对于时间序列分析,有两种数据格式: ts (时间序列)和 xts (可扩展时间序列)。
前者不需要时间戳,可以直接从向量转换。后者非常重视日期和时间,因此只能使用日期和/或时间列来定义。我们涵盖了基本的时间序列模型,即 ARMA、GARCH 和 VAR。
可下载资源
时间序列数据
函数 ts 将任何向量转换为时间序列数据。
1、ts
ts是R语言内置的类,用于表示规则的一元时间序列对象。什么是规则的时间序列呢?可以这样定义:随时间变化,按照相等的时间区间(如年月日)记录的有序观测序列。一个ts对象由两部分组成,序列值和对应的时间索引。时间索引提供了每个观测记录在序列中的时间,也叫做时间戳。
ts对象是一个二维的数据集(时间索引和序列观测),但是ts的时间索引是嵌入到对象本身的(我们将这种索引称为隐式的索引),因此它的序列值就是一个向量,并不具有R中大多数规则表格(如矩阵、数据框)的属性。比如,ts具有length属性,不具备dim属性。TSstudio包的ts_info函数提供了对时间序列对象属性的一些汇总。下面,我们通过一个例子来说明ts对象的一些特点。
2、xts
在ts类之后,R语言中又出现了更复杂的时间序列类zoo(来自zoo包)以及作为zoo类扩展的xts类(来自xts包)。这两个时间序列类可以处理规则和不规则的时间序列数据,它们的索引格式也更加灵活,可以存储更多的时间和日期对象,如Date、POSIXct/lt、yearmon和yearqrt。
xts类是zoo类的扩展,是具有更多属性的zoo对象。也就是说,zoo对象具有的属性xts对象都具有,zoo包的函数也可以对xts对象进行运用。关于zoo对象就不再讨论,只提一点:zoo包的rollapply函数是对时间序列进行滚动计算的一个常用方法。
3、tsibble
