
神经网络作为一种强大的机器学习算法,具有强大的非线性映射和学习能力,能够处理复杂的模式识别和数据分类问题。
在亚马逊评论分析和学生成绩分析中,BP神经网络能够基于填充后的完整数据,提取出隐藏在数据中的有用信息,进而实现关键词识别、成绩预测等目标。
鉴于此,本文将通过两个R语言案例——亚马逊评论分析和学生成绩分析,展示随机森林填充缺失值和BP神经网络在数据分析中的应用。
我们将分别介绍两个案例的背景、数据预处理过程、缺失值处理方法以及BP神经网络模型的构建和应用。通过这两个案例的对比分析,我们将进一步探讨随机森林和BP神经网络在不同领域数据分析中的优势、挑战和潜在改进方向。
作者

可下载资源
案例1:随机森林填充缺失值、BP神经网络在亚马逊评论分析
在数字化时代,亚马逊商业网站作为全球领先的电商平台,其客户评论不仅为消费者提供了宝贵的购物参考,同时也为企业分析市场需求、改进产品服务提供了重要的数据来源。然而,由于各种因素的影响,客户评论中往往存在缺失值问题,这在一定程度上影响了数据分析的准确性和可靠性。因此,如何有效地处理缺失值,提高数据分析的质量,成为当前研究的热点之一。
读取数据并进行缺失值处理
在数据分析的过程中,经常会遇到数据集中包含缺失值的情况。缺失值可能是由于各种原因造成的,例如数据采集时的遗漏、设备故障或者数据录入错误等。为了确保分析的准确性和可靠性,必须对缺失值进行适当的处理。本文将介绍三种常见的缺失值处理方法,并演示如何在R语言中实现这些方法。
一、读取数据
数据集来源于亚马逊商业网站上客户的评论,用于识别作者身份。
大多数先前的研究针对两到十名作者进行了识别实验。但在网络环境中,需要识别的评论通常有更多潜在的作者,并且通常情况下分类算法并不适应于大量目标类别的分类。
视频
LSTM神经网络架构和原理及其在Python中的预测应用
视频
人工神经网络ANN中的前向传播和R语言分析学生成绩数据案例
视频
CNN(卷积神经网络)模型以及R语言实现
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
视频
为什么要处理缺失数据?如何R语言中进行缺失值填充?
为了检验分类算法的稳健性,我们确定了50位最活跃的用户(通过唯一ID和用户名表示),这些用户在这些新闻组中经常发表评论。我们为每个作者收集的评论数量是30条。
变量包括作者的语言风格,如数字的使用、标点符号、单词和句子的长度以及单词的使用频率等。
首先,我们需要从某个数据源中读取数据。这可以通过使用R语言中的相关函数来完成,具体取决于数据的存储格式。例如,如果数据存储在CSV文件中,我们可以使用read.csv()函数来读取数据。
二、缺失值处理
(1)删除法
删除法是最简单的缺失值处理方法之一。它的基本思想是直接删除包含缺失值的行或列。在R语言中,我们可以使用na.omit()函数来删除包含缺失值的行。但是需要注意的是,这种方法可能会导致数据量的减少,从而可能影响分析结果的准确性。
data1=na.omit(data)
data1
(2)平均值补缺
平均值补缺法是一种常用的缺失值处理方法。它的基本思想是用某一列的平均值来填补该列中的缺失值。在R语言中,我们可以通过遍历每一列并计算其非缺失值的平均值来实现这一方法。但是需要注意的是,这种方法假设缺失值是随机分布的,并且该列的数据符合某种分布(如正态分布)。如果这些假设不成立,那么填补的结果可能会引入偏差。
data2=data
for(i in 1:(ncol(data)-1)){
(3)多重补插法
