本文旨在探讨时间卷积网络(Temporal Convolutional Network, TCN)与CNN、RNN在预测任务中的应用。
通过引入TCN模型,我们尝试解决时间序列数据中的复杂依赖关系,以提高预测的准确性。
视频
Python、R时间卷积神经网络TCN与CNN、RNN预测时间序列实例
本文首先介绍了TCN的基本原理,随后详细描述了数据预处理、模型构建、训练及评估的整个过程。实验结果表明,TCN模型在处理时间序列数据时表现出色,为相关领域的研究提供了一种新的有效方法。
时间卷积网络(TCN)概述
时间卷积网络(TCN)是一种专为序列建模设计的卷积神经网络架构。
它通过引入因果卷积和膨胀卷积,实现了对序列数据的长期依赖关系的有效捕捉。因果卷积确保了模型输出的每个时间步仅依赖于过去的输入,而膨胀卷积则通过增加感受野的大小,使得模型能够捕捉到更远距离的信息。
数据预处理
在模型训练之前,对数据进行适当的预处理是至关重要的。本文采用以下步骤进行数据预处理:
- 数据加载:从指定路径加载时间序列数据。
- 归一化:使用MinMaxScaler对数据进行归一化处理,以消除不同量纲对模型训练的影响。
- 划分数据集:将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和测试。
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
下面的代码将帮助定义一些需要运行程序的变量。它还将创建用于测试和预测的训练样本、验证样本和附加样本。
df = pd.read_csv(f_path)
# 计算训练样本的大小,这里取数据总量的60%
training_sample_size = math.ceil(df.shape[0] * .6)
# 计算验证样本的大小,这里取数据总量的15%
validation_sample_size = math.ceil(df.shape[0] * .15)
# 设置采样方式为'sliding_window',即滑动窗口方式,也可以设置为'jump'(跳步方式)
在此,数据已经成型,可以输入到模型中,但我们需要先定义模型 要定义模型,我们应该知道内核的大小、TCN 需要多少个滤波器和多少个层

if len(channels) != num_layers:
print('You should not have more than {} residual layers or else model will be equivalent to RNN'.format(num_layers))
模型定义
在本文中,我们聚焦于构建并优化一个高效的时间卷积网络(Temporal Convolutional Network, TCN)模型,旨在解决时间序列预测中的复杂问题。TCN作为一种专为序列数据设计的深度学习架构,通过其独特的卷积结构和时间因果性,能够有效捕捉数据中的长期依赖关系,从而提高预测的准确性。
视频
CNN(卷积神经网络)模型以及R语言实现
视频
卷积神经网络CNN肿瘤图像识别
视频
LSTM神经网络架构和原理及其在Python中的预测应用
视频
LSTM模型原理及其进行股票收盘价的时间序列预测讲解
模型架构设计
模型的定义是预测任务中的关键环节。在本研究中,我们采用了TemporalConvolutionalNet类来实例化TCN模型。该类通过接收一系列参数来定义模型的具体结构,包括输入通道数(in_channels)、输出通道数(channels)、卷积核大小(kernel_size)、dropout比率以及是否应用权重归一化等。
具体地,模型定义如下:
y_pred = model(X_train) # 让模型对训练集X_train进行预测
loss_value = loss(y_pred, y_train) # 计算预测值与真实值之间的损失
#print(y_pred) # 注释掉的代码,原本可能用于打印预测值
在这里,我们测试了训练数据,看看平均验证损失是否足够低。之所以要看平均值,是因为数据的性质决定了它的波动性。一个好的模型应该能够应对这种波动性。# 验证模型 validation_loss = [] with torch.no_grad(): # 禁用梯度计算,以节省内存和加速计算 model.eval() # 将模型设置为评估模式,停止dropout等操作
给定一组新数据,我们将其输入模型,以确定其预测结果
多元TCN
接下来旨在介绍基于时间卷积网络(Temporal Convolutional Network, TCN)的多元时间序列预测模型的构建过程,并详细阐述数据预处理及特征工程的实施步骤。通过整合多变量预处理技术、特征提取方法和模型构建策略,本文提出了一种有效的预测框架,旨在提高时间序列数据预测的准确性。
= 14 # ticer_options = ['APPLE', 'TESLA', 'AT&T', 'S&P500'] ticker = 'APPLE' cur_dir = Path(os.getcwd()) parent_path = cur_dir.parent f_path = parent_path / 'data/{}.csv'.format(ticker) df=pd.read_csv(f_path)
在这里,数据已经成型,可以输入到模型中,但我们需要先定义模型。要定义模型,我们应该知道内核的大小、TCN 需要多少个过滤器和层

