自组织映射 (SOM)是一种工具,通过生成二维表示来可视化高维数据中的模式,在高维结构中显示有意义的模式。
通过以下方式使用给定的数据(或数据样本)对SOM进行“训练”:
- 定义了网格的大小。
- 网格中的每个单元都在数据空间中分配了一个初始化向量。
- 例如,如果要创建22维空间的地图,则会为每个网格单元分配一个22维向量。
自组织映射(self-organizing-map)SOM神经网络
自组织映射的主要目的是将任意维数的输入信号模式转变为一维或者二维的离散映射。并且以拓扑有序的方式自适应实现这个变换。
网格中的每个神经元和输入层的源节点全连接,这个网络表示具有神经元按行和列排列的单一计算层的前馈结构。
在自组织映射形成过程种有三种主要的过程:
-
竞争。多每个输入模式,网络中计算他们各自的判别的函数值,这个判别函数为神经元之间的竞争提供了竞争的基础。判别函数的最大值的神经元为竞争的胜利者。
-
合作。获胜的神经元决定兴奋神经元的拓扑领域的空间位置,从而提供这样的相邻神经元合作基础
-
突触调节。这个机制使兴奋神经元通过对他们图抽权值的适当调节以增加他们关于该输入模式的判别函数值。所做的调节使获胜的神经元对以后相似输入模式的响应增强了。
数据被反复输入到模型中进行训练。每次输入训练向量时,都会执行以下过程:
