纪录片能够真实、详尽地反映一个地区的风貌,展示经济发展和社会进步。
2018年,纪录片发展迅猛,出现了几部大热作品,加之BBC纪录片造假的舆论导向,让人们对纪录片更加关注。
本文所用的纪录片数据来自哔哩哔哩网站,是目前主流视频网站上最丰富、最接近的数据来源。
可下载资源
数字特征和文本特征相结合,分析影响播放量的因素。采用回归树模型分析自变量对播放量的影响。
在纪录片发展的黄金期,纪录片制作方应该借助新媒体平台的优势以及技术优势,参考受众的需求喜好,创作出更好的纪录片。在网络视频平台上对纪录片进行研究,可以为纪录片的创作和宣传等提供实时性、有价值的建议,也为视频平台上的纪录片制作者提高视频播放量提供调整方案。
在实践价值上,本文旨在以哔哩哔哩弹幕网为例建模分析,以求能够得到纪录片题材选取的数据支撑,为当下纪录片选材提供切入点;通过播放量的影响因素分析,为视频发布者提供调整方案来提高自己的视频播放量,在见仁见智的评判上加入科学量化的判断。
目前针对纪录片选材研究比较匮乏,更多的研究集中在纪录片模式上的探索创新、新媒体传播途径等方面。随着微纪录片和vlog的出现,纪录片制作成本和门槛都大大下降,了解目前主流的纪录片题材有助于新手更好地创作,制作周期短、成本较低的微纪录片利用及时的热点有很可能吸引到广泛的受众。
