作为数据科学家,我们在做智能文本处理系统优化时,常被一个问题困扰:传统模型处理长序列时总像 “断了线的风筝”—— 要么记不住前文(如 RNN 的梯度消失),要么抓不住全局关联(如 CNN 的窗口局限)。
直到 2017 年 Transformer 模型出现,这种困局才被打破。它用自注意力机制让序列中每个元素 “主动对话”,既解决了并行计算效率问题,又能捕捉长距离语义关联,这正是它成为 NLP 及多模态领域基石的核心原因。
视频
视频:图解Transformer自注意力机制
1. Transformer核心架构:编解码器的“协作密码”
如果把Transformer比作“翻译工作室”,那编码器就是“读懂原文的译者”,解码器是“写出译文的译者”,两者靠注意力机制“传递信息”。
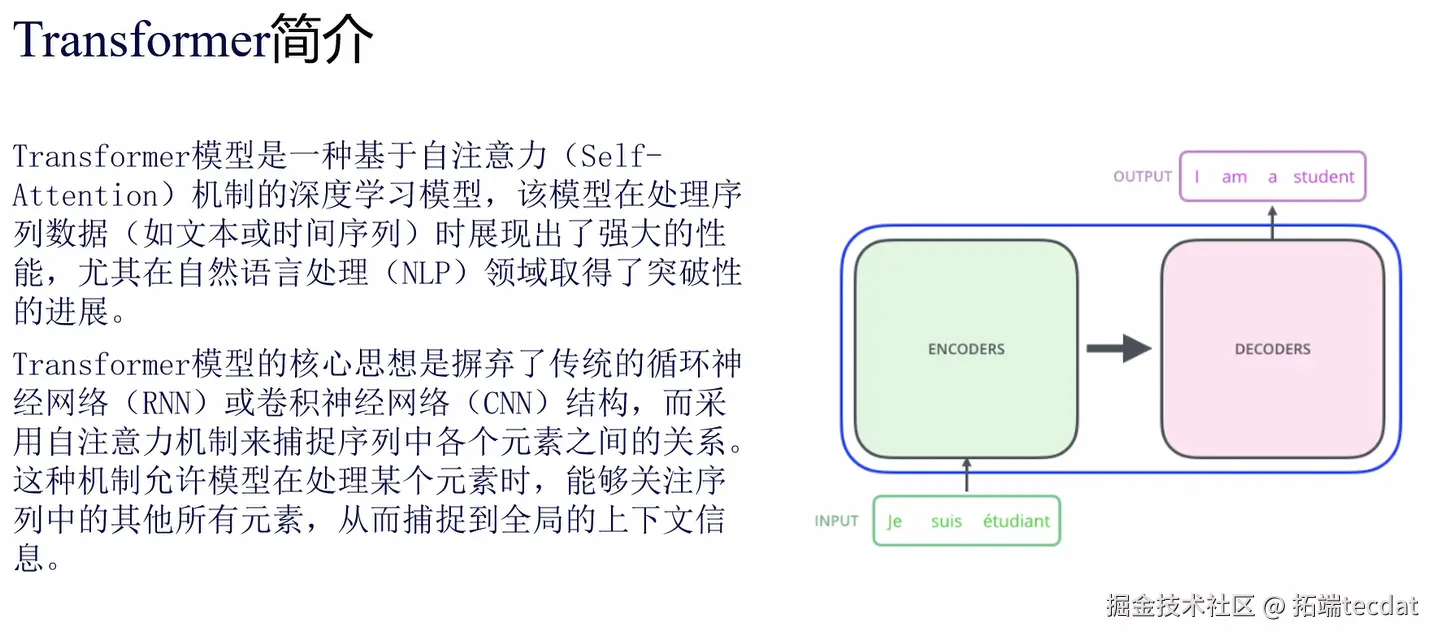
