
在信息爆炸时代,“信用”已成为越来越重要的无形财产。
数据风控“的实际意义是用DT(Data Technology)识别欺诈,将欺诈防患于未然,然后净化信用体系。
可下载资源
挑战
信贷风险和欺诈风险是消费金融业务发展中最重要的两种风险,信息不对称是导致这些风险的主要原因。
“ 数据防欺诈”是数据风控武器之一。这种武器的力量的重要保证是数据和信息收集的完整性和准确性。通过这些有价值的数据,找到欺诈者留下的线索,以防止发生欺诈。
“随着技术不断演进,针对金融业的攻击、欺诈手段已不同以往。团伙作案、分工明确、掌握各种先进技术工具、不断变化攻击手段,全新挑战使得金融企业越来越难以招架。”金融反欺诈期待创新已成业内共识。
“无监督机器学习是近年才发展起来的反欺诈手法。目前国内反欺诈金融服务主要是应用黑白名单、有监督学习和无监督机器学习的方法来实现。”
实施过程
用户立体化呈现——多维数据采集
深入分析用户的基本属性、社会属性、消费者行为、兴趣偏好、社会偏好、资产特征、信用特征等数据,通过数据挖掘,使用户更加立体化地实时呈现。
挖掘潜在的团伙欺诈——社区发现算法
一方面,基于机构的存量数据,运营商等数据构建复杂的网络。同时,采用社区挖掘算法实现风险分组。 在此基础上,我们训练机器学习模型。


建模的原材料 —— 特征工程
建模的第一步是特征工程,众所周知,特征是机器学习建模的原材料,对最终模型的影响至关重要。数据和特征比模型更重要,数据和特征决定了机器学习的上限,而模型和算法逼近这个上限。特征加工和衍生工作越完备,那么构建的机器学习模型效果越好。但是,面对不同数据,不同业务场景,特征加工衍生往往是最耗时间与资源的工作。
尤其在弱数据方面,充斥着大量文本、时序类数据,人工特征定义的方法天然存在较大局限性。
tecdat引入基于机器学习的特征提取框架(如 random forest,SVM,CNN)来适应不同的数据类型,自动从大量复杂的非结构化数据中产生高质量的特征,完成模型训练后可以输出特征的重要性,结合多种方法进行特征选择和解释。
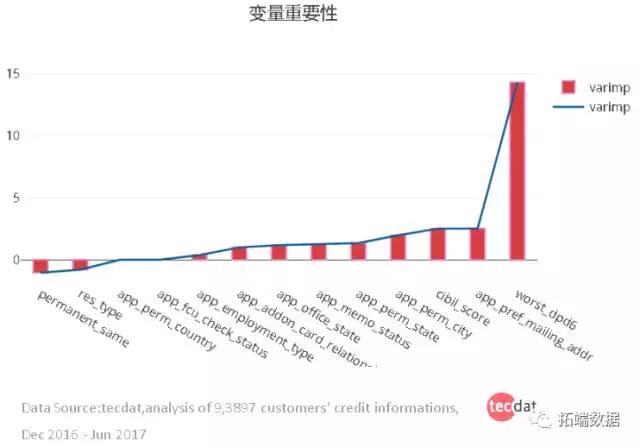
和而不同——集成模型
具体的模型,我们知道在弱势数据的基础上加工和衍生的特点,机构往往面临很多特征维度,从数千到数万以上,非常稀疏。超出了传统风控的基于评分卡系统的建模能力。
tecdat引入集成模型(ensemble models)来解决这个问题。集成模型从“投票”的思想简单的理解,也就是我们对不同类型的数据使用最合适的子模型(Logistic回归,GBDT,CNN,xgboost), 然后每个子模式投票作出决策。
能够使整体模型的准确度和防止过拟合的能力达到协调,从而达到在总体上的最佳准确度。
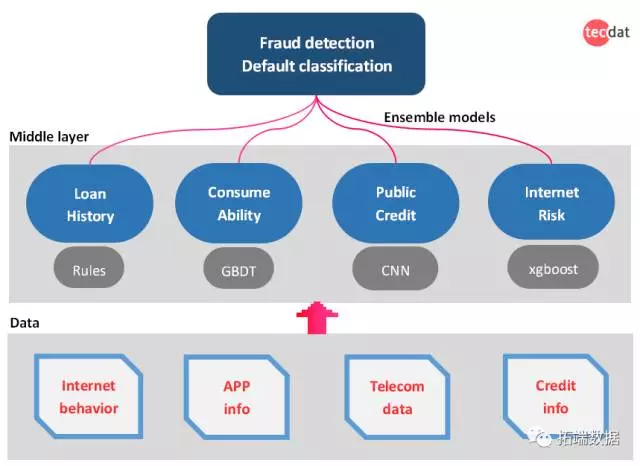
复杂的集成模式框架除了当前场景和业务建模具有很好的表现,其另一个重要价值在于可以快速应用于新业务应用,对“冷启动“阶段有非常重要的作用。
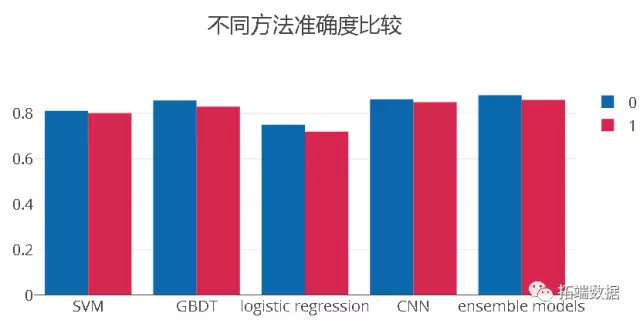
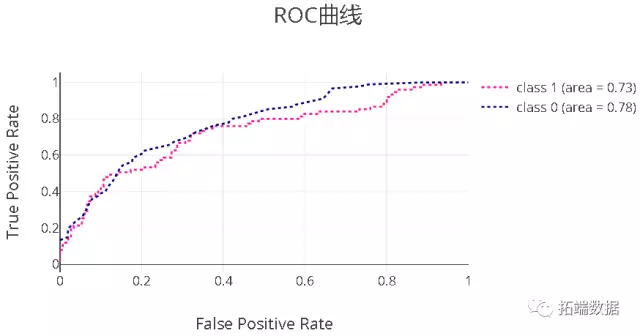
结果/效果总结
最后,在线上信用贷场景实践下来,经过多批次多个跨时间段的验证,可以看到,效果上还是有非常直接的提升,模型性能相比传统模型提升了大约30%。
 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究 Python与MySQL网站排名数据分析及多层感知机MLP、机器学习优化策略和地理可视化应用
Python与MySQL网站排名数据分析及多层感知机MLP、机器学习优化策略和地理可视化应用 【梯度提升专题】XGBoost、Adaboost、CatBoost预测合集:抗乳腺癌药物优化、信贷风控、比特币应用|附数据代码
【梯度提升专题】XGBoost、Adaboost、CatBoost预测合集:抗乳腺癌药物优化、信贷风控、比特币应用|附数据代码 银行信贷风控专题:Python、R 语言机器学习数据挖掘应用实例合集:xgboost、决策树、随机森林、贝叶斯等
银行信贷风控专题:Python、R 语言机器学习数据挖掘应用实例合集:xgboost、决策树、随机森林、贝叶斯等



