 0.005 | 0.144 | 0.001 | 0.000 | 0.000 | 0.032 | 0.006 | ||
| x8 | 0.000 | 0.000 | 0.000 | 0.013 | 0.001 | 0.264 | 0.006 |
从上述矩阵可以观察到所选八个消费支出指标间相关系数绝大部分比0.3要大,且显著性概率小于0.05,通过显著性检验,说明要研究的数据适合做因子分析。
再利用KMO与Bartlett球形度检验,且根据KMO的一般度量标准,度量值越接近1表明效果越好。
视频
主成分分析PCA降维方法和R语言分析葡萄酒可视化实例
视频
PCA原理与水果成熟状态数据分析实例:Python中PCA-LDA 与卷积神经网络CNN
视频
【视频讲解】PCA主成分分析原理及R语言经济研究可视化2实例合集
视频
机器学习的交叉验证Cross Validation原理及R语言主成分PCA回归分析城市犯罪率
因子提取
最初数据总方差绝对值为1,提取后的因子总方差越接近于1说明公共因子对原始变量的信息丢失度越少,解释越充分。,所选数据的7个原始变量提取后的共同度即解释有效性都在0.7以上,且大多数在0.9以上,说明提取后的公共因子对于原始数据解释度大于70%,信息提取充分。
本次实验共提取出样本相关系数前2个公共因子,采用了特征值大于1为选取标准,最后得到的两个公共因子累计方差贡献率达84.31 %,故选用2个主因子解释东北地区历年居民消费支出的结构问题。
因子命名
最初得到的因子载荷矩阵各因子没有典型代表性,因此为了得到各个公因子的经济意义,继续进行因子旋转,所采用的方法是最大方差法,目的是使得因子载荷在取得平方项后的值向0、1方向靠近,更好更直观地找到每个因子所表达的经济含义,原理是降低因子综合性增加解释度。所得到因子载荷矩阵见表3-5。
| 成分 | ||
| 1 | 2 | |
| Zscore(生活用品及服务类) | 0.958 | -0.268 |
| Zscore(教育文化和娱乐类) | 0.955 | 0.201 |
| Zscore(居住类) | 0.814 | -0.550 |
| Zscore(交通和通信类) | 0.778 | -0.417 |
| Zscore(衣着类) | 0.746 | -0.443 |
| Zscore(医疗保健类) | 0.462 | -0.421 |
| Zscore(其他用品和服务类) | -0.102 | 0.987 |
| Zscore(食品烟酒类) | -0.234 | 0.935 |
于是得到消费结构的因子分析模型为:

结合各指标的具体经济含义对每个因子给出合适的经济意义概括,应该选取相关系数绝对值较大的,这说明了此因子对该变量的代表性越强,以上所得到的新的两个因子从更低维度但全面地展现了居民消费支出的情况,同时也反映出居民支出由基本生存逐步发展的趋势。第一因子对原始数据方差贡献率达到几乎50%,这可以说明东北地区的居民消费支出已经在向食品之外的类型
因子得分
因子得分函数如下:

之后根据表4利用主因子与方差贡献率可以知道,他们的方差贡献率为:第一个因子是49.18%,第二个因子是35.13%,由此得出综合评分函数如下:

对于借助软件得到的因子得分结果中的数据进行选择性提取,找到具有代表性的数据结果见表3-7。
| 时间 | FAC1 | FAC2 | F |
| 2018年6月 | 0.5906 | -0.92813 | -0.04 |
| 2018年12月 | 0.70039 | -0.84905 | 0.05 |
| 2019年2月 | 0.75891 | -0.48442 | 0.2 |
| 2019年4月 | 0.82016 | -0.31139 | 0.29 |
| 2019年12月 | 0.36636 | 0.43242 | 0.33 |
| 2020年1月 | 0.18486 | 1.66491 | 0.68 |
| 2020年6月 | -0.43545 | 1.34562 | 0.26 |
| 2020年12月 | -1.07994 | 0.57819 | -0.33 |
| 2021年1月 | -2.7612 | -1.5676 | -1.91 |
其中,FAC1,FAC2分别代表两个因子相应的的消费支出类别方面的得分,F代表总消费结构得分。从中可以看出,虽然东北地区以消费为主的第二因子在2018,2019两年几乎始终位于平均水平之下,但整体结构上两个因子在这两年间整体均呈现上升趋势,但是自1999年末之后,F1发展因子开始出现明显下滑,而以食物为主体的F2生存因子出现瞬间暴涨后飞速下跌,这主要受到了新冠疫情的影响,截止到目前,两因子得分甚至不如2018年初,说明该地区当前经济仍未回转。