多重补插法是一种更复杂的缺失值处理方法。它的基本思想是通过建立一个或多个预测模型来预测缺失值。在R语言中,我们可以使用mice包中的mice()函数来实现多重补插法。这个函数会根据数据的分布和相关性来建立预测模型,并生成多个完整的数据集。然后,我们可以使用complete()函数来选择其中一个完整的数据集进行后续分析。需要注意的是,这种方法需要较大的计算量,并且需要选择合适的预测模型来确保填补的准确性。
变量筛选及其在数据分析中的应用
在数据分析过程中,变量筛选是一个至关重要的步骤。通过筛选变量,我们可以去除那些对模型贡献较小或者与预测目标不相关的变量,从而提高模型的准确性和解释性。本文将介绍使用lasso算法进行变量筛选的方法,并通过实际代码展示如何在R语言中进行操作。
一、变量筛选方法概述
变量筛选的方法多种多样,其中lasso算法是一种常用的方法。Lasso算法是一种线性回归的扩展,它通过添加正则化项来限制模型复杂度,并对系数进行压缩。在lasso回归中,一些系数可能会被压缩至零,从而实现了变量的自动筛选。
二、使用lasso算法进行变量筛选
1. 数据准备
首先,我们需要准备数据集data2。由于我们的目标是使用lasso算法对变量进行筛选,我们需要确保数据集中包含目标变量和潜在的自变量。在这个例子中,我们假设目标变量是V10001。
接下来,我们将数据集划分为训练集和测试集。这里我们使用80%的数据作为训练集,剩余的20%作为测试集(尽管在变量筛选阶段通常只使用训练集)。
##设置训练集比例
train <- 1:ncol(data2.train))data2.train[,i]=as.numeric(data2.train[,i])
data2.train=na.omit(data2.train)
2. 构建模型矩阵
接下来,我们需要为目标变量和自变量构建一个模型矩阵。在这个例子中,我们使用model.matrix()函数来构建矩阵,其中目标变量是V10001,自变量则是除V10001外的所有其他变量。
xmat <- model.matrix( V10001~. , data = data2.train )
3. 执行lasso回归
然后,我们使用cv.glmnet()函数执行交叉验证的lasso回归。通过设置alpha参数为0.3,我们使用了介于岭回归(alpha=0)和lasso回归(alpha=1)之间的弹性网络回归。
cv.lasso <- cv.glmn
plot(cv.sso)
coef(cv.laslambda.1se")
4. 选择最优模型
最后,我们可以根据交叉验证的结果选择最优的模型。这通常是通过选择交叉验证误差最小的λ值来实现的。一旦确定了λ值,我们就可以提取出对应的系数,并据此确定哪些变量被选入模型。
##找出lamda时最小对应的系数不为0的变量为最优变量
c<-co=TRUE)
inds<-which(c!=0)
根据lasso筛选出最优的变量
set.seed(11)
variables<-row.names(c)[inds]
variables
##因此最优变量如下所示
使用随机森林填充缺失值的方法及其应用
在数据分析过程中,缺失值是经常遇到的问题。为了保持数据的完整性和分析的准确性,我们需要对缺失值进行填充。本文介绍了使用随机森林算法对缺失值进行填充的方法,并通过具体示例展示了该方法的操作步骤。
随时关注您喜欢的主题
识别缺失值
使用R语言的is.na()函数可以识别出V10001中的缺失值,并通过which()函数获取这些缺失值的索引。 notna=which(is.na(data2$V10001))
建立随机森林模型
接下来,我们使用randomForest()函数建立随机森林模型。模型的构建基于除了缺失值以外的其他变量(如V3351、V6732等)。在建立模型时,我们可以通过调整参数(如ntree、mtry、nodesize等)来优化模型的性能。