想了解更多关于模型定制、咨询辅导的信息?
模型定义
时间卷积网络(TCN)是一种专为序列建模设计的深度学习架构,它通过引入因果卷积和膨胀卷积来捕获序列中的长期依赖关系。在本研究中,我们使用TemporalConvolutionalNet类来定义TCN模型,具体参数包括输入通道数(in_channels)、输出通道数(channels)、卷积核大小(kernel_size)、丢弃率(dropout)以及权重归一化选项(weight_normal)。
下面的代码将帮助定义一些需要运行程序的变量。它还将创建用于测试和预测的训练样本、验证样本和附加样本 window_size
in_channels = num_features
out_channel = 1
filter_size = 3
模型定义与训练
模型定义
在本文中,我们采用了一个时间卷积网络(Temporal Convolutional Network, TCN)作为我们的主要模型架构,用于处理时间序列数据。
此模型配置旨在通过调整输入通道数、卷积核的通道数、卷积核大小以及引入适当的Dropout来优化模型的性能。
随时关注您喜欢的主题
训练模型
训练参数设置
为了训练该模型,我们设置了以下训练参数:
- 训练周期数 (
num_epoch): 500,即整个训练数据集将被遍历500次。 - 损失函数 (
loss): 采用均方误差损失(MSE Loss),适用于回归任务。 - 优化器 (
optimizer): 使用Adam优化器,其学习率设置为0.015,betas参数为(0.45, 0.35),以及权重衰减为0.4。这些参数经调优后旨在提高模型的收敛速度和泛化能力。此外,还提供了另一组备选超参数以供比较。
在这里,我们测试了训练数据,看看平均验证损失是否足够低。之所以要看平均值,是因为数据的性质决定了它的波动性。一个好的模型应该能够应对这种波动性。
准确预测未来趋势对于决策制定至关重要。本文探讨了一种利用滑动窗口法(Sliding Window Method)进行时间序列预测的方法,该方法通过动态调整输入数据的窗口大小,有效捕捉时间序列中的历史信息,并据此预测未来的数据点。
方法
1. 滑动窗口法概述
滑动窗口法是一种处理时间序列数据的常用技术,它通过设定一个固定大小的窗口在数据序列上滑动,每次滑动都选取窗口内的数据作为模型的输入。在本研究中,我们特别关注于输入和输出长度相等的配置,即窗口大小与预测目标序列的长度相匹配。
预测流程
给定一组新的时间序列数据,我们按照以下步骤进行预测:
- 步骤一:数据准备:首先,确定预测所需的窗口大小(即输入长度)和预测长度(
num_predictions)。例如,若num_predictions为2,则意味着我们希望模型能够基于当前及之前的数据点预测未来两个时间步的值。 - 步骤二:构建输入和目标序列:通过滑动窗口法构建输入和目标序列。具体而言,将目标序列相对于输入序列向后移动
num_predictions个时间步,以确保输入序列包含了用于预测未来num_predictions个时间步所需的所有历史信息。例如,对于输入序列t1,t2,t3,t4,t5,对应的目标序列将是t3,t4,t5,t6,t7,其中t6,t7即为预测目标。 - 步骤三:模型预测:将构建好的输入序列输入到已训练的时间序列预测模型中,模型将输出与输入序列长度相等的预测序列。由于模型已知输入序列中前
len(input)-num_predictions个时间步的真实值,它利用这些信息来预测接下来的num_predictions个时间步的值。 - 步骤四:验证与评估:为了验证模型的预测性能,我们将预测结果与真实值(即总数据集中位于输入序列之后的
num_predictions个时间步的值)进行比较。例如,如果总数据集为t1,t2,t3,t4,t5,t6,t7,则通过比较模型预测的t6,t7与实际的t6,t7来评估预测准确性。
【视频讲解】R语言实现CNN(卷积神经网络)模型进行回归数据分析
当我们将CNN(卷积神经网络)模型用于训练多维类型的数据(例如图像)时,它们非常有用。我们还可以实现CNN模型进行回归数据分析。我们之前使用Python进行CNN模型回归 ,在本文中,我们在R中实现相同的方法。
视频
CNN(卷积神经网络)模型以及R语言实现
我们使用一维卷积函数来应用CNN模型。我们需要Keras R接口才能在R中使用Keras神经网络API。如果开发环境中不可用,则需要先安装。本教程涵盖:
1.参数共享机制(parameters sharing)
因为,对于不同的区域,我们都共享同一个filter,因此就共享这同一组参数。这也是有道理的,通过前面的讲解我们知道,filter是用来检测特征的,那一个特征一般情况下很可能在不止一个地方出现,比如“竖直边界”,就可能在一幅图中多出出现,那么我们共享同一个filter不仅是合理的,而且是应该这么做的。
由此可见,参数共享机制,让我们的网络的参数数量大大地减少。这样,我们可以用较少的参数,训练出更加好的模型,典型的事半功倍,而且可以有效地 避免过拟合。同样,由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做 “平移不变性”。因此,模型就更加稳健了。
2.连接的稀疏性(sparsity of connections)
由卷积的操作可知,输出图像中的任何一个单元,只跟输入图像的一部分有关系。而传统神经网络中,由于都是全连接,所以输出的任何一个单元,都要受输入的所有的单元的影响。这样无形中会对图像的识别效果大打折扣。比较,每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。
- 准备数据
- 定义和拟合模型
- 预测和可视化结果
- 源代码
我们从加载本教程所需的库开始。
library(keras)
library(caret)
准备
数据在本教程中,我们将波士顿住房数据集用作目标回归数据。首先,我们将加载数据集并将其分为训练和测试集。
set.seed(123)
boston = MASS::Boston
indexes = createDataPartition(boston$medv, p = .85, list = F)
train = boston[indexes,]
test = boston[-indexes,]接下来,我们将训练数据和测试数据的x输入和y输出部分分开,并将它们转换为矩阵类型。
您可能知道,“ medv”是波士顿住房数据集中的y数据输出,它是其中的最后一列。其余列是x输入数据。
检查维度。
dim(xtrain)
[1] 432 13
dim(ytrain)
[1] 432 1接下来,我们将通过添加另一维度来重新定义x输入数据的形状。
dim(xtrain)
[1] 432 13 1
dim(xtest)
[1] 74 13 1
在这里,我们可以提取keras模型的输入维。
print(in_dim)
[1] 13 1定义和拟合模型
我们定义Keras模型,添加一维卷积层。输入形状变为上面定义的(13,1)。我们添加Flatten和Dense层,并使用“ Adam”优化器对其进行编译。