tsibble包的主要功能是将tidyverse的应用扩展到时态数据上(包括时间序列数据和纵向数据)。tsibble包提供的时间序列类tsibble建立在整洁的数据框tibble的基础上,是一个面向数据和模型的对象类。与上面介绍的ts和xts相比,tsibble在保留时间索引的同时,引入了异质的数据结构。tsibble的另一个特点是引入了由单个或多个变量组成的键(key)来唯一地识别随时间索引变化的观测单位。tsibble包还提供了流畅的工作流用于分析时态数据。
tsibble中采用的”整洁数据”具有如下原则:
1、索引(index)是一个变量,标示了时间变化的内在顺序
2、键(key)是一组变量,它们定义了随时间变化的观测单元
3、每个观测应该是通过索引和键进行唯一识别
4、如果间隔是有规律的,每个观测单元应该用一个共同的区间进行测量。
price
我们首先为估计定义一个时间序列(ts)对象。请注意, ts 与 xts类似, 但没有日期和时间。
df <- ts(df) df

可扩展的时间序列数据xts
要处理高频数据(分秒),我们需要包 xts。该包定义可扩展时间序列 ( xts ) 对象。
以下代码安装并加载 xts 包。
library(xts)
考虑我们的可扩展时间序列的以下数据
date time price
现在我们准备定义 xts 对象。代码 as.POSIXct() 将字符串转换为带有分钟和秒的日期格式。
df <-data.frame df$daime <-paste df$dttime <-as.POSIXct df <- xts
对于仅使用日期的转换,我们使用 POSIXlt() 而不是 POSIXct()。
df$date <- as.POSIXct df$price <-as.numeric price <-xts
自回归移动平均模型arima
可以使用 arima() 函数估计自回归移动平均模型。
以下代码估计了一个 AR(1) 模型:
AR1

以下代码估计了一个 AR(2) 模型:
AR2 <- arima AR2

以下代码估计一个 MA(1) 模型:
MA1 <- arima MA1

以下代码估计一个 MA(2) 模型:
MA2 <- arima

以下代码估计了一个 ARMA(1,1) 模型:
ARMA11 <- arima


有时,我们只想保留系数。
coef #得到系数

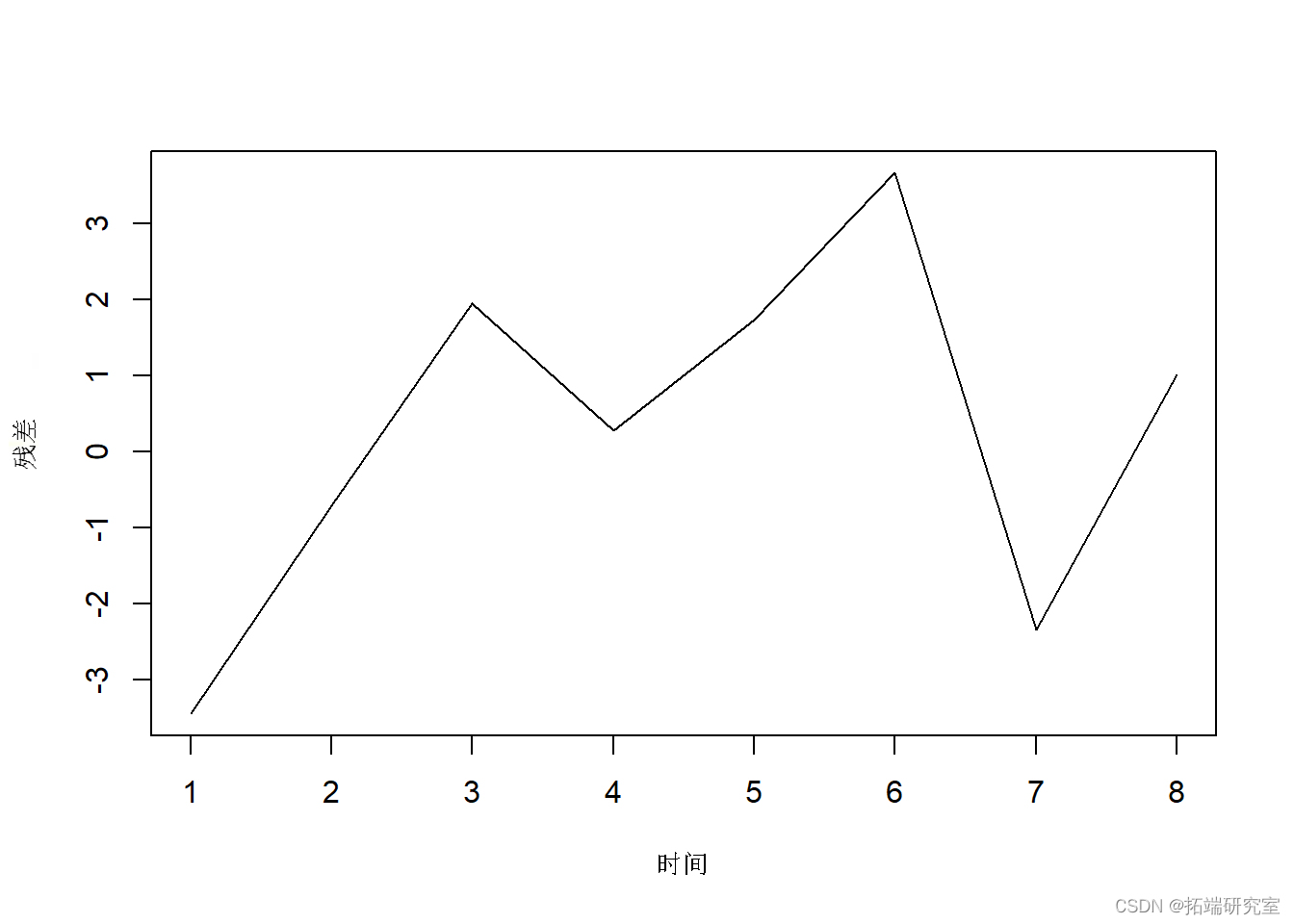
以下代码显示了残差图。
plot
随时关注您喜欢的主题
R 有一个方便的函数来 autofit() 拟合ARIMA 模型的参数。
现在寻找最好的 ARIMA 模型了。
autoarma

时间序列模型的一项重要功能是预测。以下代码给出了两步的预测:
teFoast <-predict
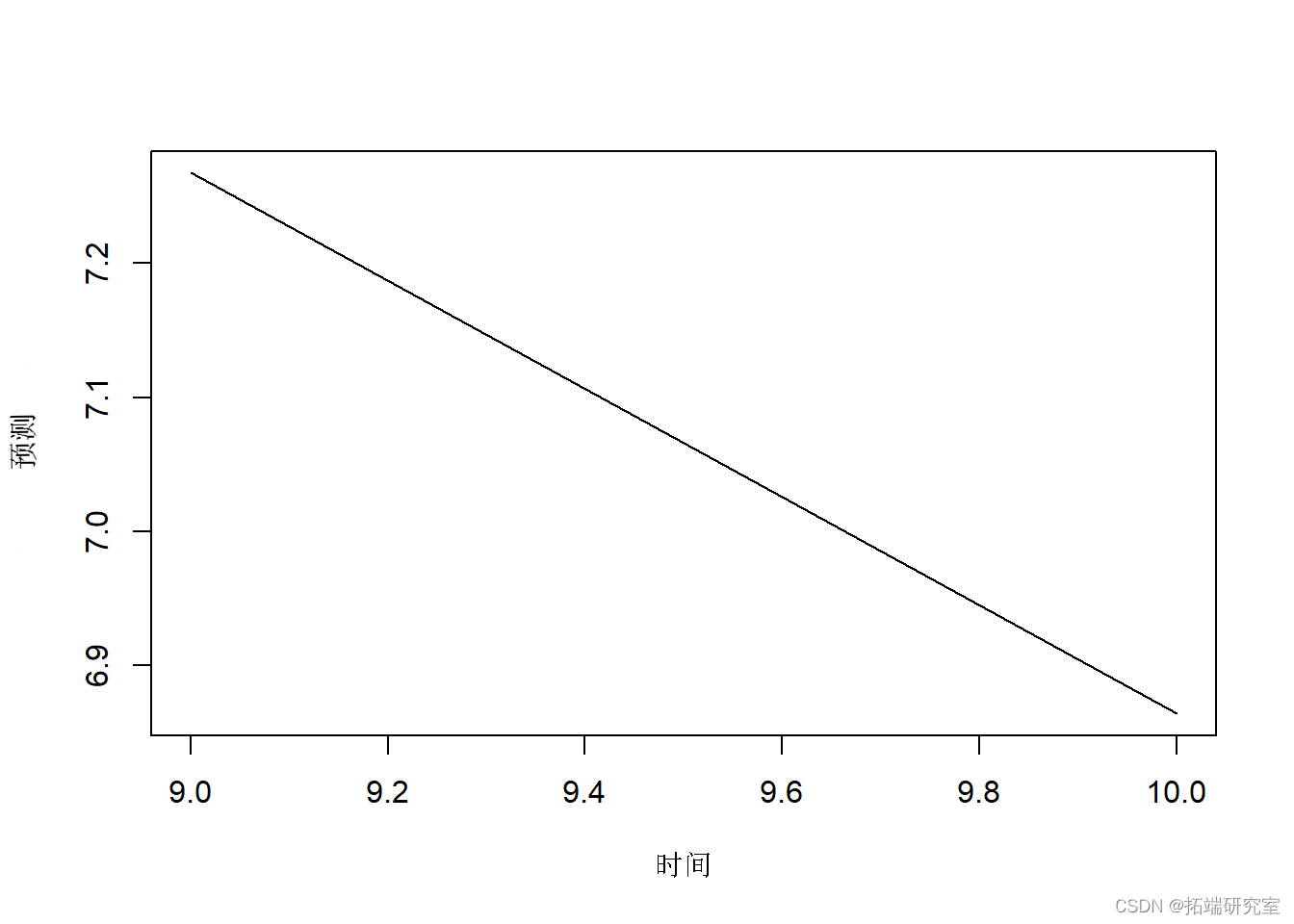
下面显示了预测图。
plot.ts#可视化预测
ARCH 和 GARCH模型
