
prophet与基本线性模型(lm),广义加性模型(gam)和随机森林(randomForest)进行了比较。
本文 将针对R进行的几次建模练习的结果,以魁北克数据为依据,分为13年的训练和1年的测试。首先,设置一些选项,加载一些库,并更改工作目录。
可下载资源
首先,设置一些选项,加载一些库,并更改工作目录。
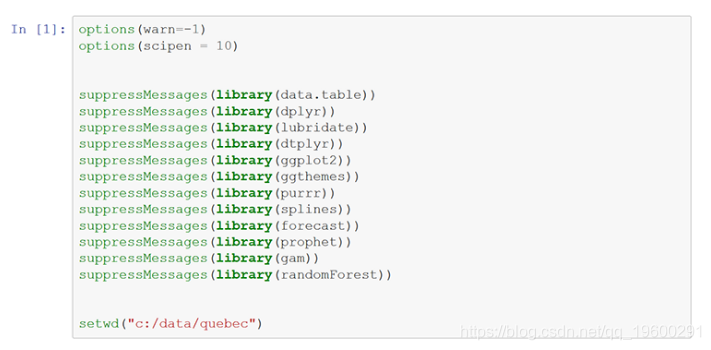

读取魁北克的出生文件,建立一个data.table 。创建培训和测试data.tables-使用前13年的每日数据进行培训,并使用第14年进行测试。
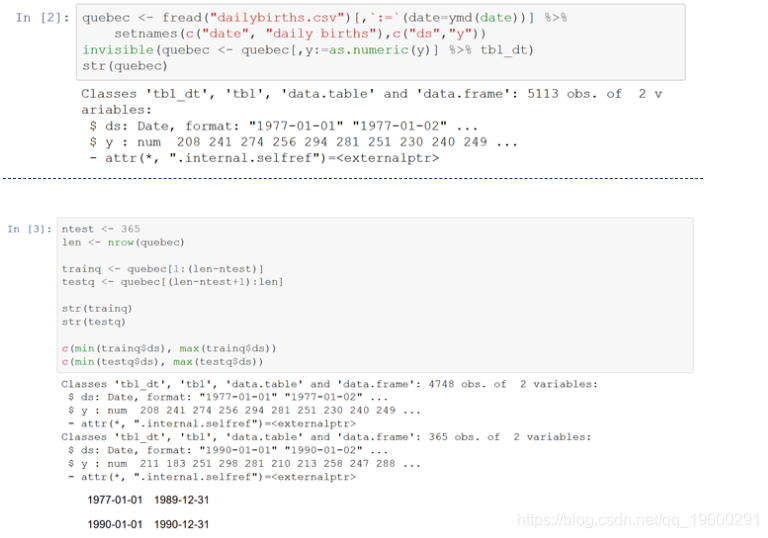

定义两个小函数来计算 均方根误差(rmse)和平均绝对百分比误差(mape),以评估预测模型的性能。越低越好。


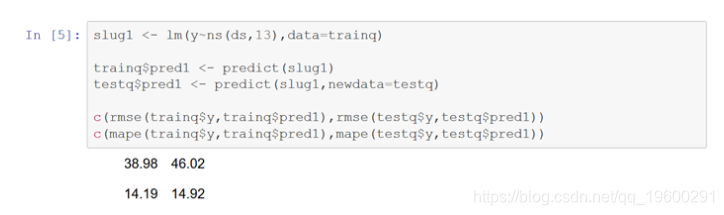
现在开始拟合基本的lm线性模型。第一个回归整数日期(ds)的三次样条上的日出生(y)以捕获趋势。根据训练和测试数据计算rmse和mape。

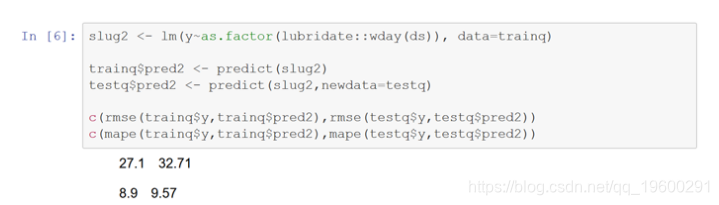
接下来运行一个星期几的每日出生率模型,以捕获一周内的季节性。在性能指标上,该模型似乎比第一个模型好,这表明一周中每天都有重要的季节性。

第三个模型基于月创建一个因子来处理每月的季节。这种季节性似乎不像一周中的一天那么强烈。
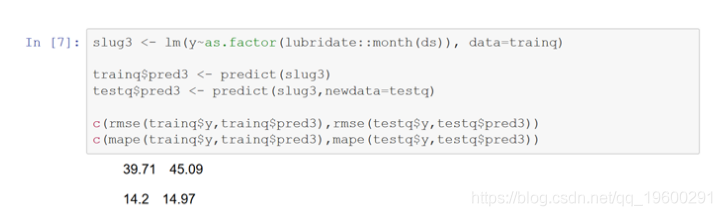