model %>% summary()
________________________________________________________________________
Layer (type) Output Shape Param #
========================================================================
conv1d_2 (Conv1D) (None, 12, 64) 192
________________________________________________________________________
flatten_2 (Flatten) (None, 768) 0
________________________________________________________________________
dense_3 (Dense) (None, 32) 24608
________________________________________________________________________
dense_4 (Dense) (None, 1) 33
========================================================================
Total params: 24,833
Trainable params: 24,833
Non-trainable params: 0
________________________________________________________________________
接下来,我们将使用训练数据对模型进行拟合。
print(scores)
loss
24.20518
预测和可视化结果
现在,我们可以使用训练的模型来预测测试数据。
随时关注您喜欢的主题
predict(xtest)
我们将通过RMSE指标检查预测的准确性。
cat("RMSE:", RMSE(ytest, ypred))
RMSE: 4.935908
最后,我们将在图表中可视化结果检查误差。
x_axes = seq(1:length(ypred))
lines(x_axes, ypred, col = "red", type = "l", lwd = 2)
legend("topl在本教程中,我们简要学习了如何使用R中的keras CNN模型拟合和预测回归数据。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
该数据根据世界各国提供的新病例数据。获取时间序列数据
df=pd.read_csv("C://global.csv")
探索数据
此表中的数据以累积的形式呈现,为了找出每天的新病例,我们需要减去这些值
可下载资源
GRU也是也可处理序列数据的一种模型,是循环神经网络的一种,同时呢它也是LSTM的一种变体,然后为什么要学习它,是因为我们了解了LSTM后发现他有很多可以精简改进的地方,例如说它复杂的模型结构,因此GRU就诞生了。相比较LSTM内部结构进行了简化,同时准确率也得到了提升。
为什么说GPU比LSTM更加的精简?
首先我们知道LSTM总共有三个门,遗忘门,输入门,输出门,而我们的GRU中呢使用的是两个门,重置门和更新门。
GRU和LSTM的区别:
LSTM有三个门,而GRU有两个门
去掉了细胞单元C
输出的时候取消了二阶的非线性函数
两个门的理解:
重置门:
作用对象是前边的隐藏状态
作用呢就是决定了有多少过去信息需要遗忘
更新门:(可以理解为LSTM中的遗忘门和输入门相结合)
作用对象是当前时刻和上一时刻的隐藏单元
作用就是上一时刻,以及当前时刻总共有多少有用的信息需要接着向下传递
df.head(10)
这些数据是根据国家和地区报告新病例的数据,但我们只想预测国家的新病例,因此我们使用 groupby 根据国家对它们进行分组
总结数据
执行 groupby 以根据一个国家的新病例来汇总数据,而不是根据地区
d1=df.groupby(\['Country/Region'\]).sum()