rf <- randomFor42, importance=T)
预测缺失值
使用predict()函数,我们可以基于建立的随机森林模型对包含缺失值的样本进行预测。这些预测值将作为缺失值的填充值。
填充缺失值
最后,我们将预测得到的值填充到原始数据集的相应位置。
data2[notna,]$V10001=pred
data2=data2[complete.cases(data2),]
使用BP神经网络进行建模与应用分析
BP神经网络作为一种有效的机器学习工具,能够处理复杂的非线性关系,并在许多领域得到了广泛应用。本文首先介绍了BP神经网络的基本原理,然后详细描述了使用BP神经网络进行建模的步骤,并通过绘制原始数据和拟合数据的图形对比,以及分类混淆矩阵的分析,对建模结果进行了评估。
我们使用了数据集data2,其中包含多个特征变量和一个目标变量V10001。首先,我们将特征变量提取出来作为训练数据train,并将目标变量作为目标值targets。
train=data2[,c("V3351" ,"V6732" , "V7121" , "V7892" ,"V8822" ,"V9466" )]
targets=data2$V10001
数据处理
为了将目标值转换为适合神经网络处理的形式,我们使用class.ind()函数将其转换为指示矩阵。这样,每个目标值都被表示为一个长度为类别数的向量,其中对应类别的位置为1,其余位置为0。#使用神经网络对训练结果进行集成 targets=class.ind(targets)
建立BP神经网络模型
我们使用nnet()函数建立BP神经网络模型。该函数允许我们指定网络的大小(即隐藏层神经元数量)以及其他参数。在本例中,我们设置隐藏层神经元数量为2,并允许网络进行多次迭代以达到收敛。
模型评估
通过summary()函数,我们可以查看模型的详细信息,包括网络结构、权重和训练过程中的收敛情况等。此外,我们还绘制了原始数据和拟合数据的图形对比,以直观展示模型的拟合效果。最后,我们计算了分类混淆矩阵,以评估模型在分类任务上的性能。
#绘制拟合数据
points(train[,"V3[1:nrow(train)] , col = "red", pch=4)
tab=table(pre,train[,"V3351"])#分类混淆矩阵
tab
结果与讨论
通过BP神经网络模型的建立和评估,我们得到了以下结果:
- 模型结构为一个6-2-50的网络,共有164个权重。
- 在训练过程中,初始值较大,但经过多次迭代后逐渐收敛到一个较小的值。
- 通过绘制原始数据和拟合数据的图形对比,我们发现模型能够较好地拟合原始数据的变化趋势。
- 分类混淆矩阵显示,模型在分类任务上具有一定的准确性,但仍然存在一些误分类的情况。这可能是由于数据噪声、模型复杂度不足或训练数据不足等原因导致的。
需要注意的是,BP神经网络的性能受到多种因素的影响,包括网络结构、训练算法、学习率等。在实际应用中,我们需要根据具体问题选择合适的参数和配置,以获得更好的建模效果。
案例2:R语言中的BP神经网络模型分析学生成绩
最近我们被客户要求撰写关于BP神经网络的研究报告。在本教程中,您将学习如何在R中创建神经网络模型。神经网络(或人工神经网络)具有通过样本进行学习的能力。人工神经网络是一种受生物神经元系统启发的信息处理模型。
它由大量高度互连的处理元件(称为神经元)组成,以解决问题。它遵循非线性路径,并在整个节点中并行处理信息。神经网络是一个复杂的自适应系统。自适应意味着它可以通过调整输入权重来更改其内部结构。