最后,运行一个包含上述所有三个变量的lm模型。请注意,预测的均方根较低的rmse和mape。
现在,使用gam程序包运行类似的3变量通用加性模型。毫不奇怪,训练和测试的均方根值和mape与最终的lm模型相当。
使用相似的趋势和季节性属性拟合randomForest ML模型。请注意,火车和测试性能之间的差异较大,表明火车数据过拟合。
最后将数据划分为训练并进行测试以适合先知并拟合其模型
在这一点上,让我们看一下上面安装的各种lm模型的预测-第一个趋势,然后是星期几,最后是一个月。
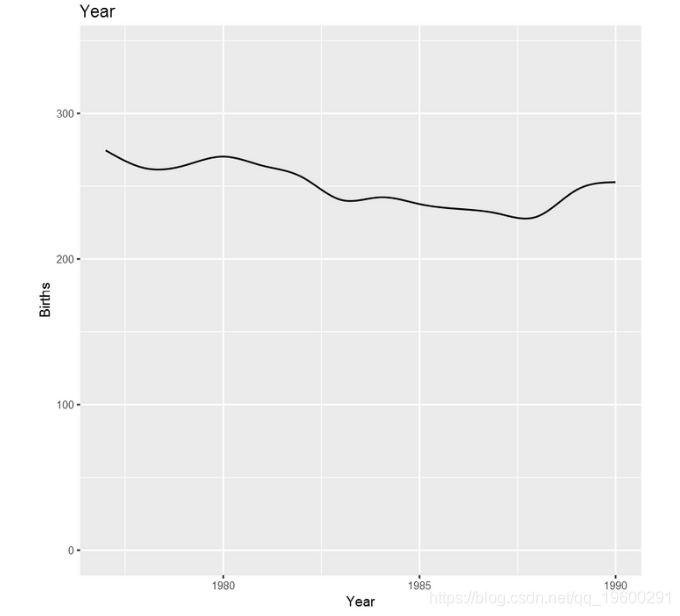