描述随机选择的国家的累计新病例增长
from numpy.random import seed plt.plot(F\[i\], label = RD\[i\]) plt.show()
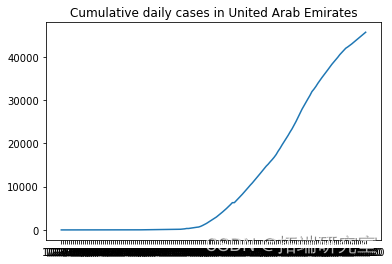
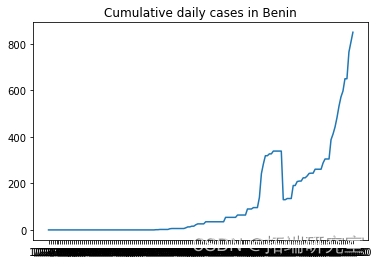
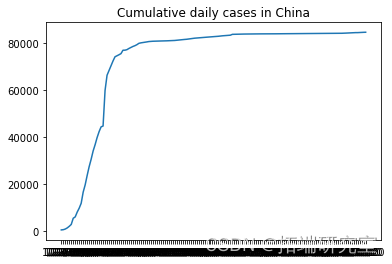
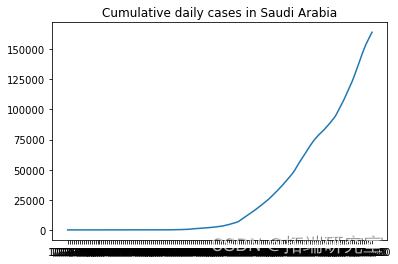
# 我们不需要前两列 d1=d1.iloc\[:,2:\]

