您想构建一个没有太多训练数据的机器学习模型吗?
众所周知,机器学习需要大量数据,而收集和注释数据需要时间且成本高昂。
本文介绍了一些在没有太多数据或标记数据的情况下进行图像分类的方法。
我将介绍迁移学习、自监督学习的最重要方面。
利用未标记的数据
与标记数据相比,未标记的数据通常更容易访问。不利用这一点就是一种浪费!
自我监督学习
自监督学习解决了从未标记的数据中学习深度特征的问题。训练自监督模型后,特征提取器可以像在迁移学习中一样使用,因此您仍然需要一些带注释的数据来进行微调。
那么,如何从未标记的数据中训练深度特征提取器呢?总而言之,您需要一个足够困难的代理任务(Pretext Task),使您能够学习分类任务的有趣特征。

如果你想在不玩实际比赛的情况下赢得足球比赛,例如,你可以尽可能多地训练杂技球。杂技球将提高您的控球技术,这在玩游戏时会派上用场。
代理任务的一个例子是预测图像的旋转角度。基本上,对于每个图像,您应用旋转 z 来获取旋转的图像 x。然后,你训练一个神经网络来预测 x 中的 z 。 此转换预测任务会强制您的网络深入了解您的数据。事实上,要预测狗图像的旋转,您的网络首先需要了解图像中有一只狗,并且狗应该以特定的方式定向。
根据特定目标,代理任务可能会有很大差异。常用的代理任务包括:
转换预测:数据集中的样本由转换修改,您的网络将学习预测转换。
屏蔽预测:输入图像的随机方块被屏蔽,网络必须预测图像的屏蔽部分。
实例区分:了解区分所有数据样本的表示形式。例如,每个数据点都可以被视为一个类,并且可以在此任务上训练分类器。
随时关注您喜欢的主题
迁移学习
当您从头开始训练深度神经网络时,您通常会随机初始化权重。这是初始化神经网络的最佳方法吗?
答案通常是否定的。
首先,深度学习是关于表征的。在经典机器学习中,特征需要手工制作。深度学习背后的想法是,你让你的神经网络在训练时自己学习特征表示。
在神经网络的每一层之间,您有一个输入数据的表示形式。
你越深入你的神经网络,你的表示应该越全局化。通常,已知分类器神经网络的第一层能够检测颜色和形状。中间层将第一层表示作为输入,以计算比第一层更复杂的概念。例如,他们可能会检测到苹果叶或枝干的存在。最后一层给出了图像来自每个类的概率。
迁移学习背后的想法是,从另一个分类任务中学习的一些表示可能对您的任务有用。迁移学习是关于在另一项任务上获取预训练网络的第一层,在其上添加新层,并在感兴趣的数据集上微调整个网络。