模式识别诞生于20实际20年代,随着40年代计算机的出现,50年代人工智能的兴起,模式识别在60年代初迅速发展成为一门学科。简单点说,模式识别是根据输入的原始数据对齐进行各种分析判断,从而得到其类别属性,特征判断的过程。为了具备这种能力,人类在过去的几千万年里,通过对大量事物的认知和理解,逐步进化出了高度复杂的神经和认知系统。举例来说,我们能够轻易的判别出哪个是钥匙、哪个是锁,哪个是自行车、哪个是摩托车;而这些看似简单的过程,其背后实际上隐藏着非常复杂的处理机制。而弄清楚这些机制的作用机理正是模式识别的基本任务。
那么,到底什么是模式呢?广义地说,模式是存在于时间和空间中的可观察的事物,如果我们可以区别它们是否相同或者是否相似,那我们从这种事物所获取的信息就可以称之为模式。人们为了掌握客观的事物,往往会按照事物的相似程度组成类别,而模式识别的作用和目的就在于把某一个具体的事物正确的归入某一个类别。
下面我们举一些例子来说明,到底哪些是模式识别的范畴:
1.将铅笔、钢笔、圆珠笔、毛笔、彩笔都归类为书写用的“笔”;
2.医生根据心电图化验单来判断病人是否得心脏病;
3.警察根据指纹来进行身份验证;
4.利用计算机进行字符识别;
5.根据用户的虹膜进行身份识别;
6.判断当前用户发出的声音是什么字符;
7.判断当前图片中是否有行人、人脸、车辆等;
8.对出现在图片序列中的行人、车辆进行跟踪;
9.对图片中的人脸进行身份识别验证;
10.对车辆的拍照进行识别;
11.判断车辆的颜色、车型;
12.在海量图片库当中寻找与某一张图片相似的若干图片;
13.根据用户哼唱的音调搜索对应的歌曲;
该神经网络旨在解决人类容易遇到的问题和机器难以解决的问题,例如识别猫和狗的图片,识别编号的图片。这些问题通常称为模式识别。它的应用范围从光学字符识别到目标检测。
本教程将涵盖以下主题:
- 神经网络概论
- 正向传播和反向传播
- 激活函数
- R中神经网络的实现
- 案例
- 利弊
- 结论
神经网络概论
神经网络是受人脑启发执行特定任务的算法。它是一组连接的输入/输出单元,其中每个连接都具有与之关联的权重。在学习阶段,网络通过调整权重进行学习,来预测给定输入的正确类别标签。
人脑由数十亿个处理信息的神经细胞组成。每个神经细胞都认为是一个简单的处理系统。被称为生物神经网络的神经元通过电信号传输信息。
这种并行的交互系统使大脑能够思考和处理信息。一个神经元的树突接收来自另一个神经元的输入信号,并根据这些输入将输出响应到某个其他神经元的轴突。
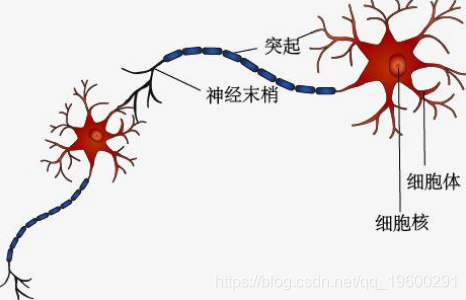
树突接收来自其他神经元的信号。单元体将所有输入信号求和以生成输出。当总和达到阈值时通过轴突输出。突触是神经元相互作用的一个点。它将电化学信号传输到另一个神经元。
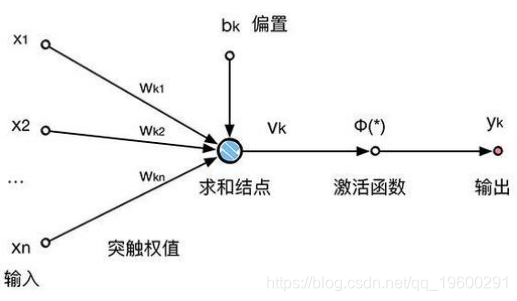
x1,x2 …. xn是输入变量。w1,w2 …. wn是各个输入的权重。b是偏差,将其与加权输入相加即可形成输入。偏差和权重都是神经元的可调整参数。使用一些学习规则来调整参数。神经元的输出范围可以从-inf到+ inf。神经元不知道边界。因此,我们需要神经元的输入和输出之间的映射机制。将输入映射到输出的这种机制称为激活函数。
前馈和反馈人工神经网络
人工神经网络主要有两种类型:前馈和反馈人工神经网络。前馈神经网络是非递归网络。该层中的神经元仅与下一层中的神经元相连,并且它们不形成循环。在前馈中,信号仅在一个方向上流向输出层。

反馈神经网络包含循环。通过在网络中引入环路,信号可以双向传播。反馈周期会导致网络行为根据其输入随时间变化。反馈神经网络也称为递归神经网络。
激活函数
激活函数定义神经元的输出。激活函数使神经网络具有非线性和可表达性。有许多激活函数:
随时关注您喜欢的主题
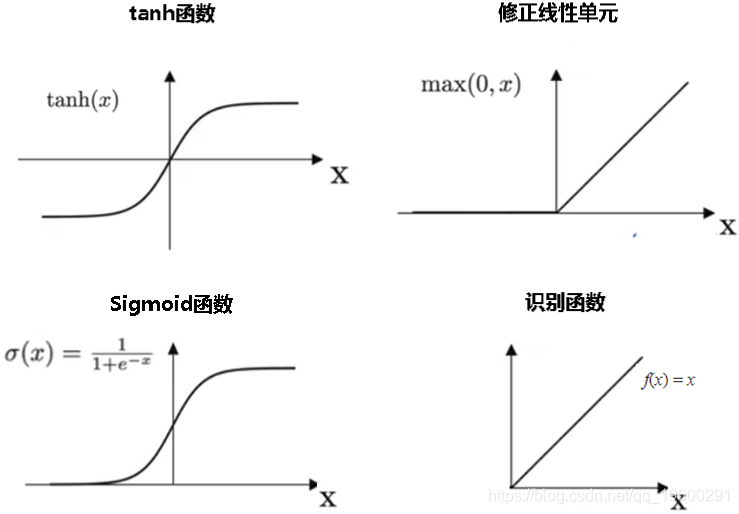