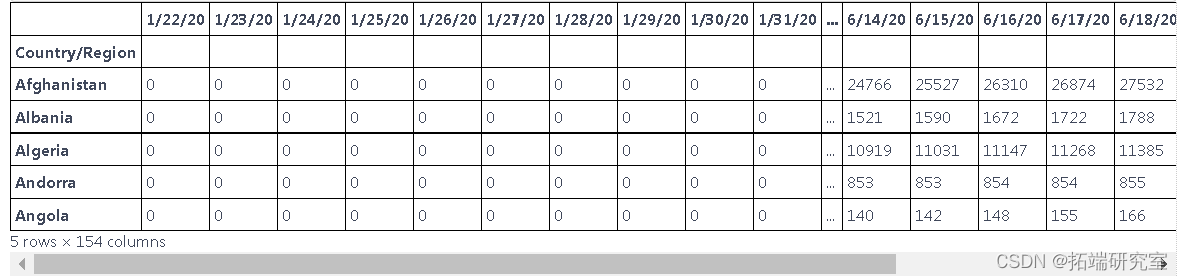
# # 检查是否有空值 d1.isnull().sum().any()
我们可以对每个国家进行预测,也可以对所有国家进行预测,这次我们对所有国家进行预测
随时关注您喜欢的主题
dlycnmdcas.head()

dalycnfreces.index
dal\_cnre\_ces.index = pd.to\_datetime(dailyonfrmd\_as.index)
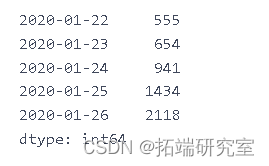
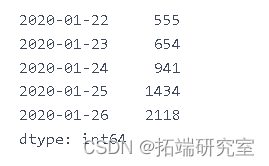
plt.plot(dalnimedases)
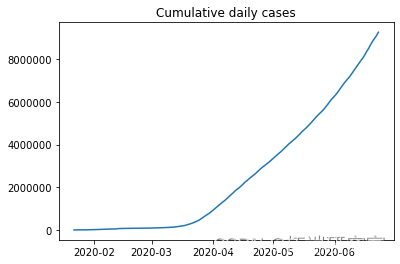
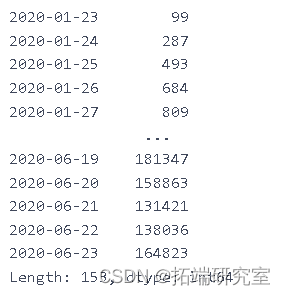
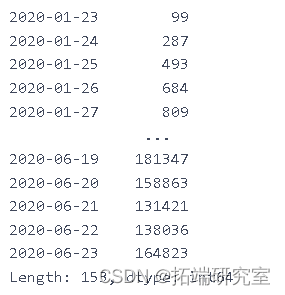
ne\_ces = daiy\_onme_as.diff().dropna().astype(np.int64) newcaes
plt.plot(ne_s\[1:\])
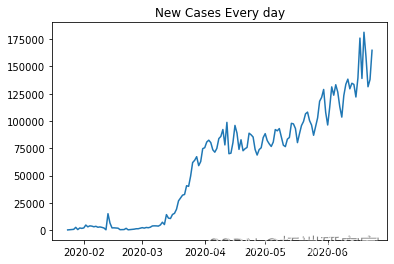
nw_s.shape
(153,)
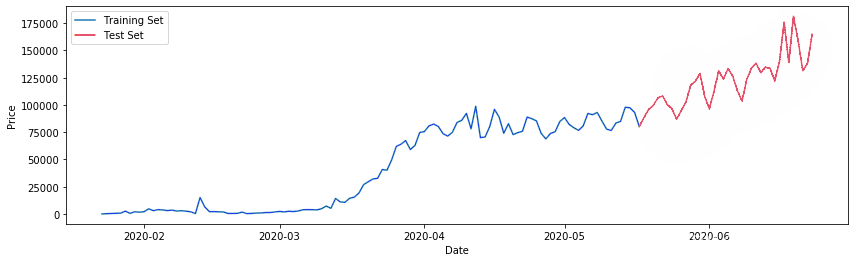
将数据拆分为训练和测试数据
ct=0.75 trin\_aa,tet\_aa = train\_test\_split(ne_ces, pct)
(116,) `````` plt.plot(tainta) plt.plot(tesata)
数据标准化
scaler = MinMaxScaler()
testa.shape
(38, 1)
创建序列
lentTe = len(ts_data) for i in range(timmp, lenhTe): X\_st.append(tst\_aa\[i-tmStap:i\]) y_tt.append(tesata\[i\]) X\_tet=np.array(X\_ts) ytes=np.array(y_tt)
X_st.shape