作为比较,如果你的目标是学习赢得足球比赛,那么迁移学习将包括先学习打篮球,习惯移动你的身体,锻炼你的耐力等,然后再开始玩足球比赛。
它将如何影响最终网络的性能?您应该在哪里切断预先训练的网络?这些问题在中得到了广泛的解决。
总结最重要的想法:
- 神经网络的第一层是非常通用的,而最深的层是预训练任务中最专业的。因此,您可以预期,如果您的预训练任务接近目标任务,那么保留更多层将更有益。
- 在中间层切割通常会导致性能不佳。这是由于通过微调在中间层中达到的脆弱平衡。
- 使用预先训练的权重总是比使用随机初始化的权重更好。这是因为通过先训练另一个任务,你的模型学会了它本来不会学到的特征。
- 当重新训练这些预先训练的权重时,可以获得更好的表现——最终对它们使用较低的学习率。
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
本文演示了训练一个简单的卷积神经网络 (CNN) 来对 CIFAR 图像进行分类。由于本教程使用 Keras Sequential API,因此创建和训练我们的模型只需几行代码。
设置
library(keras)
下载并准备 CIFAR10 数据集
CIFAR10 数据集包含 10 个类别的 60,000 张彩色图像,每个类别有 6,000 张图像。数据集分为 50,000 张训练图像和 10,000 张测试图像。这些类是互斥的,它们之间没有重叠。
验证数据
为了验证数据集看起来是否正确,让我们绘制训练集中的前 25 张图像并在每张图像下方显示类别名称。
train %>%
map(as.rater, max = 255) %>%
创建卷积基
下面的6行代码使用一种常见的模式定义了卷积基础:Conv2D和MaxPooling2D层的堆叠。
作为输入,CNN接受形状的张量(image_height, image_width, color_channels),忽略了批次大小。如果你是第一次接触这些维度,color_channels指的是(R,G,B)。在这个例子中,你将配置我们的CNN来处理形状为(32,32,3)的输入,这是CIFAR图像的格式。你可以通过将参数input_shape传递给我们的第一层来做到这一点。
kers_moe_etl %>%
laer_c_2d(fles = 32, ene_sz = c(3,3), acan = "relu",
