本文演示了训练一个简单的卷积神经网络 (CNN) 来对 CIFAR 图像进行分类。
由于本教程使用 Keras Sequential API,因此创建和训练我们的模型只需几行代码。
设置
library(keras)
下载并准备 CIFAR10 数据集
可下载资源
CIFAR10 数据集包含 10 个类别的 60,000 张彩色图像,每个类别有 6,000 张图像。
数据集分为 50,000 张训练图像和 10,000 张测试图像。这些类是互斥的,它们之间没有重叠。
许多关于深度学习的图像分类的介绍都是从MNIST开始的,MNIST是一个手写数字的标准数据集。它不仅不会产生令人感叹的效果或展示深度学习的优点,而且它也可以用浅层机器学习技术解决。在这种情况下,普通的K近邻(KNN)算法会产生超过97%的精度(甚至在数据预处理的情况下达到99.5%)。此外,MNIST并不是一个典型的图像数据集——控制它不太可能教给你可迁移的技能,而这些技能对于其他分类问题是有用的。
如果你真的需要使用28×28灰度图像数据集,那么可以看看notMNIST数据集和一个MNIST-like fashion product数据集(一个非常有趣的数据集,也是10分类问题,不过是时尚相关的)。
验证数据
为了验证数据集看起来是否正确,让我们绘制训练集中的前 25 张图像并在每张图像下方显示类别名称。
train %>% map(as.rater, max = 255) %>%

创建卷积基
下面的6行代码使用一种常见的模式定义了卷积基础:Conv2D和MaxPooling2D层的堆叠。作为输入,CNN接受形状的张量(image\_height, image\_width, color\_channels),忽略了批次大小。如果你是第一次接触这些维度,color\_channels指的是(R,G,B)。在这个例子中,你将配置我们的CNN来处理形状为(32,32,3)的输入,这是CIFAR图像的格式。你可以通过将参数input_shape传递给我们的第一层来做到这一点。
kers\_moe\_etl %>% laer\_c\_2d(fles = 32, ene_sz = c(3,3), acan = "relu", lye\_apoi\_2d(posize = c(2,2)) %>% lae\_cv\_2d(filrs = 64, relze = c(3,3), ctitio = "reu")
到目前为止,让我们展示一下我们模型的架构。
summary(model)

在上面,你可以看到每个Conv2D和MaxPooling2D层的输出是一个三维形状的张量(高度、宽度、通道)。当你深入到网络中时,宽度和高度维度往往会缩小。每个Conv2D层的输出通道的数量由第一个参数控制(例如32或64)。通常情况下,随着宽度和高度的缩小,你可以承受(计算上)在每个Conv2D层中增加更多的输出通道。
在顶部添加密集层
为了完成我们的模型,您需要将卷积基(形状为 (3, 3, 64))的最后一个输出张量输入一个或多个 Dense 层以执行分类。密集层将向量作为输入(1D),而当前输出是 3D 张量。首先,您将 3D 输出展平(或展开)为 1D,然后在顶部添加一个或多个 Dense 层。CIFAR 有 10 个输出类,因此您使用具有 10 个输出和 softmax 激活的最终 Dense 层。
model %>% leree(unis = 64, aciaion = "relu") %>% ayedese(unis = 10, acivin = "sftax")
这是我们模型的完整架构。
注意 Keras 模型是可变对象,您不需要在上面的 chubnk 中重新分配模型。
summary(modl)