Xtrn.shape

# 序列的样本 X_trn\[0\], yran\[0\]

为股票价格预测设计 RNN 模型
模型:
- LSTM
- GRU
model.summary()

model.fit(X\_trn y\_rin, epochs=50, batch_size=200)


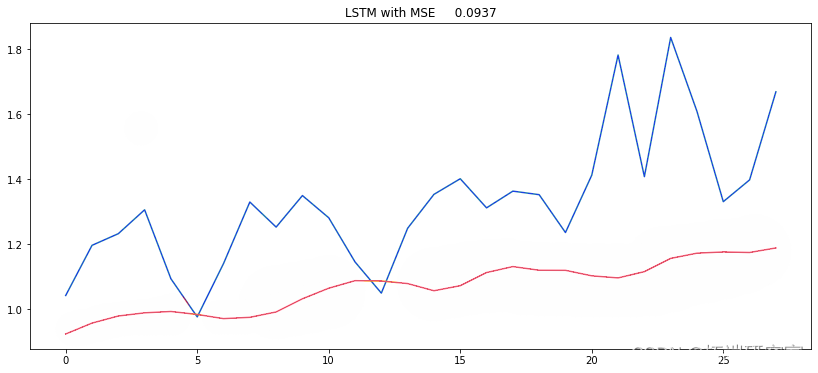
yprd = (mod.predict(X_test)) MSE = mean\_squared\_error(ytue, y_rd) plt.figure(figsize=(14,6))
meRU= Sqtal(\[ keras.layers.GRU( model\_GRU.fit(Xtrn, ytin,epochs=50,batch\_size=150)

pe_rut = {}
y\_ue = (y\_et.reshape(-1,1))
y\_prd = (modlGU.predict(X\_test))
MSE = mean\_squared\_error(y_ue, ed)
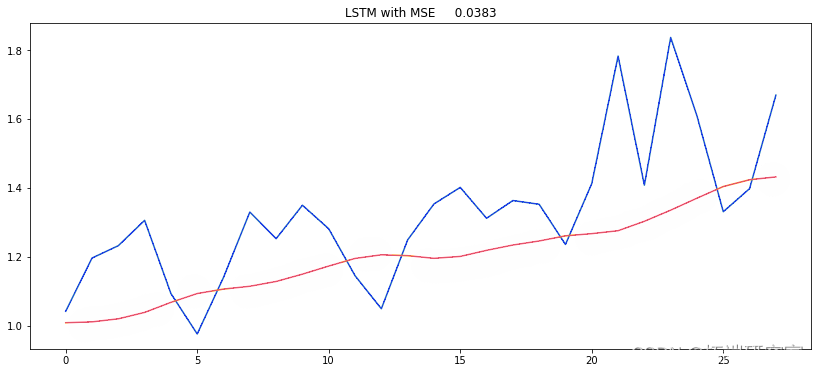
用于预测新病例的机器学习算法
准备数据
d__in.shape