lye_apoi_2d(posize = c(2,2)) %>%
lae_cv_2d(filrs = 64, relze = c(3,3), ctitio = "reu")
到目前为止,让我们展示一下我们模型的架构。
summary(model)

在上面,你可以看到每个Conv2D和MaxPooling2D层的输出是一个三维形状的张量(高度、宽度、通道)。当你深入到网络中时,宽度和高度维度往往会缩小。每个Conv2D层的输出通道的数量由第一个参数控制(例如32或64)。通常情况下,随着宽度和高度的缩小,你可以承受(计算上)在每个Conv2D层中增加更多的输出通道。
在顶部添加密集层
为了完成我们的模型,您需要将卷积基(形状为 (3, 3, 64))的最后一个输出张量输入一个或多个 Dense 层以执行分类。密集层将向量作为输入(1D),而当前输出是 3D 张量。首先,您将 3D 输出展平(或展开)为 1D,然后在顶部添加一个或多个 Dense 层。CIFAR 有 10 个输出类,因此您使用具有 10 个输出和 softmax 激活的最终 Dense 层。
model %>%
leree(unis = 64, aciaion = "relu") %>%
ayedese(unis = 10, acivin = "sftax")
这是我们模型的完整架构。
注意 Keras 模型是可变对象,您不需要在上面的 chubnk 中重新分配模型。
summary(modl)

如您所见,我们的 (3, 3, 64) 输出在经过两个 Dense 层之前被展平为形状为 (576) 的向量。
编译和训练模型
moel %>% comle(
optier = "adam",
lss = "specatialosnopy",
mecs = "accray"
)
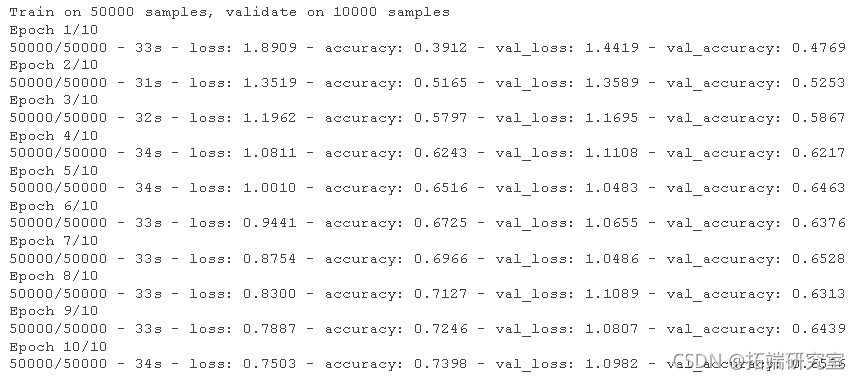
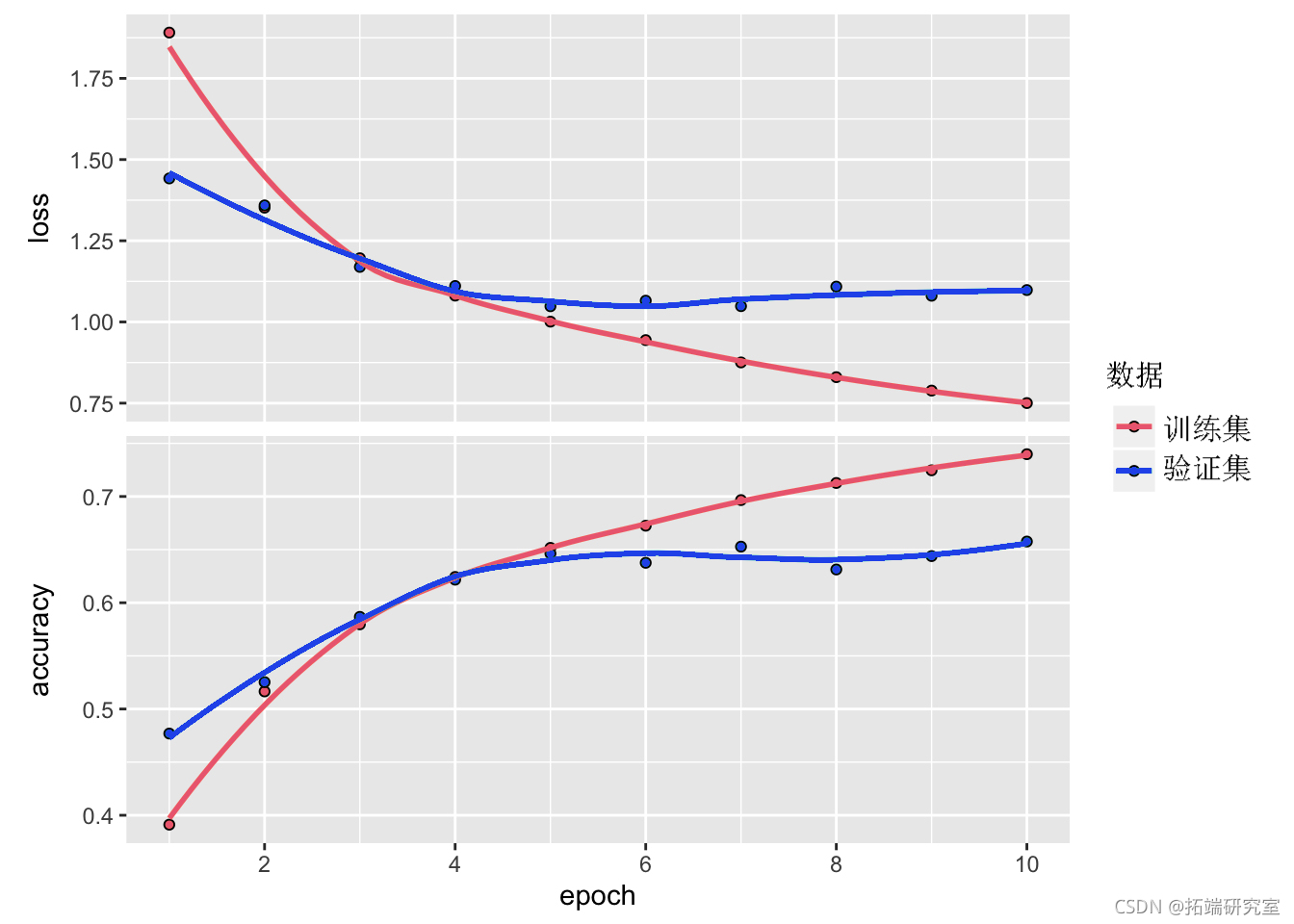
评估模型
plot(hsy)
ealte(oel, x,y, erbe = 0)
我们简单的 CNN 已经实现了超过 70% 的测试准确率。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据
Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据