要估计 ARCH 和 GARCH 模型,我们需要安装和加载包 garch。
我们将在生成随机数时使用 ARMA(1,1) 估计 GARCH(1,1)
a <- runif #随机数 Spec <-ugarchspec
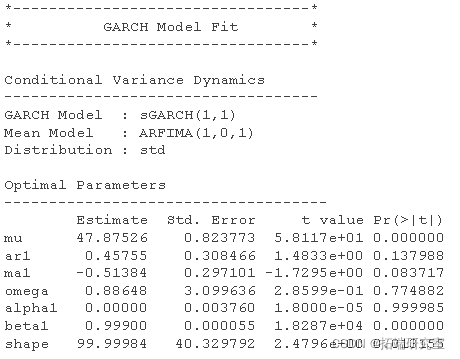
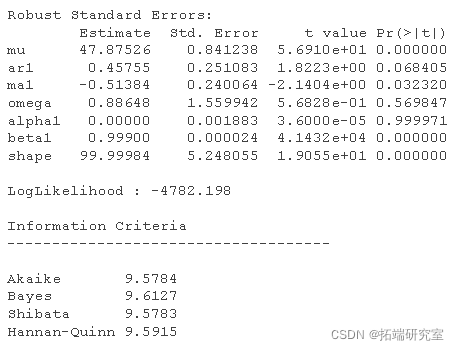
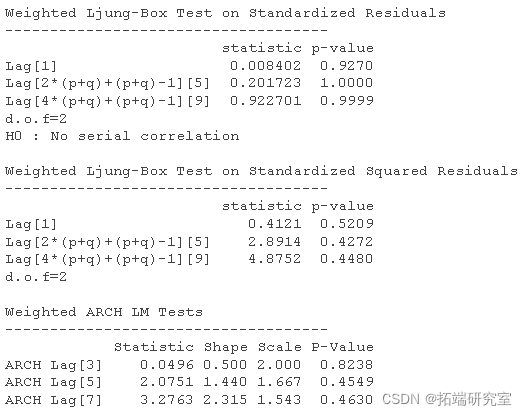

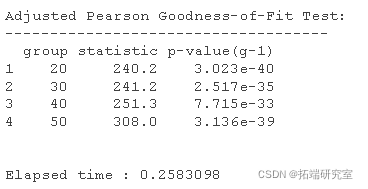
为了获得 GARCH 模型的具体结果,我们使用以下代码:
以下数据将用于估计 VAR 模型。
coffnt <-coef voy <- sigma logr.vrae <- uncvariance
VAR模型
要估计 VAR 模型,我们需要安装和加载 vars 。