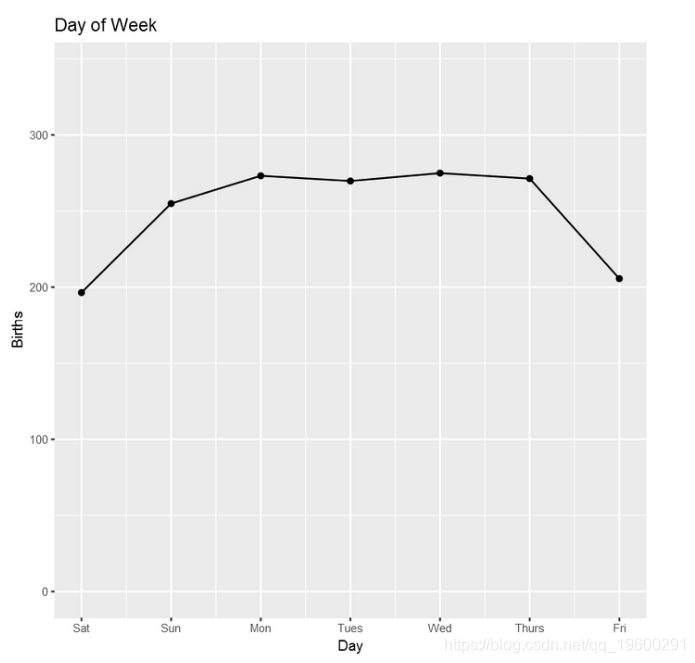

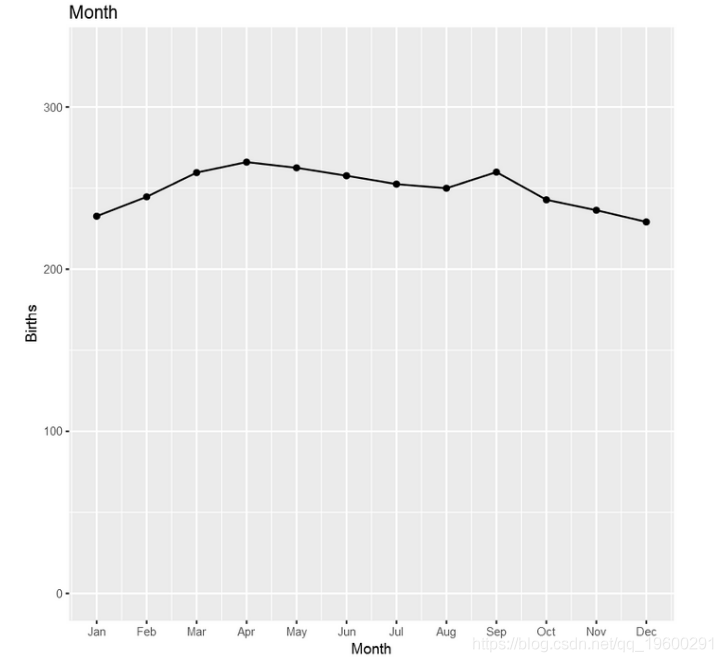

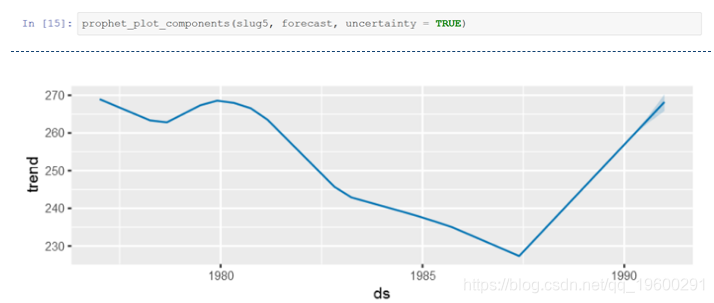
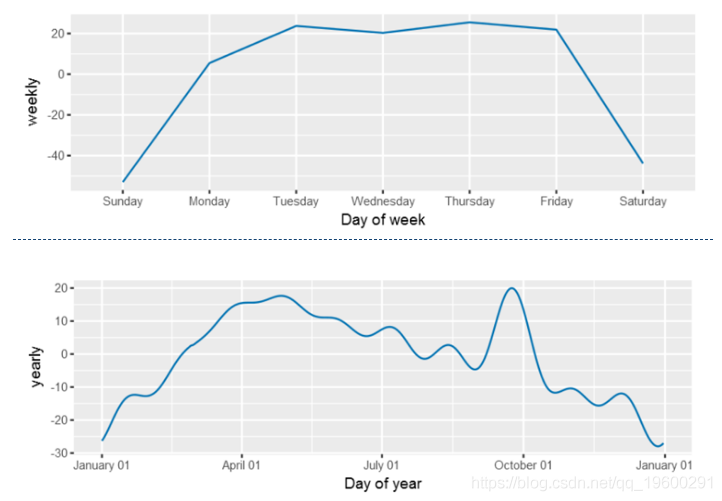
接下来,绘制 模型的组成部分,看起来与上图非常相似- 使用的是一年中的日期而不是月份。


最后,使用测试数据比较3属性lm模型,gam模型,先知模型和随机森林模型。在每个面板中,灰色表示实际值,而颜色表示模型预测。lm,gam和先知的表现相似,而随机森林滞后。
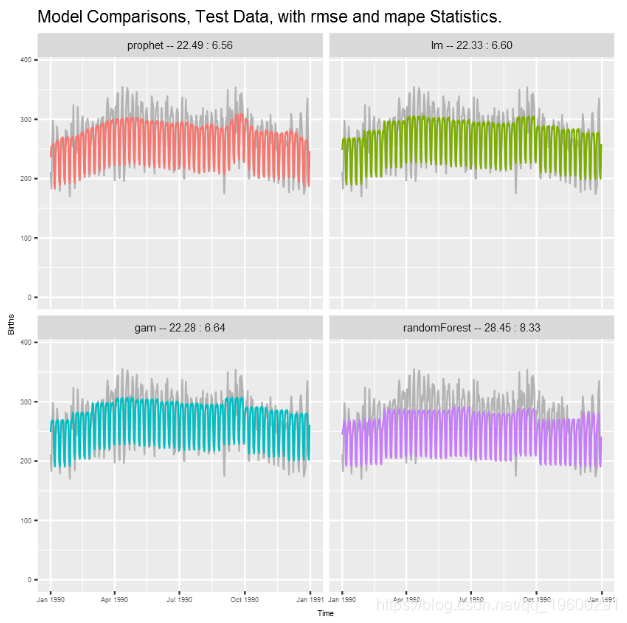

利用这些特定的数据,先知,lm和gam模型的测试预测非常相似,并且优于randomForest。
 【视频】因子分析简介及R语言应用实例:对地区经济研究分析重庆市经济指标
【视频】因子分析简介及R语言应用实例:对地区经济研究分析重庆市经济指标 R语言宏观经济学:IS-LM曲线可视化货币市场均衡
R语言宏观经济学:IS-LM曲线可视化货币市场均衡 R语言代做编程辅导和解答GLM Coursework
R语言代做编程辅导和解答GLM Coursework R语言分析上海空气质量数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法
R语言分析上海空气质量数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法