(1)堆叠结构:6+6的黄金组合
- 6个编码器串联:接力处理输入序列(比如法语“Je suis étudiant”),每层都在“深化理解”——从单个词的含义到句子逻辑。
- 6个解码器串联:接力生成输出序列(比如英语“I am a student”),每层都在“优化表达”——确保语法正确、语义连贯。
- 互联机制:编码器处理完的“理解结果”,通过注意力机制实时传给解码器(图2箭头就像“译者间的纸条”),让解码器生成时不偏离原文意思。
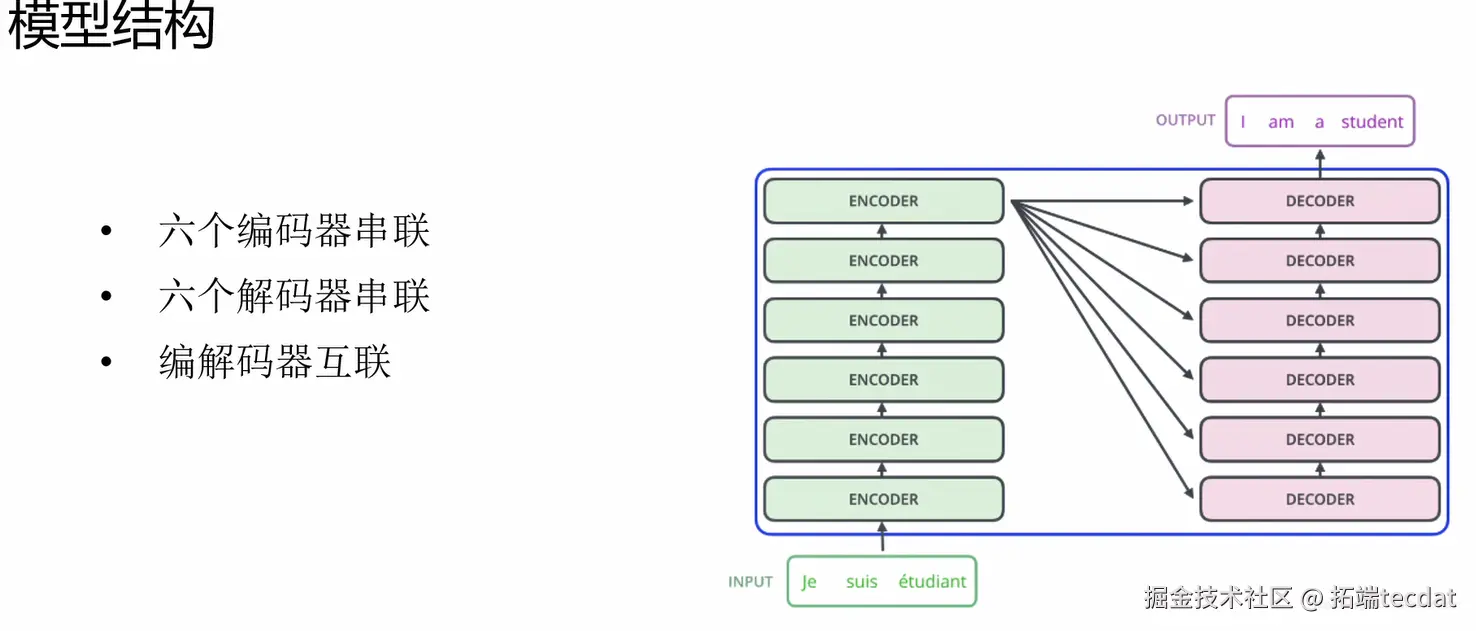
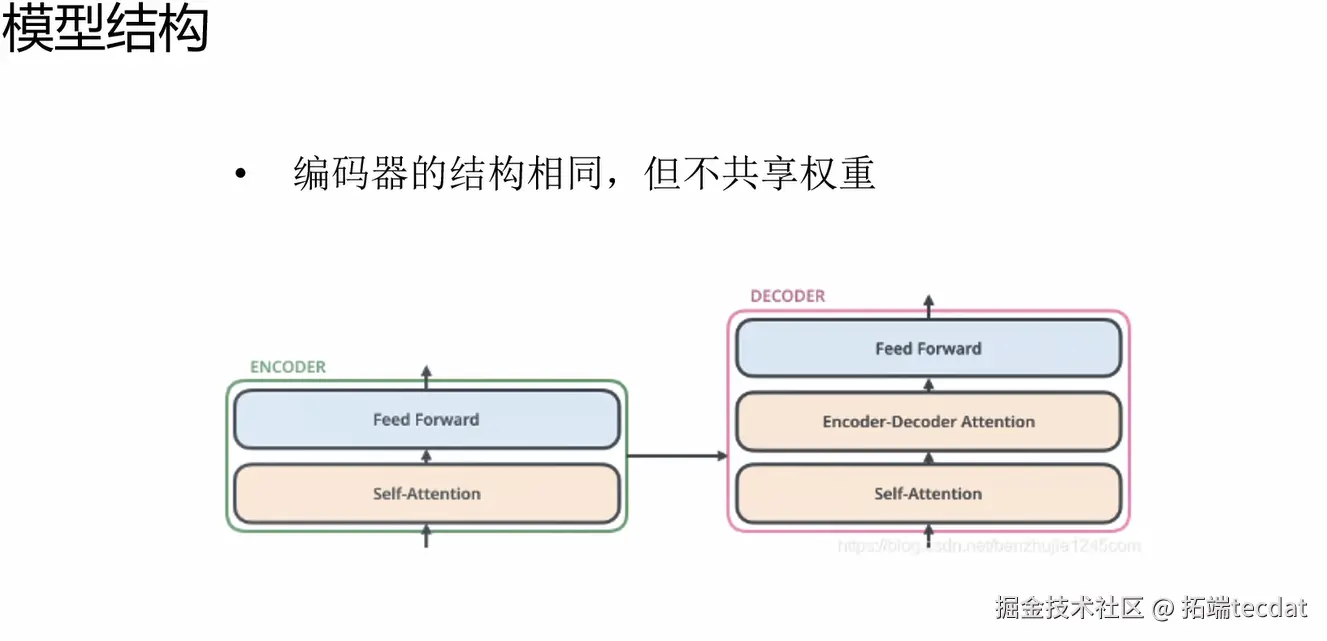
(2)核心组件:编码器与解码器的“差异武器”
Junwen Ge
可下载资源
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