- 识别函数 通过激活函数 Identity,节点的输入等于输出。它完美拟合于潜在行为是线性(与线性回归相似)的任务。当存在非线性,单独使用该激活函数是不够的,但它依然可以在最终输出节点上作为激活函数用于回归任务。
- 在 二元阶梯函数(Binary Step Function)中,如果Y的值高于某个特定值(称为阈值),则输出为True(或已激活),如果小于阈值,则输出为false(或未激活)。这在分类器中非常有用。
- S形函数 称为S形函数。逻辑和双曲正切函数是常用的S型函数。有两种:
- Sigmoid函数 是一种逻辑函数,其中输出值为二进制或从0到1变化。
- tanh函数 是一种逻辑函数,其输出值在-1到1之间变化。也称为双曲正切函数或tanh。
- ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。它是最常用的激活函数。对于x的负值,它输出0。
在R中实现神经网络
创建训练数据集
我们创建数据集。在这里,您需要数据中的两种属性或列:特征和标签。在上面显示的表格中,您可以查看学生的专业知识,沟通技能得分和学生成绩。
因此,前两列(专业知识得分和沟通技能得分)是特征,第三列(学生成绩)是二进制标签。
#创建训练数据集
# 在这里,把多个列或特征组合成一组数据
test=data.frame(专业知识,沟通技能得分)让我们构建神经网络分类器模型。 首先,导入神经网络库,并通过传递标签和特征的参数集,数据集,隐藏层中神经元的数量以及误差计算来创建神经网络分类器模型。
# 拟合神经网络
nn(成绩~专业知识+沟通技能得分, hidden=3,act.fct = "logistic",
linear.output = FALSE)这里得到模型的因变量、自变量、损失函数、激活函数、权重、结果矩阵(包含达到的阈值,误差,AIC和BIC以及每次重复的权重的矩阵)等信息:
$model.list
$model.list$response
[1] "成绩"
$model.list$variables
[1] "专业知识" "沟通技能得分"
$err.fct
function (x, y)
{
1/2 * (y - x)^2
}
$act.fct
function (x)
{
1/(1 + exp(-x))
}
$net.result
$net.result[[1]]
[,1]
[1,] 0.980052980
[2,] 0.001292503
[3,] 0.032268860
[4,] 0.032437961
[5,] 0.963346989
[6,] 0.977629865
$weights
$weights[[1]]
$weights[[1]][[1]]
[,1] [,2] [,3]
[1,] 3.0583343 3.80801996 -0.9962571
[2,] 1.2436662 -0.05886708 1.7870905
[3,] -0.5240347 -0.03676600 1.8098647
$weights[[1]][[2]]
[,1]
[1,] 4.084756
[2,] -3.807969
[3,] -11.531322
[4,] 3.691784
$generalized.weights
$generalized.weights[[1]]
[,1] [,2]
[1,] 0.15159066 0.09467744
[2,] 0.01719274 0.04320642
[3,] 0.15657354 0.09778953
[4,] -0.46017408 0.34621212
[5,] 0.03868753 0.02416267
[6,] -0.54248384 0.37453006
$startweights
