
时间序列预测,ARIMA等传统模型通常是一种流行的选择。
在时间序列分析领域,准确捕捉数据中的动态变化规律并进行有效的预测一直是研究的核心目标。时间序列数据广泛存在于经济、金融、气象、工程等众多领域,其往往受到多种复杂因素的影响,呈现出时变性、不确定性等特点。
传统的时间序列分析方法,如自回归积分滑动平均模型(ARIMA),虽然在一定程度上能够对平稳时间序列进行建模和预测,但对于具有复杂动态结构和噪声干扰的时间序列,其表现往往不尽如人意。
虽然这些模型可以证明具有高度的准确性,但它们有一个主要缺点 – 它们通常不会解释“冲击”或时间序列的突然变化。
让我们看看我们如何使用称为_卡尔曼滤波器_的模型来解决这个问题。

时间序列
我们以货币市场为例。货币对可能会有整体上升趋势,然后在抛售期间大幅下跌。传统的时间序列模型不一定能够立即解决这个问题,并且在考虑到趋势的突然变化之前可能需要几个时期。
1 时间序列
时间序列是指同一种现象在不同时间上的相继观察值排列而成的一组数字序列。统计学上,一个时间序列即是一个随机过程的实现。时间序列按其统计特性可以分为平稳时间序列和非平稳时间序列两类。在实际生活中遇到的序列,大多数是不平稳的。
说明:如果一个序列的平均值和方差始终为常数,则它是平稳的。在估计时间序列模型之前需把不平稳的时间序列转化为平稳序列。判断一个时间序列的平稳性可通过数据图和自相关函数图,如果数据图呈现线性或二次趋势形状,则该时间序列是不平稳的;如果自相关函数在前面少数几个值后下降趋向于0,则序列是平稳的。如果在前几个值后,自相关函数没有下降趋向于0,而是逐次减少,且值的大小超出固定的随机期间,则序列不平稳。
2 状态空间模型
如前所述,在现实生活中,数据的出现大多数是以非平稳形式,这涉及到动态数据所构成的时间序列的分解。分解时间序列的目的旨在估计和抽取确定性成分Tt(长期趋势),St(季节项),Ct(循环项),以使残量It(随机项)是一平稳过程。进而求得关于随机项的合适概率模型,分析它的性质,并连同Tt,St,Ct达到拟合和预报的目的。状态空间模型即可对时间序列进行分解,将Tt,St,Ct及It从时间序列中分离出来。
2.1 时间序列的状态空间描述
一般的,一个时间序列{yt}可以直接或经过函数变换后分解为如下的加法模型或乘法模型形式:
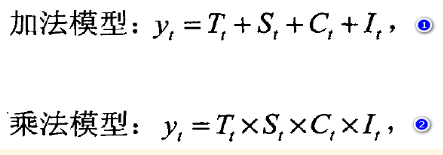
其中,(Tt)表长期趋势,( St)是季节项,(Ct)是循环项,(It)表不规则项,对于趋势明显为指数增长,且季节波动幅度也随时间增加的序列,一般采用乘法模型。
对于一般定常(非时变)的动态系统,假定其具有n维量测向量{yt}和m维状态向量{xt},量测向量是通过某些物理手段可以观测到的变量,而状态向量是用来描述系统动态特征的变量,一般是无法观测到的变量,只有状态向量和量测向量结合起来,才能对系统的动态特征做完整而充分的描述。状态空间模型即可实现这种动态描述。
2.2 状态空间模型
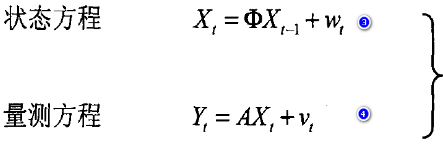
状态方程描述动态系统的状态从前一时刻到当前时刻的变化规律,而量测方程描述观测值和系统的状态之间的变化关系.Φ称为状态转移矩阵,A为量测矩阵,wt是状态噪声,vt是量测噪声(一般可设为正态白噪声)。
假定A和Φ中都是不随时间改变的常系数矩阵,状态空间有以下特点:
-
状态空间模型不仅能反映系统内部状态,而且能揭示系统内部状态与外部的输入和输出变量的联系;
-
状态空间模型将多个变量时间序列处理为向量时间序列,这种从变量到向量的转变更适合解决多输入输出变量情况下的建模问题。
-
状态空间模型能够用现在和过去的最小信息形式描述系统的状态,因此,它不需要大量的历史数据资料,既省时又省力。
(3)和(4)式中的有关量可以分解为组合形式:

下标j=1,2,3分别对应于趋势项、循环项、季节项。即:
-
Φ1,A1,X1t,w1t均对应于趋势项;
-
Φ2,A2,X2t,w2t均对应于循环项;
-
Φ3,A3,X3t,w3t均对应于季节项。
-
Φj,Aj,Xjt,wjt均可由对应项的相应模型求出,且都为矩阵形式。
只要确定出趋势项(趋势差分数k)、循环项(循环项AR模型的阶数p)、季节项(季节阶数L,d),就可以方便的写出相应的状态空间模型。k=2,p=2,d=1时,例子如下:
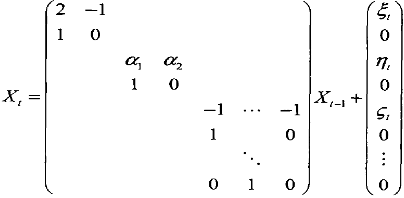
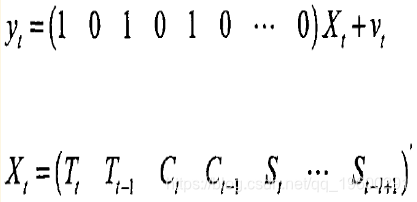
若采用月度数据(L=12),上式中状态向量Xr的维数m=15;若采用季度数据(L=4) 则Xt是m=7维向量。相应的噪声方差矩阵如下: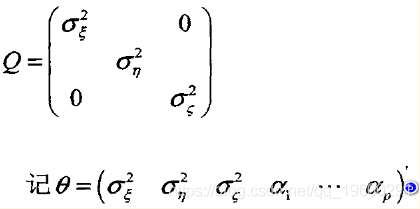
(5)式是状态空间模型的待估参数,一般称为超参数。α2ϵ,α2η,α2ζ分别是趋势、循环、季节各部分的状态噪声方差,α1,…,αp是拟合循环项的自回归模型参数。
这些超参数需要使用极大似然估计或EM算法等方法得到。
剩下的工作是要得到状态向量序列{Xt}。如果估计出{Xt},则时间序列{yt}的分解就完成了。这可以通过Kalman滤波等方法对非平稳时间序列进行外推、内插及平滑,计算出每个时刻的状态向量。
因此,我们希望使用一个确实能够解释这种冲击的时间序列模型。让我们来看一个称为_卡尔曼滤波器_的模型。
卡尔曼滤波器是一种状态空间模型,可以更快地调整冲击到时间序列。让我们看一下例子。
2015年1月,当瑞士国家银行决定取消瑞士法郎时,货币市场遭受了历史上最大的冲击之一。结果,瑞士法郎飙升,而其他主要货币则暴跌。
让我们看看卡尔曼滤波器如何调整这种冲击。
卡尔曼滤波器:USD / CHF
首先,让我们下载2015年1月的USD / CHF数据。
> currency = Quandl("FRED/DEXSZUS", start_date="2010-01-01",end_date="2018-09-29",type="xts")
> currency=data.frame(currency)
> currency=(log(currency$currency))现在,我们将尝试使用KFAS库使用卡尔曼滤波器对此时间序列进行建模。

绘制时间序列:
> ts.plot(ts(exp(currency[1232:1274]), exp(out$a[1232:1274]), exp(out$att[1232:1274]), exp(out$alpha[1232:1274])
为了进行比较,我们还将计算10天移动平均值,以比较平滑性能与卡尔曼滤波器的平滑性能。
data.frame(SMA(exp(currency),n=10)) 现在让我们将上面的内容与我们的原始序列结合起来,看看我们得到了什么:
这是生成的数据框:
在某些情况下,高频数据 – 或过滤从噪声信号中提取信息并预测未来状态,是卡尔曼滤波器最合适的用途。另一方面,平滑更依赖于过去的数据,因为在某些情况下,平均最近的预测可能比使用最近的预测更准确。
这在直觉上是有道理的,因为货币在一个月之前的交易价格为0.9658。在这方面,平滑估计器允许比使用滤波估计更好地预测信号,滤波估计a直到时间段33才调整冲击。
例子:英镑/美元
因此,我们已经看到卡尔曼滤波器如何拟合美元/瑞士法郎的突然变动。我们再举一个货币冲击的例子。当英国在2016年6月投票支持“英国退欧”时,我们看到英镑/美元随后暴跌。
如在USD / CHF的例子中,我们从Quandl下载我们的GBP / USD数据并运行卡尔曼滤波器:
这是我们的数据图。同样,我们看到alpha在t = 22时的震荡前一天向下调整到1.438的水平:
以下是a,att和alpha统计信息:
同样,我们看到10天SMA需要将近10天才能完全调整震荡,再次表明平滑参数α在调整货币水平的巨大变化时是不错的。
随时关注您喜欢的主题
结论
- 调整时间序列冲击的重要性
- 如何在R中使用KFAS实现卡尔曼滤波器
- 如何解释卡尔曼滤波器的输出
- 为什么卡尔曼滤波器是用于建模时间序列冲击的合适模型
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