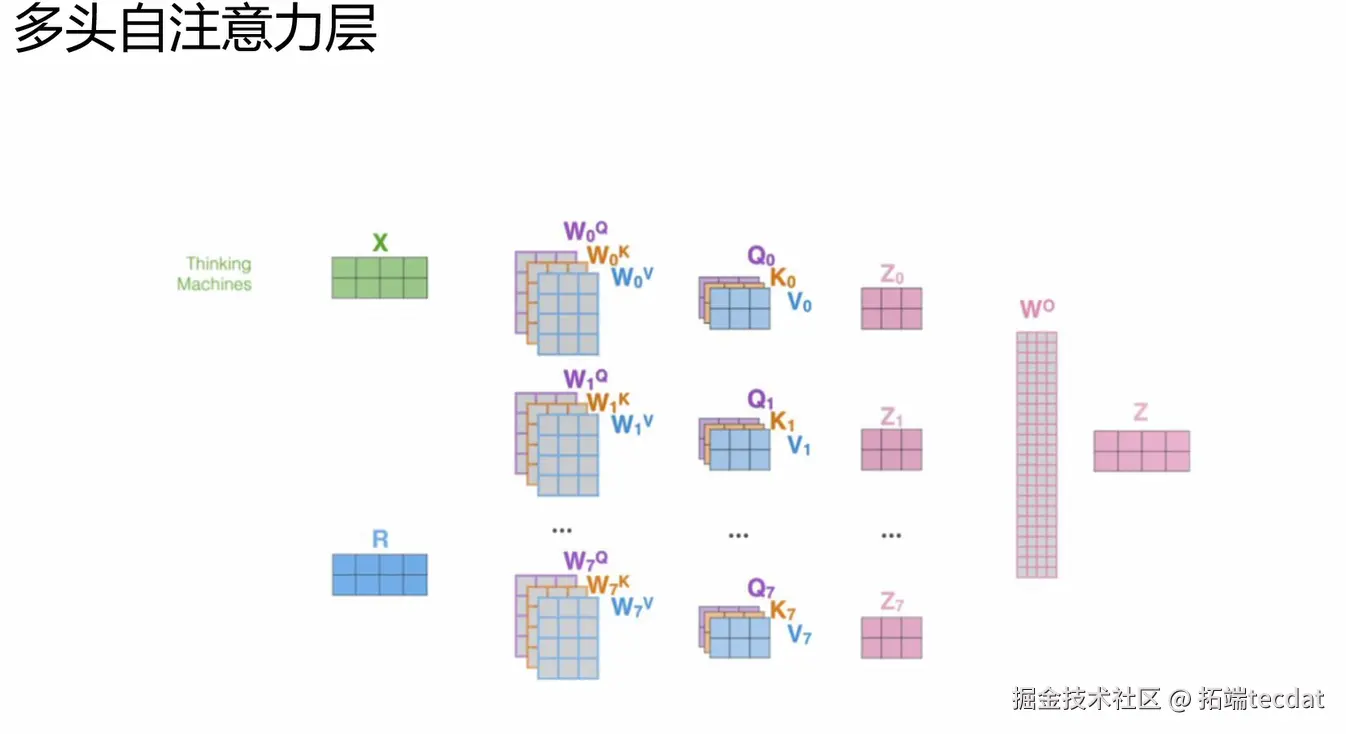
(1)计算流程:8头并行的“协作术”
- 输入“原料”:词向量矩阵X(比如“我爱中国”的向量表示)。
- 8头分工:
- 每头拿X“加工”出Q(查询:“我要找什么”)、K(键:“我是什么”)、V(值:“我的内容”),公式是
{Q_i,K_i,V_i} = X · {W_i^Q, W_i^K, W_i^V}。 - 算“关注度”:比如处理“我爱中国”,“我”对“爱”“中国”的关注度不同,公式是
Z_i = softmax( (Q_i×K_iᵀ)/√d_k )×V_i(√d_k是为了避免数值太大“冲乱结果”)。
- 汇总输出:把8头的结果(Z₀到Z₇)拼起来,再用矩阵Wᵒ“统一格式”,得到最终的注意力输出Z。
(2)创新价值:为什么要“多头”?