建议
以上分析所发现的东北地区城镇居民消费结构产生的状况,我们需要从多方面着手研究从而得到问题的解决措施,结合实例分析所得到的结果,也要考虑当地经济社会发展情况。
1.努力提高居民收入水平
居民消费结构的优化在收入水平的高低的影响因素中占有相对重要的地位,这是由于居民收入水平的高低决定了它对于所需求商品的支付能力,所以为了优化地区的居民消费结构,可以针对居民收入水平的提高做出一定的对策。对此我们可以通过增加就业岗位鼓励就业,创造良好的就业环境,以此来增加该地区的居民收入,或者通过政府为企业就业岗位提供一些友好的政策,提升劳动者的入职积极性。
随时关注您喜欢的主题
2.改善居民消费结构
想要对居民消费结构进行优化,就要在满足居民生存性消费的基础之上,对于发展以及享受型消费,加大投入使得居民消费的结构化更加合理,以推动地区的发展的更好适应。对于不同的消费领域,还要给予相关经济投入以及政策支持,在住房方面,控制房屋价格上涨,保障一般居民的住房问题;在医疗方面加强基础医疗体质的便利;同时也要关注居民在娱乐、旅行等服务业的需求。同时也要让各个产业自身积极创新并提升服务质量。
3.积极促进线上消费
由于新冠疫情的出现打破了人们原先的生活节奏,居民的各方面消费支出受阻,校园学习、日常办公等都被迫转移到了线上,因此在日常线下的消费开始迅速减少,线上经济例如学生网课、外卖餐饮领域开始茁壮发展。所以我们应该顺应当前趋势,积极促进线上消费的发展,逐步恢复居民对于消费的活力并在稳定经济运行的前提下快速回转。
R语言、SPSS基于主成分分析PCA的中国城镇居民消费结构研究可视化分析|附数据代码
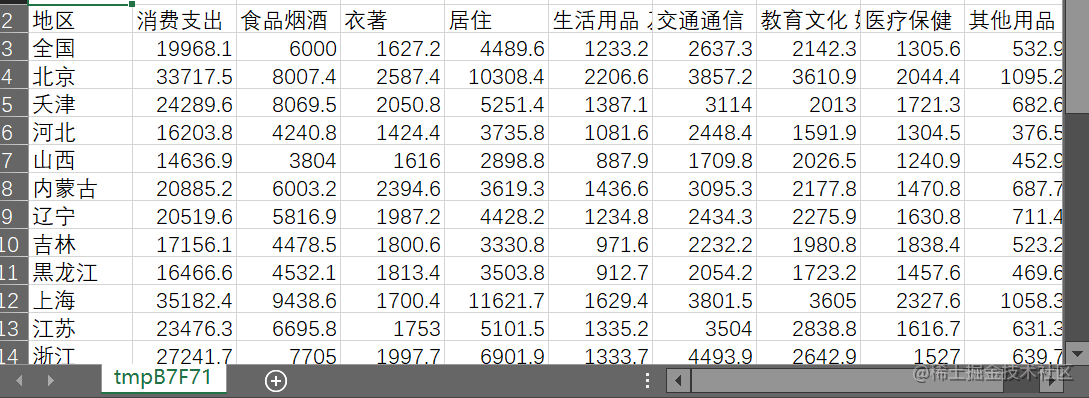
以全国31个省、市、自治区的城镇居民家庭平均每人全年消费性支出的食品、衣着、居住、家庭设备用品及服务、医疗保健、交通与通讯、娱乐教育文化服务、其它商品和服务等 8 个指标数据为依据, 利用SPSS和R统计软件, 采用主成分分析法对当前城镇居民消费结构进行分析, 结果显示: 娱乐教育文化服务、交通通讯、家庭设备用品、居住、食品是影响消费大小变动的主要因素, 而衣着、医疗保健、居住、食品是影响消费结构变动的主要因素; 各省市城镇居民消费大小与其经济发达程度密切相关; 相邻省市消费结构比较相似; 沿海地区与内地消费结构有较大的差别
第一步:录入或调入数据
第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor”的路径打开因子分析选项框
第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中。在本例中,全部8个变量都要用上,故全部调入(图4)。因无特殊需要,故不必理会“Value”栏。下面逐项设置
⒈ 设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框。
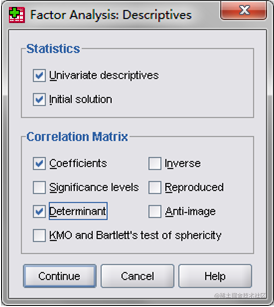
在Statistics栏中选中Univariate descriptives复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix栏中,选中Coefficients复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant复选项,则会给出相关系数矩阵的行列式,如果希望在Excel中对某些计算过程进行了解,可选此项,否则用途不大。其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue按钮完成设置。
设置Extraction选项。
打开Extraction对话框。因子提取方法主要有7种,在Method栏中可以看到,系统默认的提取方法是主成分,因此对此栏不作变动,就是认可了主成分分析方法。
在Analyze栏中,选中Correlation matirx复选项,则因子分析基于数据的相关系数矩阵进行分析;如果选中Covariance matrix复选项,则因子分析基于数据的协方差矩阵进行分析。对于主成分分析而言,由于数据标准化了,这两个结果没有分别,因此任选其一即可。