- 识别具有最接近训练向量的代表向量的网格单元。
- 随着训练向量的多次输入,收敛的参数使调整变得越来越小,从而使地图稳定。
该算法赋予SOM的关键特征:数据空间中接近的点在SOM中更接近。因此,SOM可能是表示数据中的空间聚类的好工具。
Kohonen映射类型
下面的示例将使用2015/16 NBA赛季的球员统计数据。我们将查看每36分钟更新一次的球员统计信息。这些数据可从 http://www.basketball-reference.com/获得。我们已经清理了数据。
NBA <- read.csv("NBA_cleaned.csv",
sep = ",", header = T, check.names = FALSE)基本SOM
在创建SOM之前,我们需要选择要在其中搜索模式的变量。
colnames(NBA)## [1] "" "Player" "Pos" "Age" "Tm" "G" "GS"
## [8] "MP" "FG" "FGA" "FG%" "3P" "3PA" "3P%"
## [15] "2P" "2PA" "2P%" "FT" "FTA" "FT%" "ORB"
## [22] "DRB" "TRB" "AST" "STL" "BLK" "TOV" "PF"
## [29] "PTS"我们从简单示例开始:
som(scale(NBA[res1], grid = somgrid(6, 4, "rectangular")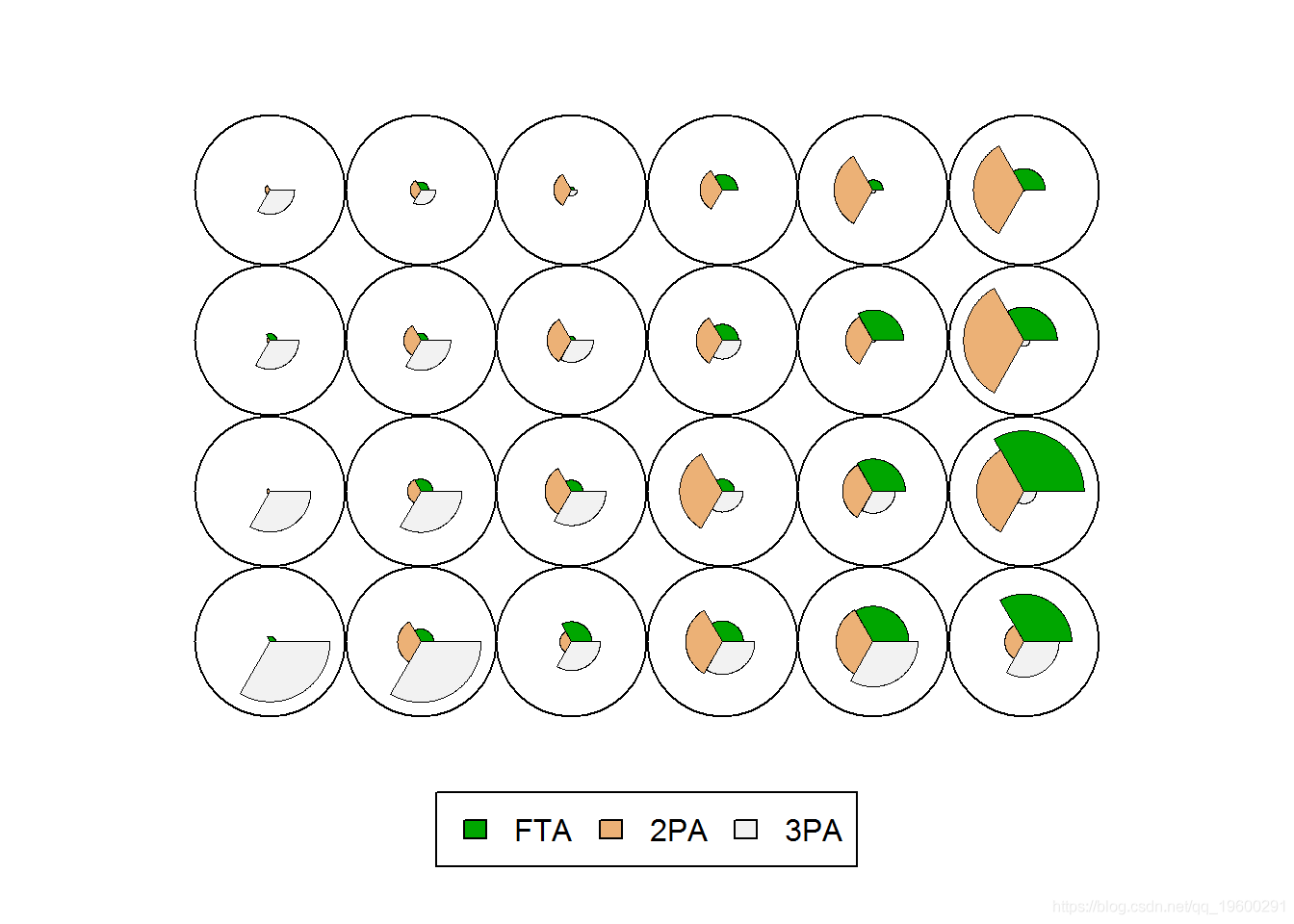
请注意,我们标准化了训练数据,并定义了网格大小。标准SOM图可为网格单元的代表矢量创建这些饼图表示,其中半径对应于特定维度上的大小。
热图SOM
我们可以通过将每个球员分配到具有最接近该球员状态的代表向量来识别地图。“计数”类型的SOM根据球员数量创建了一个热图。
# 色带
colors <- function(n, alpha = 1) {
rev(heat.colors(n, alpha))
}
绘图点
您可以使用“映射”类型的SOM将球员绘制为网格上的点。我们与常规SOM进行可视化比较。

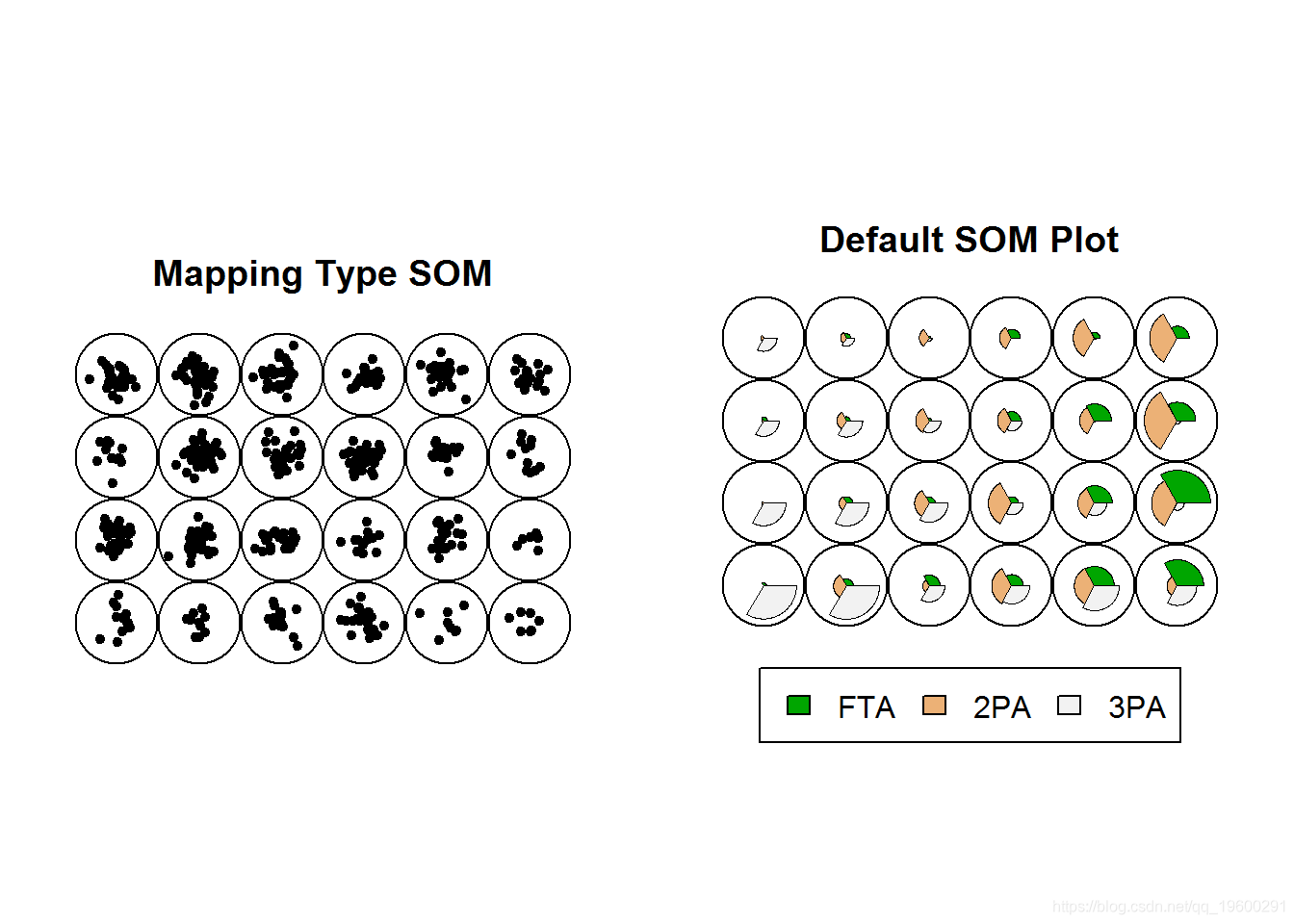
每个地图单元格的代表性矢量显示在右侧。左侧是根据其状态与这些代表向量的接近程度绘制的球员图表。
环形SOM
下一个示例是一种更改几何形状的方法。在为上述示例训练SOM时,我们使用了矩形网格。由于边缘(尤其是拐角处)的单元比内部单元具有更少的邻居,因此倾向于将更多的极端值推到边缘。