就像看一幅画,有人关注色彩,有人关注构图——多头设计让模型同时捕捉不同维度的信息(比如一句话里的“主谓关系”和“情感倾向”),比单头更全面。

3. 技术实现:从公式到落地的“修正手册”
正确流程和公式整理如下,用“翻译场景”举例说明:

随时关注您喜欢的主题
(1)公式修正
原公式extAttention_i = extsoftmax(extw_i extu_i)不准确,正确计算应为:Attention(Q,K,V) = softmax( (Q×Kᵀ)/√d_k )×V
(这里的Q、K、V就像“译文词”“原文词”“关联度”,softmax用来给每个关联打分,确保重要的关联分数高)。
(2)标准化步骤
- 输入处理:把句子拆成词(分词),再给每个词加“位置标签”(位置嵌入)——因为Transformer本身“不认顺序”,不加标签会把“我爱你”和“你爱我”弄混。
- 编码器加工:6层编码器接力“理解”,每层用自注意力整合上下文(比如“他说她没来”中,“她”关联“他提到的人”)。
- 解码器生成:6层解码器一边“自己检查通顺度”(自注意力),一边“回看编码器的理解”(Encoder-Decoder Attention),最后用前馈网络输出结果(比如翻译成“He said she didn’t come”)。
4. 应用场景:不止翻译,无处不在

Transformer就像“万能工具”,在多个领域解决实际问题:
| 领域 | 具体应用 | 案例说明 | 代表模型 |
|---|---|---|---|
| NLP | 机器翻译 | 某跨境电商用它做中英实时翻译,“这件衣服很适合你”不会译成“你很适合这件衣服” | BERT、GPT |
| 语音识别 | 语音转文字 | 手机语音助手用它把“明天开会吗”转成文字,准确率比老模型高15% | Whisper |
| 计算机视觉 | 图像分类 | 识别“猫”和“狗”时,能同时关注“耳朵形状”和“尾巴长度” | ViT、DETR |
| 强化学习 | 游戏策略学习 | 玩围棋时,能同时关注“当前落子”和“后续10步的可能性” | Transformer+RL |
关键优势:一套架构能搞定“文本、语音、图像”等不同数据,就像一把瑞士军刀,功能多还好用。
5. 模型演进:从“小个子”到“巨无霸”的瓶颈
(1)参数增长:越来越“聪明”也越来越“重”
用“大脑容量”类比,模型参数从2017年Transformer的0.05B(5千万)涨到2021年Switch Transformer的1.6T(1.6万亿),就像从“小学生”到“博士生”,但也更“费资源”。
gantt
title NLP模型参数规模变化(单位:B)
axisFormat %Y
2017 : 0, 0.05(Transformer)
2018 : 0, 0.11(GPT), 0.34(BERT)
2019 : 0, 1.5(GPT-2), 8.3(MegatronLM)
2020 : 0, 17(T-NLG), 170(GPT-3)
2021 : 0, 1600(Switch Transformer) # 1.6T即1600B
(2)优缺点分明
- 优势:比RNN快(能同时处理所有词,不用排队),能记住长句子里的“前因后果”(比如1000字文章里的“问题”和“答案”)。
- 瓶颈:长文本处理费劲(超过512个词要“砍断”),参数太多“跑不动”(1.6T参数的模型,普通电脑根本装不下)。
结论建议:选对模型,用好工具
- 选型窍门:中小公司做客服机器人、简单翻译,用BERT或小参数GPT就够;处理长文本(如论文、小说),试试Reformer(支持更长序列)。
- 落地技巧:把大模型“瘦身后再用”(知识蒸馏,比如TinyBERT),能让手机、小程序也跑得动。
- 关注前沿:多模态Transformer(比如CLIP,能同时看懂图和文字)和“稀疏注意力”(只关注重要信息,省资源)是未来方向。
如果想深入了解某部分(比如位置嵌入的具体算法),可以留言,我们会针对性拆解。
关于分析师
Junwen Ge
在此对 Junwen Ge 对本文所作的贡献表示诚挚感谢,他专注于数据科学与大数据技术领域。擅长 Python、MySQL 等工具,在数据处理、数据分析等方面拥有扎实的专业能力。Junwen Ge 深耕数据科学领域,在帮助客户解决数据处理难题、优化数据分析流程、挖掘数据潜在价值等方面拥有丰富的实践经验,尤其擅长结合业务场景构建高效的数据处理与分析方案,为决策提供数据支持。
 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据