在Display栏中,选中Unrotated factor solution(非旋转因子解)复选项,则在分析结果中给出未经旋转的因子提取结果。对于主成分分析而言,这一项选择与否都一样;对于旋转因子分析,选择此项,可将旋转前后的结果同时给出,以便对比。
选中Scree Plot(“山麓”图),则在分析结果中给出特征根按大小分布的折线图(形如山麓截面,故得名),以便我们直观地判定因子的提取数量是否准确。
主成分计算是利用迭代(Iterations)方法,系统默认的迭代次数是25次。但是,当数据量较大时,25次迭代是不够的,需要改为50次、100次乃至更多。对于本例而言,变量较少,25次迭代足够,故无需改动。
设置Scores设置。
选中Save as variables栏,则分析结果中给出标准化的主成分得分(在数据表的后面)。至于方法复选项,对主成分分析而言
选中Display factor score coefficient matrix,则在分析结果中给出因子得分系数矩阵及其相关矩阵。
其它。
对于主成分分析而言,旋转项(Rotation)可以不必设置;对于数据没有缺失的情况下,Option项可以不必理会。
| Correlation Matrixa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 消费支出 | 食品烟酒 | 衣著 | 居住 | 生活用品及服务 | 交通通信 | 教育文化娱乐 | 医疗保健 | 其他用品及服务 | ||
| Correlation | 消费支出 | 1.000 | .873 | .499 | .960 | .838 | .872 | .860 | .715 | .906 |
| 食品烟酒 | .873 | 1.000 | .262 | .811 | .663 | .755 | .620 | .396 | .751 | |
| 衣著 | .499 | .262 | 1.000 | .377 | .646 | .424 | .355 | .606 | .649 | |
| 居住 | .960 | .811 | .377 | 1.000 | .774 | .761 | .825 | .657 | .861 | |
| 生活用品及服务 | .838 | .663 | .646 | .774 | 1.000 | .685 | .730 | .608 | .804 | |
| 交通通信 | .872 | .755 | .424 | .761 | .685 | 1.000 | .774 | .624 | .727 | |
| 教育文化娱乐 | .860 | .620 | .355 | .825 | .730 | .774 | 1.000 | .735 | .743 | |
| 医疗保健 | .715 | .396 | .606 | .657 | .608 | .624 | .735 | 1.000 | .694 | |
| 其他用品及服务 | .906 | .751 | .649 | .861 | .804 | .727 | .743 | .694 | 1.000 | |
| a. Determinant = 1.69E-014 |
Correlation Matrix(相关系数矩阵),一般而言,相关系数高的变量,大多会进入同一个主成分,但不尽然,除了相关系数外,决定变量在主成分中分布地位的因素还有数据的结构。相关系数矩阵对主成分分析具有参考价值,毕竟主成分分析是从计算相关系数矩阵的特征根开始的。
在Communalities(公因子方差)中,给出了因子载荷阵的初始公因子方差(Initial)和提取公因子方差(Extraction)
| Communalities | ||
|---|---|---|
| Initial | Extraction | |
| 消费支出 | 1.000 | .975 |
| 食品烟酒 | 1.000 | .659 |
| 衣著 | 1.000 | .362 |
| 居住 | 1.000 | .860 |
| 生活用品及服务 | 1.000 | .770 |
| 交通通信 | 1.000 | .754 |
| 教育文化娱乐 | 1.000 | .764 |
| 医疗保健 | 1.000 | .605 |
| 其他用品及服务 | 1.000 | .864 |
| Extraction Method: Principal Component Analysis. |