纪录片播放量分布
视频播放量是检验视频质量和视频热度的一个直观媒介。
内容质量高、话题性强的视频自然会引起广泛关注。对于没有与平台签约的UP主来说,通过视频创作激励计划和奖励机制(充值计划),播放量与他们的收入直接挂钩。探讨影响纪录片播放量的因素,有助于更好地理解如何提高纪录片视频的关注度,以及如何更好地创作出令人愉悦的自制微纪录片。
纪录片的播放量与它的内容主题有关,有些主题很受欢迎,有些则很小众。不同的人有不同的兴趣点,会体现在弹幕、金币、分享等指标上,所以不同类别下的纪录片分布也会有所不同。
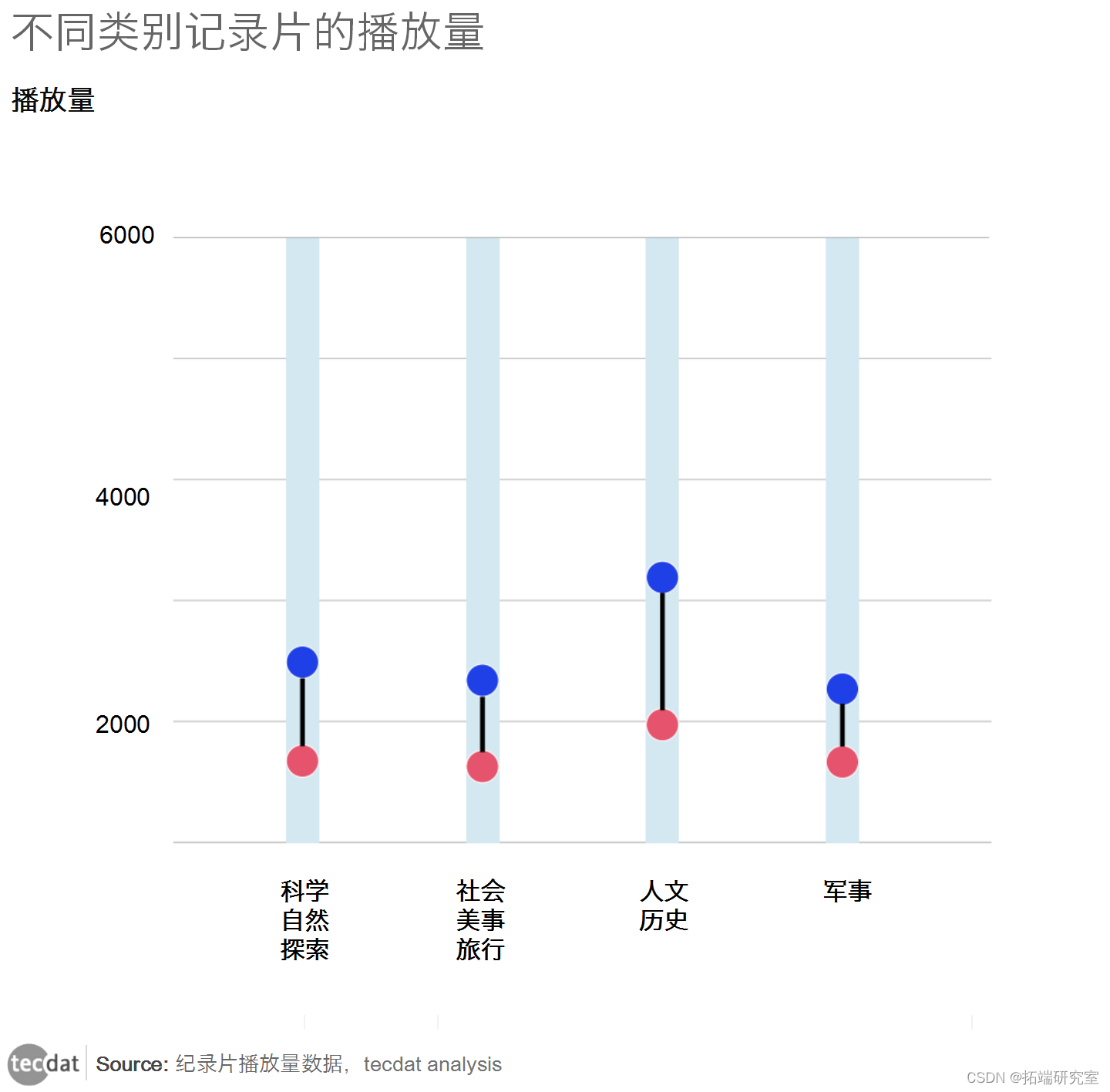
为了便于观察,图中只显示了播放量低于7000的纪录片。从图中可以看出,四类纪录片的播放量分布存在明显差异,人文●历史类纪录片的播放量总体上高于其余三类,且呈右偏态(数据集中的所有定量变量都是右偏态的)。军事类和社会食品类纪录片的分布则比较接近。旅游类纪录片的分布比较接近,总的来说,四类纪录片的播放量差异很大,因此不能用同一个模型进行分析。有必要对参数进行区分,并对每个类别下的纪录片进行不同的分析。
纪录片高频词特点
以下是对各个纪实分类下的文本的词频特征的分析。哔哩哔哩网站上最相关的纪录片细分类别是社会和旅游类,该类别的纪录片文本的高频词比较生活化。下图是对该细分领域的纪录片视频文本进行细分过滤后得到的高频词的词频图。