以下代码估计 VAR(2) 模型。
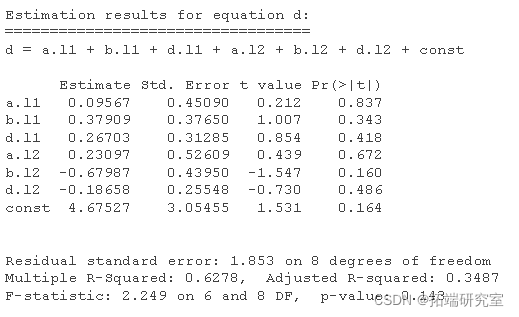
abr<-VAR #运行 VAR(2) coef #VAR的系数公式
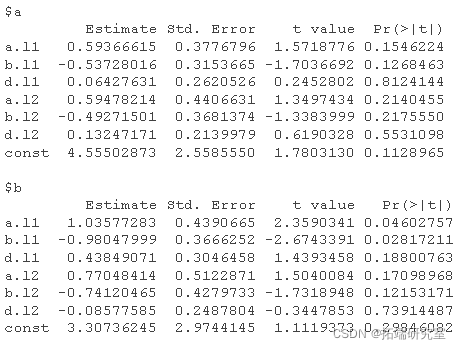
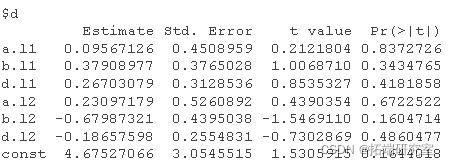
summary #VAR的摘要



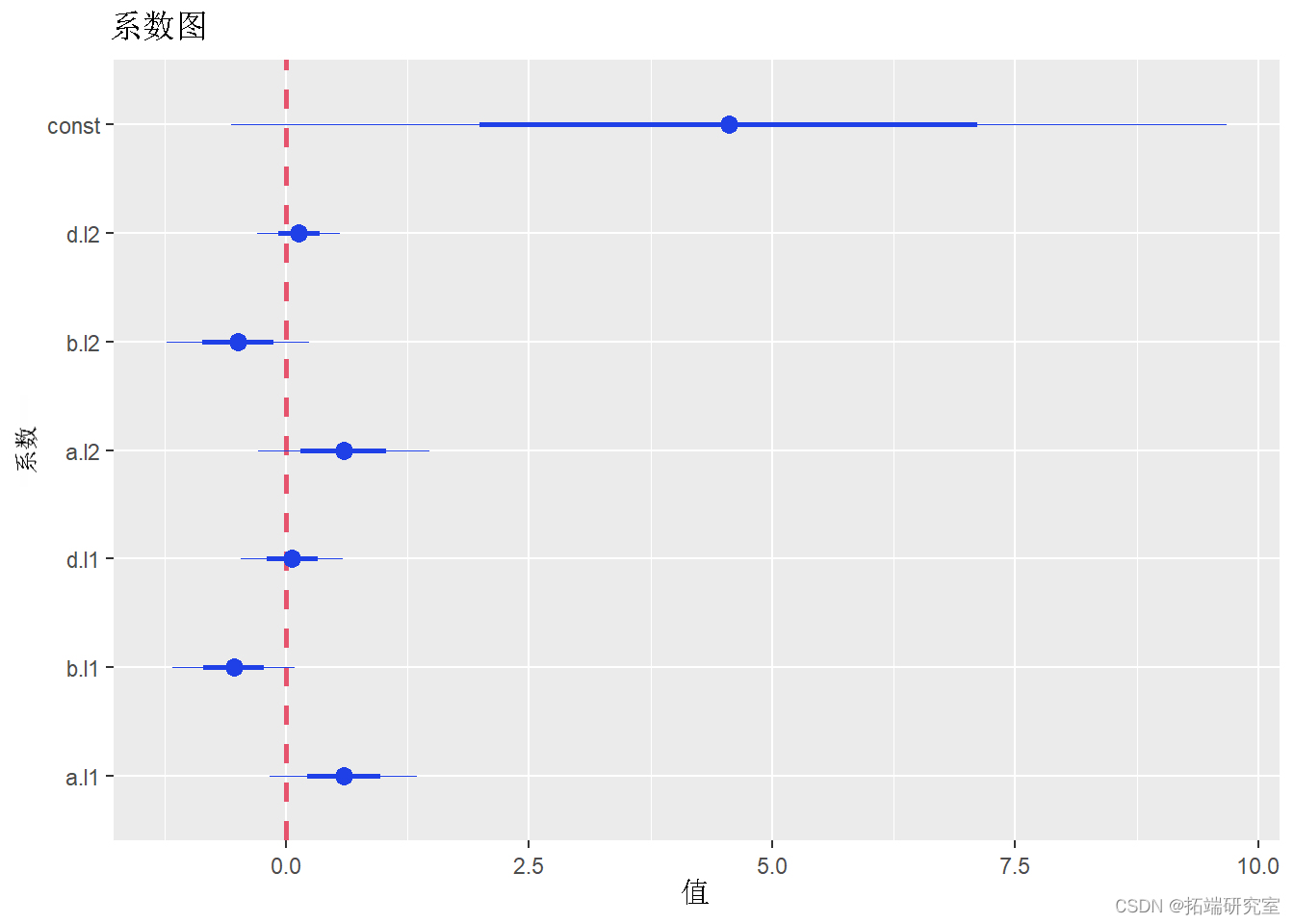
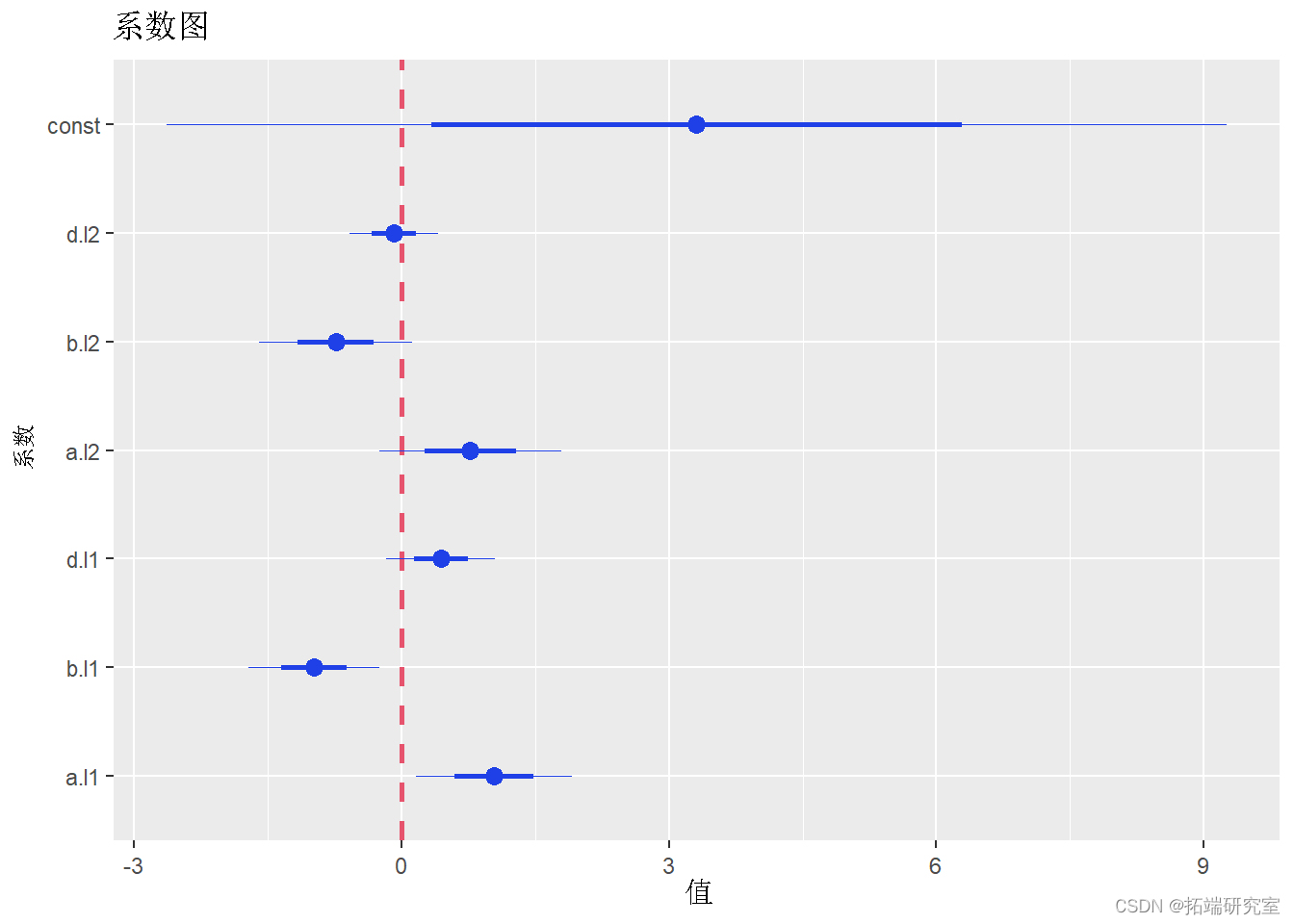
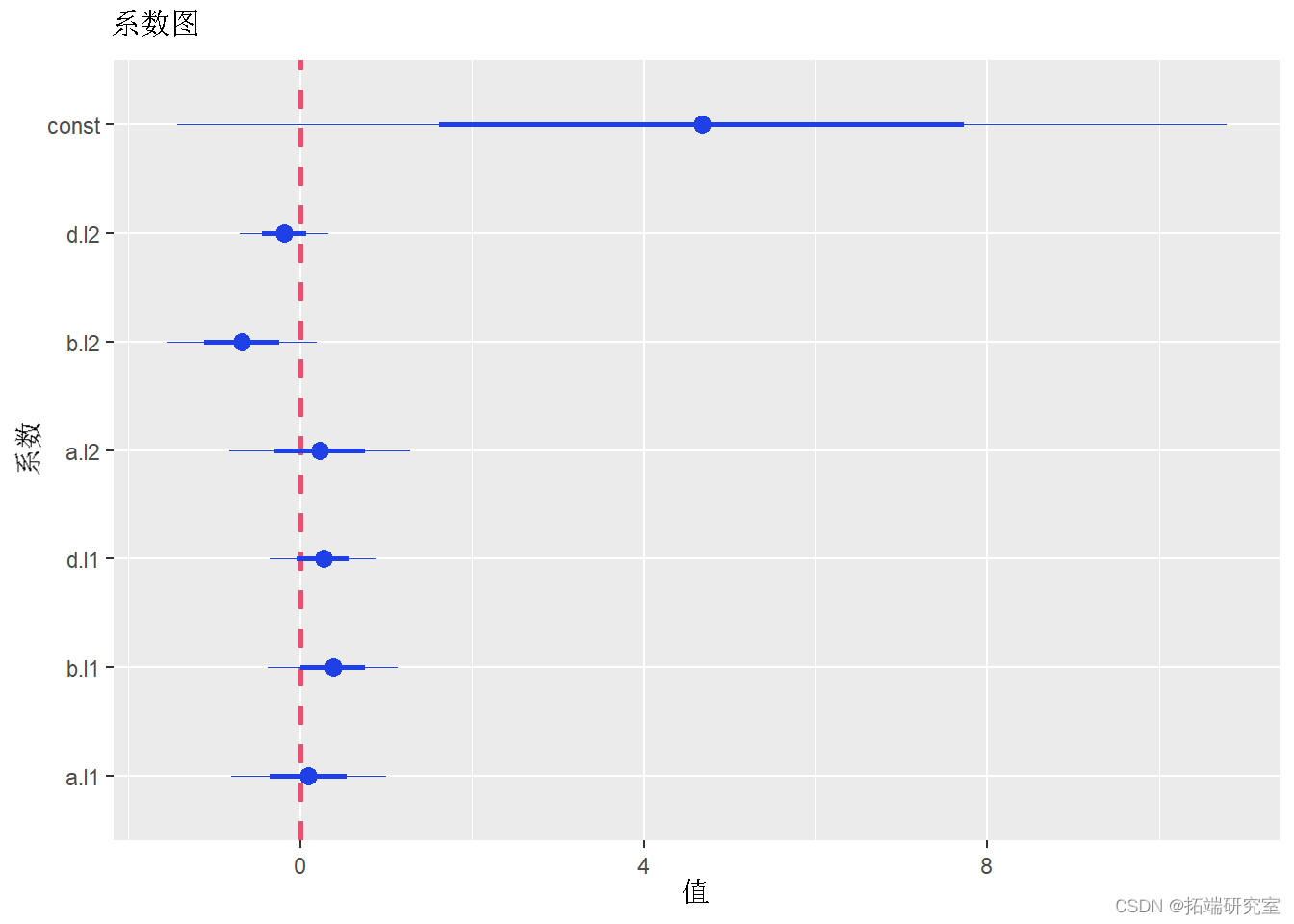
要生成系数图,我们需要安装并加载包:
以下代码为 VAR 模型生成系数图:
plot
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据