在Total Variance Explained(全部解释方差) 表的Initial Eigenvalues(初始特 7 征根)中,给出了按顺序排列的主成分得分的方差(Total),在数值上等于相关系数矩阵的各个特征根λ,因此可以直接根据特征根计算每一个主成分的方差百分比(% of Variance)。
| Total Variance Explained | ||||||
|---|---|---|---|---|---|---|
| Component | Initial Eigenvalues | Extraction Sums of Squared Loadings | ||||
| Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | |
| 1 | 6.613 | 73.479 | 73.479 | 6.613 | 73.479 | 73.479 |
| 2 | .992 | 11.027 | 84.506 | |||
| 3 | .555 | 6.162 | 90.668 | |||
| 4 | .298 | 3.313 | 93.980 | |||
| 5 | .259 | 2.879 | 96.859 | |||
| 6 | .131 | 1.454 | 98.314 | |||
| 7 | .088 | .980 | 99.294 | |||
| 8 | .064 | .706 | 100.000 | |||
| 9 | 8.213E-11 | 9.125E-10 | 100.000 | |||
| Extraction Method: Principal Component Analysis. |
主成分的数目可以根据相关系数矩阵的特征根来判定,如前所说,相关系数矩阵的特征根刚好等于主成分的方差,而方差是变量数据蕴涵信息的重要判据之一。根据λ值决定主成分数目的准则有三:
i 只取λ>1的特征根对应的主成分
从Total Variance Explained表中可见,第一、第二和第三个主成分对应的λ值都大于1,这意味着这三个主成分得分的方差都大于1。本例正是根据这条准则提取主成分的。
ii 累计百分比达到80%~85%以上的λ值对应的主成分
在Total Variance Explained表可以看出,前三个主成分对应的λ值累计百分比达到89.584%,这暗示只要选取三个主成分,信息量就够了。
iii 根据特征根变化的突变点决定主成分的数量
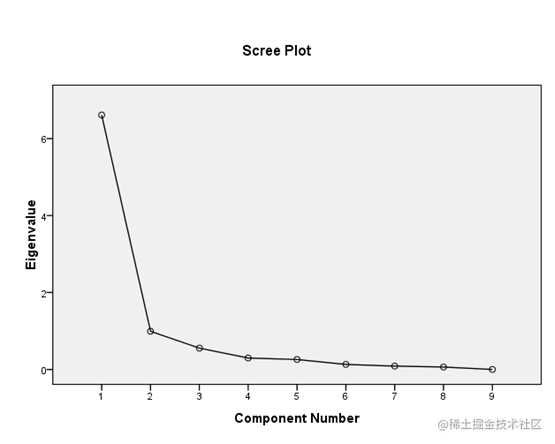
从特征根分布的折线图(Scree Plot)上可以看到,第4个λ值是一个明显的折点,这暗示选取的主成分数目应有p≤4。那么,究竟是3个还是4个呢?根据前面两条准则,选3个大致合适(但小有问题)。
在Component Matrix(成分矩阵)中,给出了主成分载荷矩阵,每一列载荷值都显示了各个变量与有关主成分的相关系数。以第一列为例,0.885实际上是消费支出与第一个主成分的相关系数。
| Component Matrixa | |
|---|---|
| Component | |
| 1 | |
| 消费支出 | .987 |
| 食品烟酒 | .812 |
| 衣著 | .601 |
| 居住 | .928 |
| 生活用品及服务 | .877 |
| 交通通信 | .868 |
| 教育文化娱乐 | .874 |
| 医疗保健 | .778 |
| 其他用品及服务 | .930 |
| Extraction Method: Principal Component Analysis. | |
| a. 1 components extracted. |
R语言按地区划分的主成分可视化
res.pca <- prcomp(data[, -1], scale = TRUE)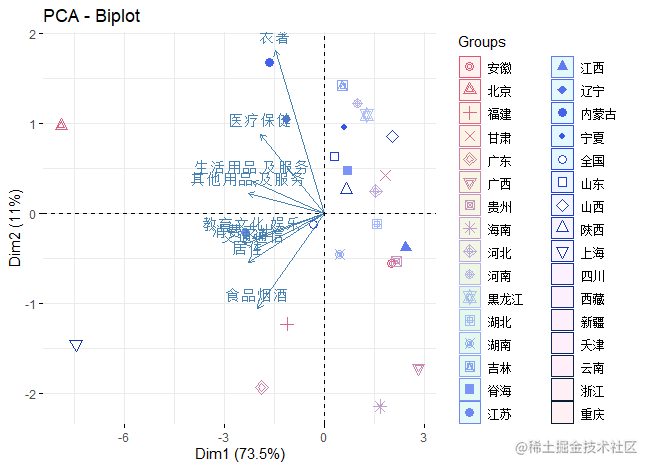

关于分析师
Ting Mei
在此对Ting Mei对本文所作的贡献表示诚挚感谢。她本科毕业于山西财经大学金融数学专业,硕士就读于华北电力大学应用统计专业。会用 eviews、spss 处理数据,且系统学习过 Python、MATLAB,在数理统计和数理金融方面有扎实的知识基础。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!