moel=LinearRegression(nos=-2)
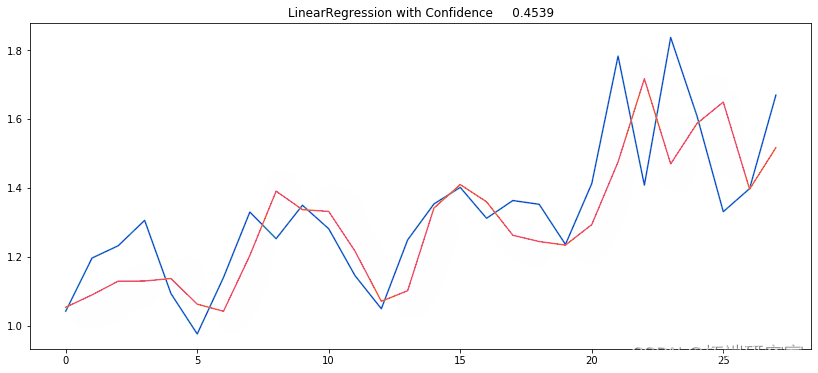
ARIMA
COVID-19 新病例预测的自回归综合移动平均线
#我们不需要前两列 df1.head() daly\_nfrd\_cses = df1.sum(axis=0) day\_cnir\_ase.index = pd.to\_datetime(da\_onieses.index)
new_cs = dacofmecss.diff().dropna().astype(np.int64) tri\_ta,tet\_ata = trintt\_it(nw\_es, pct)
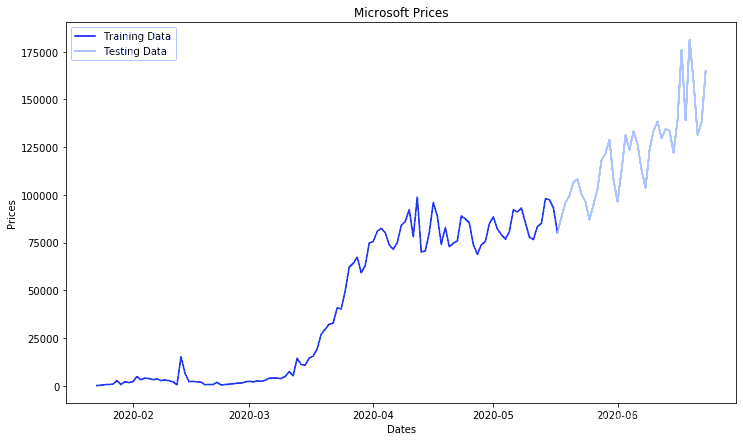
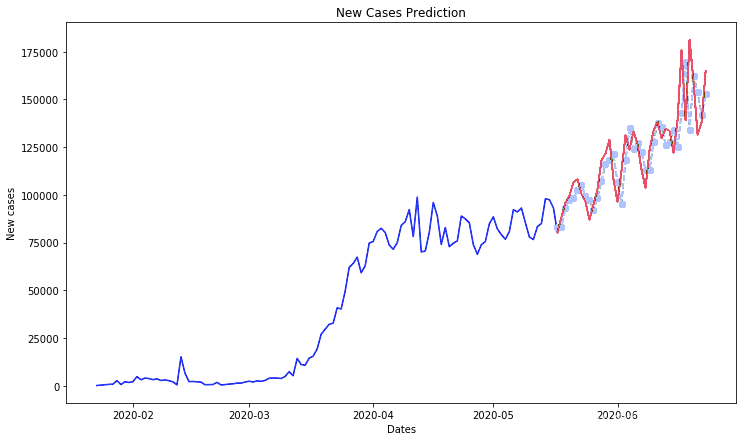
ero = men\_squred\_eror(ts_ar, pricos)



plt.figure(figsize=(12,7)) plt.plot(tanat)
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python主题建模、情感分析酒店评论、工商银行手机APP用户评论:MLP、LSTM、CNN、LDA、SVM、随机森林、朴素贝叶斯
Python主题建模、情感分析酒店评论、工商银行手机APP用户评论:MLP、LSTM、CNN、LDA、SVM、随机森林、朴素贝叶斯