$startweights[[1]]
$startweights[[1]][[1]]
[,1] [,2] [,3]
[1,] 0.1013318 -1.11757311 -0.9962571
[2,] 0.8583704 -0.15529112 1.7870905
[3,] -0.8789741 0.05536849 1.8098647
$startweights[[1]][[2]]
[,1]
[1,] -0.1283200
[2,] -1.0932526
[3,] -1.0077311
[4,] -0.5212917
$result.matrix
[,1]
error 0.002168460
reached.threshold 0.007872764
steps 145.000000000
Intercept.to.1layhid1 3.058334288
专业知识.to.1layhid1 1.243666180
沟通技能得分.to.1layhid1 -0.524034687
Intercept.to.1layhid2 3.808019964
专业知识.to.1layhid2 -0.058867076
沟通技能得分.to.1layhid2 -0.036766001
Intercept.to.1layhid3 -0.996257068
专业知识.to.1layhid3 1.787090472
沟通技能得分.to.1layhid3 1.809864672
Intercept.to.成绩 4.084755522
1layhid1.to.成绩 -3.807969087
1layhid2.to.成绩 -11.531321534
1layhid3.to.成绩 3.691783805绘制神经网络
让我们绘制您的神经网络模型。
# 绘图神经网络
plot(nn)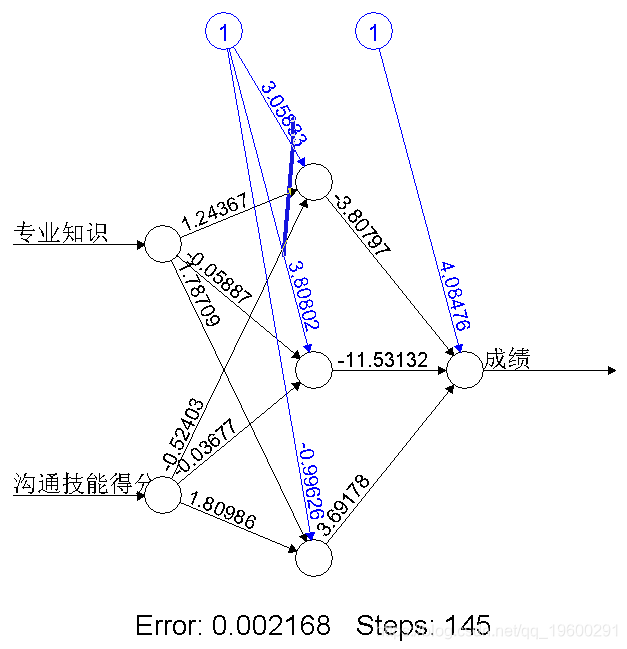
创建测试数据集
创建测试数据集:专业知识得分和沟通技能得分
# 创建测试集
test=data.frame(专业知识,沟通技能得分)预测测试集的结果
使用计算函数预测测试数据的概率得分。
## 使用神经网络进行预测
Pred$result0.9928202080
0.3335543925
0.9775153014现在,将概率转换为二进制类。
# 将概率转换为设置阈值0.5的二进制类别
pred <- ifelse(prob>0.5, 1, 0)pred神经网络更灵活,可以用于回归和分类问题。神经网络非常适合具有大量输入(例如图像)的非线性数据集,可以使用任意数量的输入和层,可以并行执行工作。
1
0
1预测结果为1,0和1。
利弊
还有更多可供选择的算法,例如SVM,决策树和回归算法,这些算法简单,快速,易于训练并提供更好的性能。神经网络更多的是黑盒子,需要更多的开发时间和更多的计算能力。与其他机器学习算法相比,神经网络需要更多的数据。NN仅可用于数字输入和非缺失值数据集。一位著名的神经网络研究人员说: “神经网络是解决任何问题的第二好的方法。最好的方法是真正理解问题。”
神经网络的用途
神经网络的特性提供了许多应用方面,例如:
- 模式识别: 神经网络非常适合模式识别问题,例如面部识别,物体检测,指纹识别等。
- 异常检测: 神经网络擅长异常检测,它们可以轻松检测出不适合常规模式的异常模式。
- 时间序列预测: 神经网络可用于预测时间序列问题,例如股票价格,天气预报。
- 自然语言处理: 神经网络在自然语言处理任务中提供了广泛的应用,例如文本分类,命名实体识别(NER),词性标记,语音识别和拼写检查。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