par(mfrow = c(1, 2))
plot(NBA.SOM2, type = "mapping", pchs = 20, main = "Mapping Type SOM")
plot(NBA.SOM2, main = "Default SOM Plot")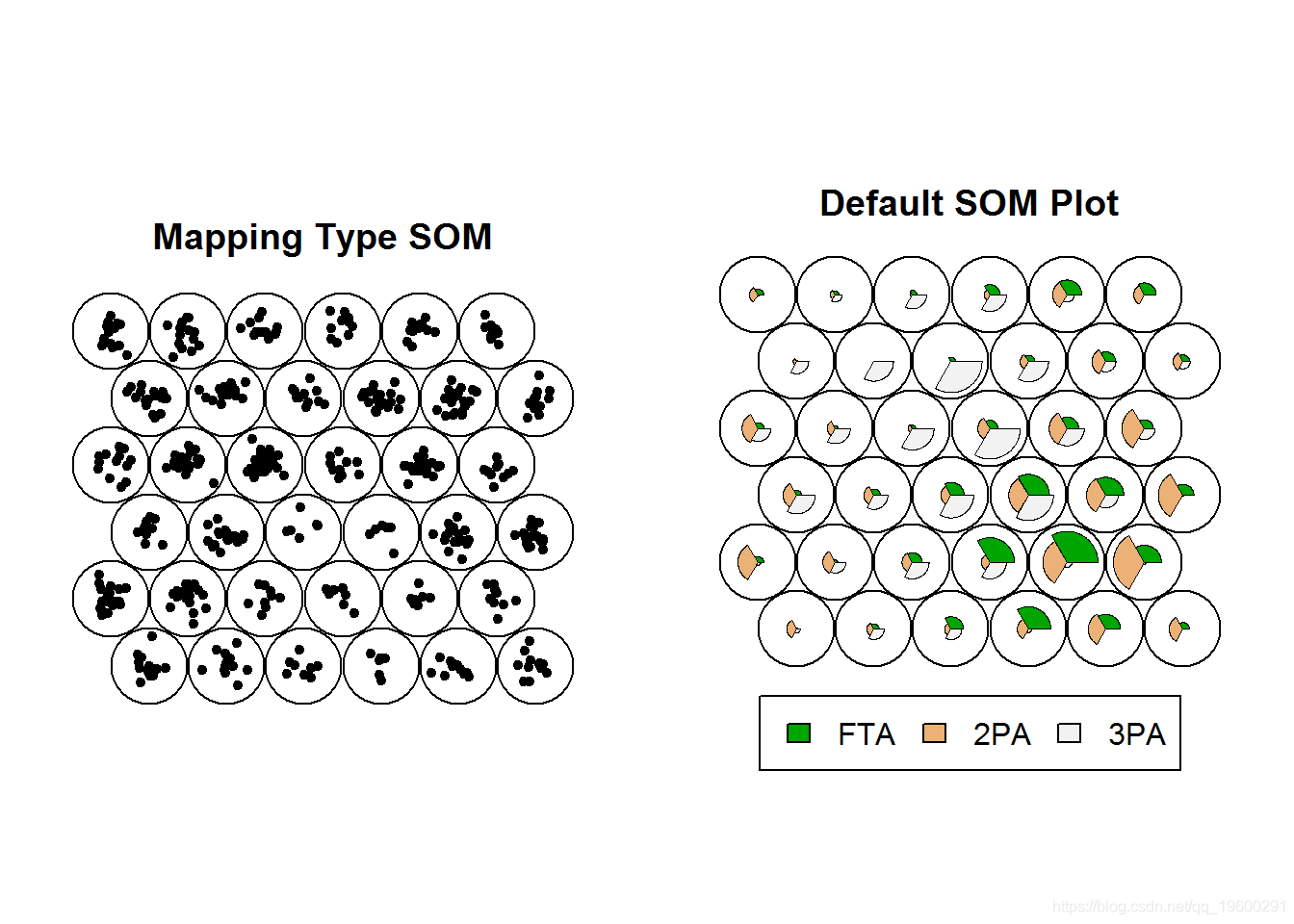
映射距离
当用绘制时 type = "dist.neighbours",单元格将根据与它们最近的邻居的距离着色,这使我们可以直观地看到高维空间中不同要素之间的距离。
plot(SOM2, type = "dist.neighbours")
有监督SOM
有监督的SOM使我们可以进行分类。到目前为止,我们仅将三维数据映射到二维。当我们处理更高维度的数据时,SOM的实用性变得更加明显,因此让我们使用扩展的球员统计信息列表来做这个受监督的示例:
我们创建有监督的SOM,并根据球员在球场上的位置对其进行分类。我们将数据随机分为训练集和测试集。
indices <- sample(nrow(NBA), 200)
training <- scale(NBA[indices, NBA.measures2])