如您所见,我们的 (3, 3, 64) 输出在经过两个 Dense 层之前被展平为形状为 (576) 的向量。
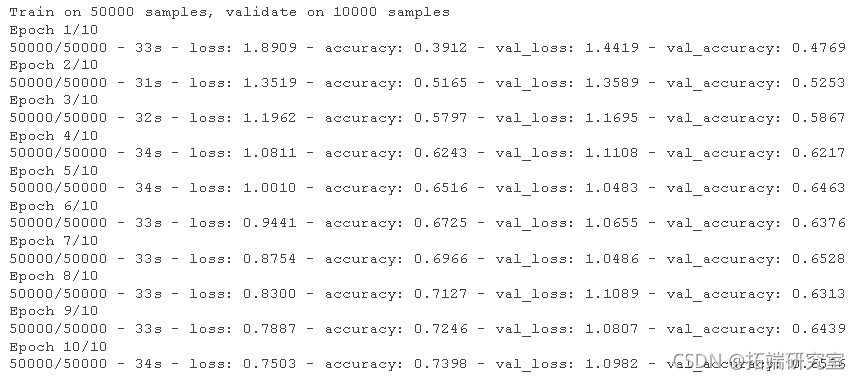
编译和训练模型
moel %>% comle( optier = "adam", lss = "specatialosnopy", mecs = "accray" )
评估模型
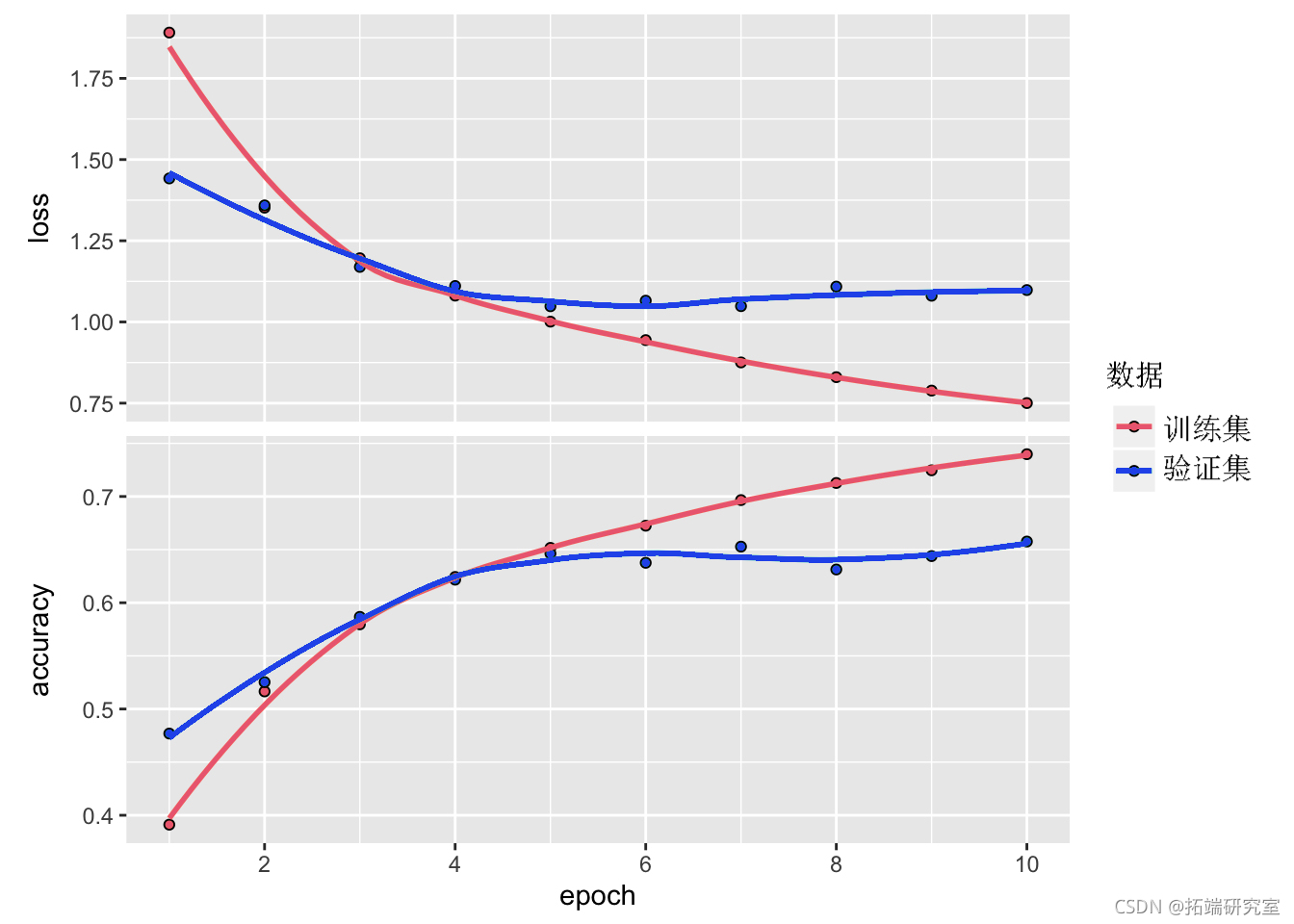
plot(hsy)

ealte(oel, x,y, erbe = 0)
随时关注您喜欢的主题

我们简单的 CNN 已经实现了超过 70% 的测试准确率。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据 PyTorch的Transformer与多头自注意力机制:序列反转与图像异常检测应用|附代码数据
PyTorch的Transformer与多头自注意力机制:序列反转与图像异常检测应用|附代码数据