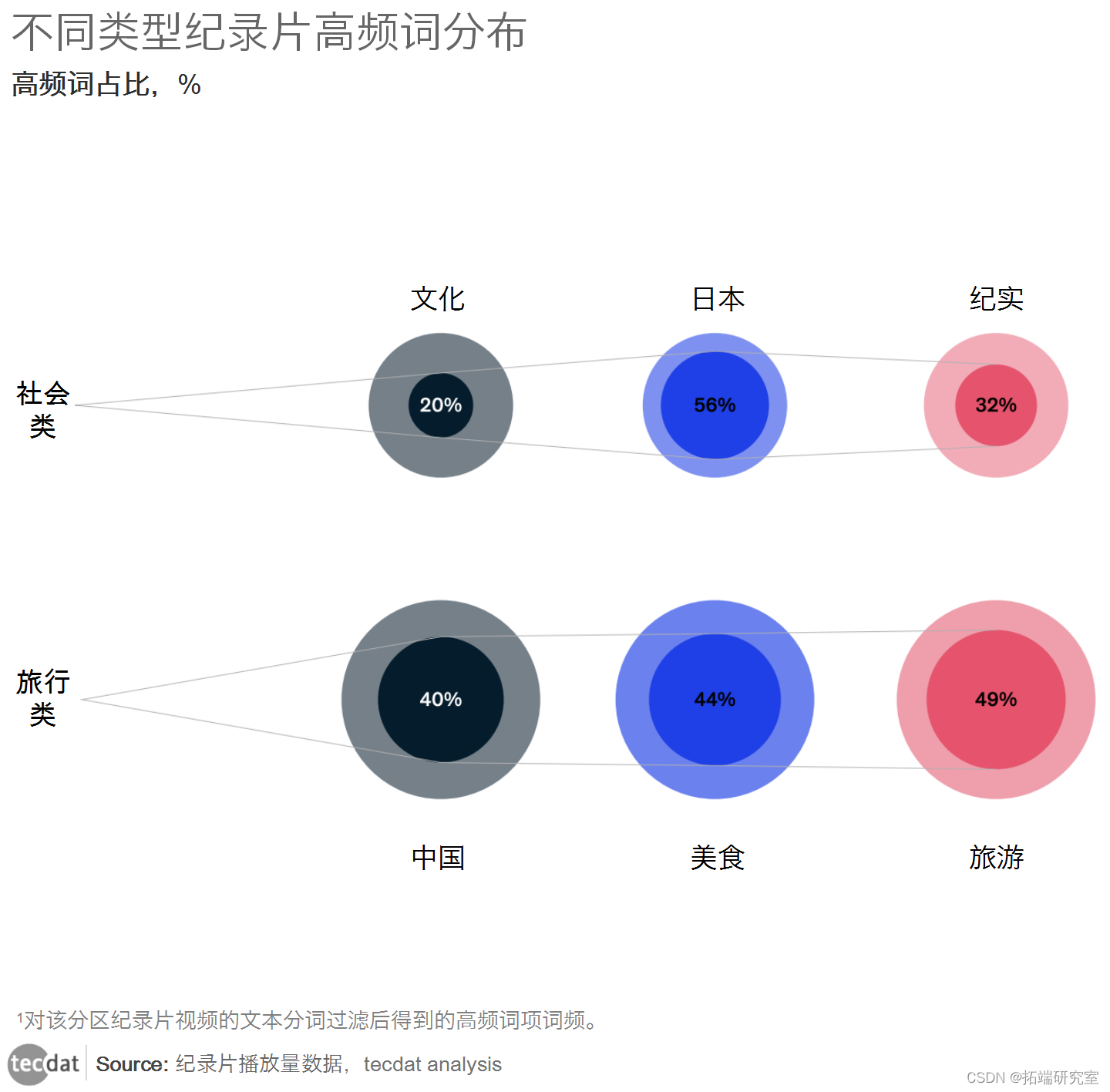
图中显示了社会和旅游纪录片文本中的12个高频词。其中,”旅游 “以11次排名第一,与 “旅游 “相关的 “旅游 “和 “旅游摄影 “分别排名第4和第6位。”食品 “以1111次排名第二,与 “食品 “相关的 “食品 “排名第11。”人文 “以607次排名第五,而与之相关的 “纪录片 “则排名第八。

此外,”中国”、”日本 “和 “世界 “的出现频率也很高。文字是由UP主编辑的,目的是让用户更好地理解视频内容,国家类高频词的出现表明,纪录片内容发生的国家是观众决定是否观看视频的重要决定。
随时关注您喜欢的主题
词频分析显示了高频词在纪录片中的分布情况,但不能仅根据词频给出纪录片的选择建议。
播放量的影响因素分析
接下来,我们研究变量对播放量的影响。回归树模型被用来确定自变量对播放量的影响程度。
对回归树进行模拟,在RMSE折线图的拐点处确定最优的树深为7,叶子节点的最小样本数设为25,分支节点的最小数量设为50。
进行十折交叉验证,建立回归树,下图为回归树的模型结构。
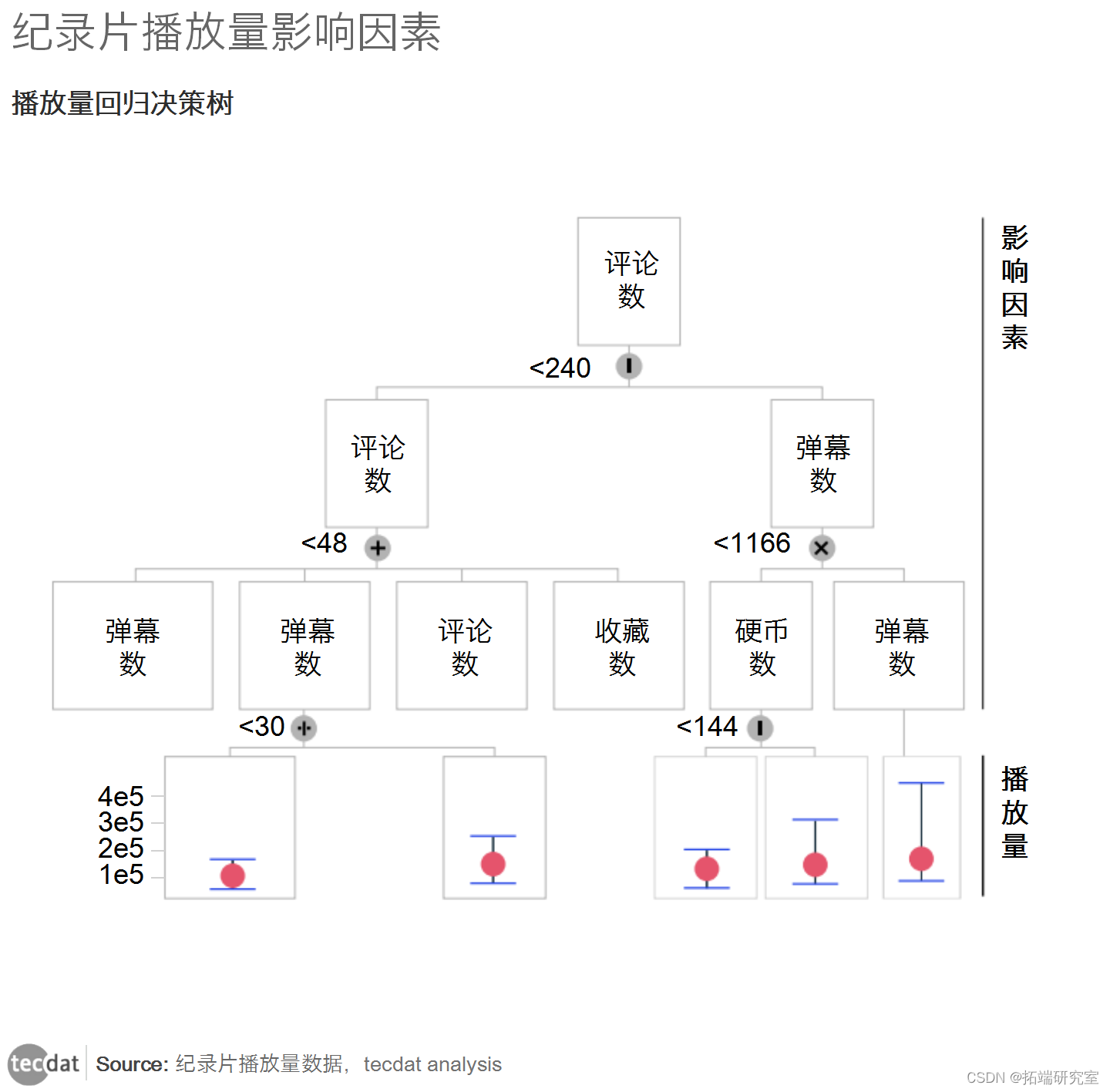
因此,与播放次数密切相关的变量是弹幕数、评论数和金币数,它们对高播放次数的影响更大。
在图中,观察叶子节点的框线图可以发现,大部分纪录片的播放量都很低,这些纪录片位于树状图的左侧,其判别变量是评论数和弹幕数。树状图的最右边的叶子节点划分了具有高播放量的纪录片,其判别变量是评论数和弹出窗口数,其次是相邻的左边叶子节点,其父节点有评论数、弹出窗口数和硬币数的分类变量。
从右侧的叶子节点可以看出,如果评论数、弹幕数和金币数越高,那么播放量也就越高。
在建立回归树模型时,自变量的重要性依次为:评论数(44)、弹幕数(18)、金币数(17)、分享数(8)、粉丝数(6)、收藏数(6)和提交数(1)。最重要的变量是观众与纪录片视频和UP主之间的互动程度,UP主在制作视频和选择能产生强烈互动的内容材料时,可以考虑到这一点。但是,这一点比较主观,没有量化的调整方案,也无法控制,无法确认所选的主题素材是否会带来高数量的评论和弹幕。
本文章中的所有信息(包括但不限于分析、预测、建议、数据、图表等内容)仅供参考,__拓端数据(__tecdat__)__不因文章的全部或部分内容产生的或因本文章而引致的任何损失承担任何责任。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载