testing <- scale(NBA[-indices, NBA.measures2], center = attr(training,
"scaled:center"), scale = attr(training, "scaled:scale"))请注意,当我们重新标准化测试数据时,我们需要根据训练数据的方式对其进行标准化。
您可以在训练算法中对训练变量(NBA.training)与预测变量(NBA$Pos)进行加权。现在让我们检查预测的准确性:
##
## Center Point Guard Power Forward Shooting Guard
## Center 16 0 26 1
## Point Guard 0 49 0 12
## Power Forward 10 1 29 5
## Shooting Guard 0 8 4 38
## Small Forward 0 0 15 9
##
## Small Forward
## Center 4
## Point Guard 11
## Power Forward 8
## Shooting Guard 19
## Small Forward 38可视化预测:
这次,我们使用xweight 参数为权重衡量球员统计数据 。
使用type = "codes" 我们进行绘制,可以 得到标准的可视化球员状态(Codes X)和球员位置预测(Codes Y)。
add.cluster.boundaries(NBA.SOM4, NBA.SOM4.hc)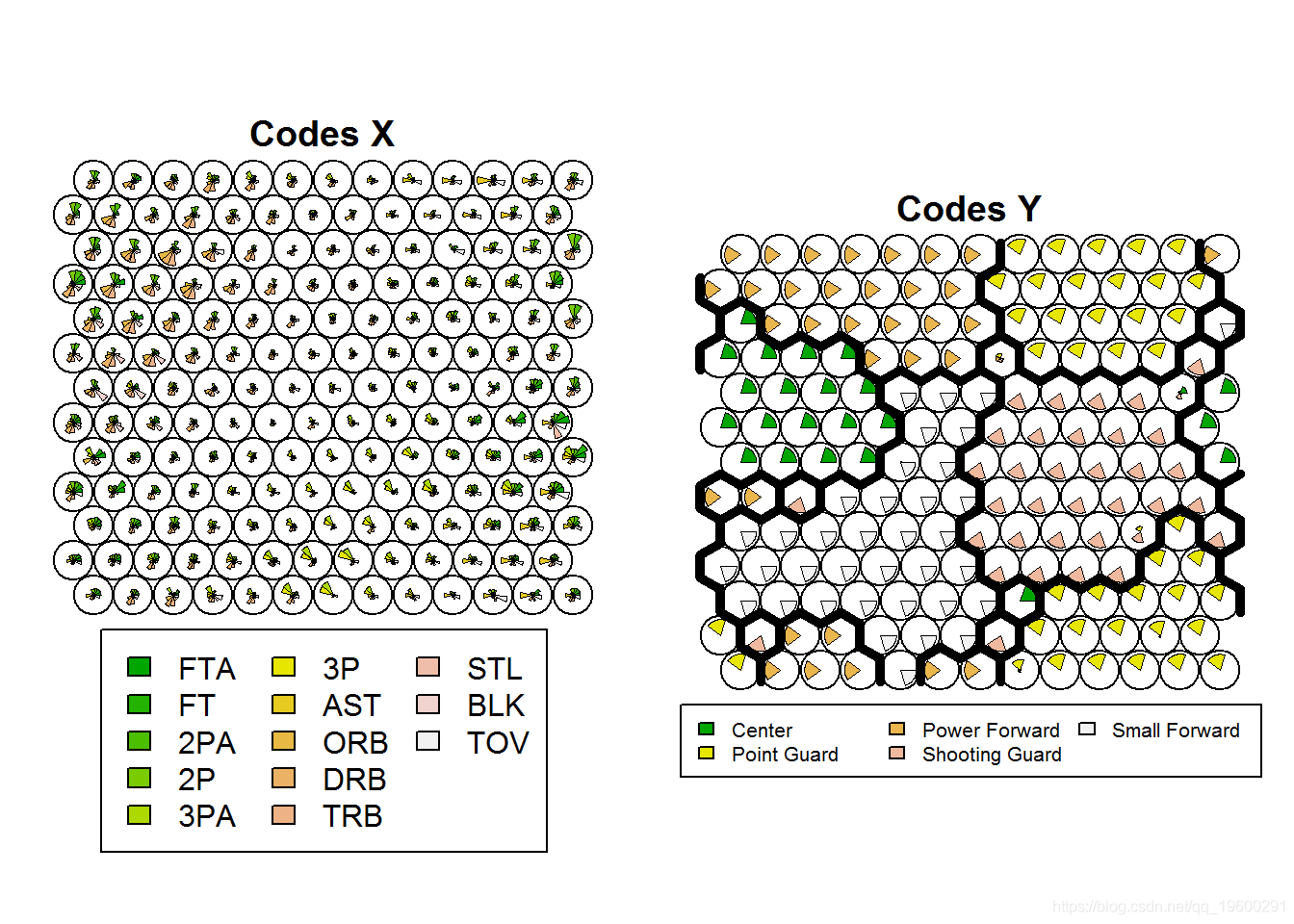
该视图使我们可以将球员统计数据与位置预测进行比较。
可视化预测:自定义SOM
在最后一个示例中,我们将对该type = mapping 图进行一些自定义, 以便我们可以同时表示实际球员位置和SOM的预测位置。我们将从可视化开始。
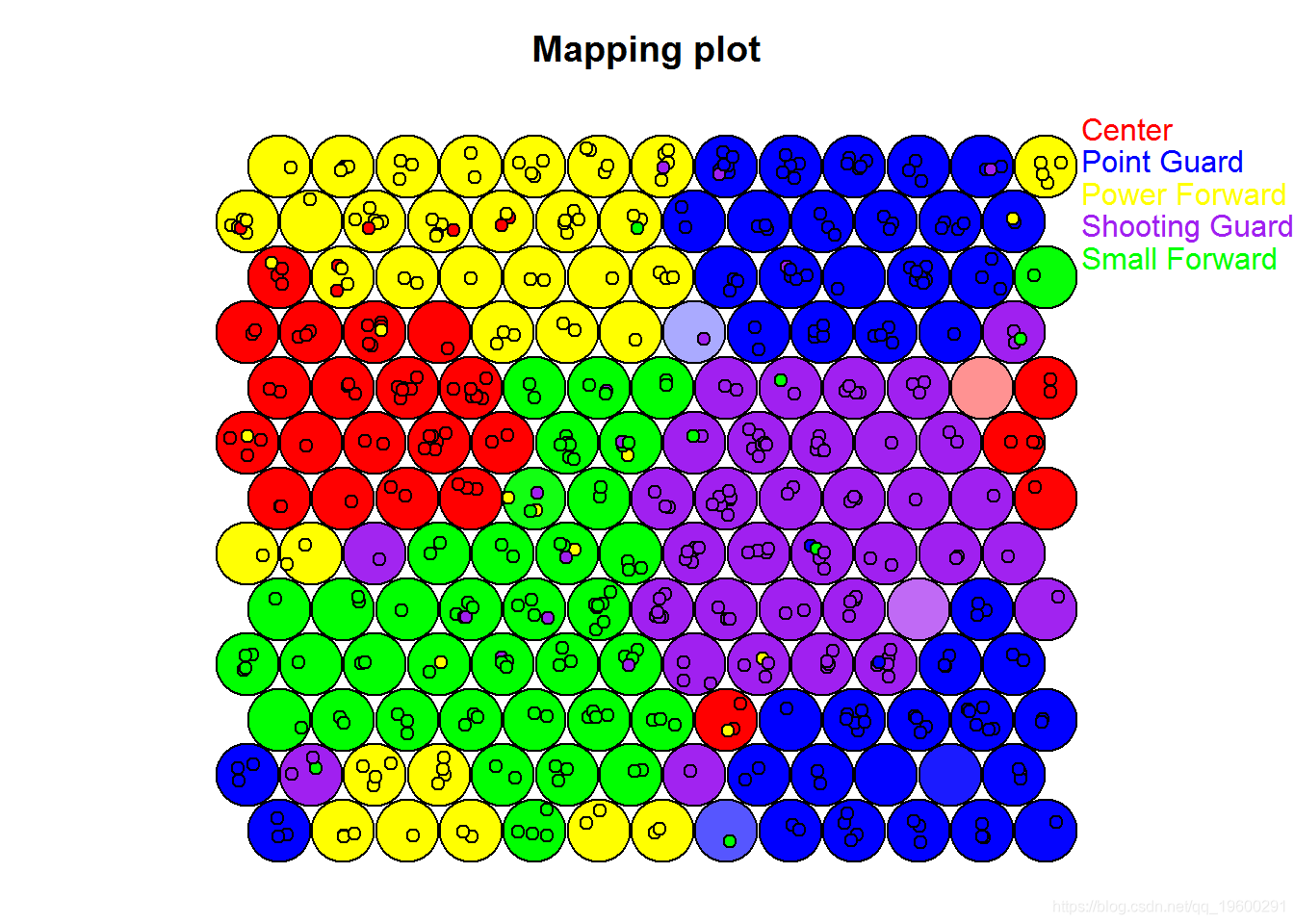 背景颜色绘制的球员点的背景代表其真实位置。
背景颜色绘制的球员点的背景代表其真实位置。
bg.pallet <- c("red", "blue", "yellow", "purple", "green")
# 为所有单元格制作仅背景颜色的矢量
base.color.vector <- bg.pallet[match(position.predictions, levels(NBA$Pos))]
# 设置alpha以最大的预测置信度标准化
max.conf <- apply(NBA.SOM4$codes$Y, 1, max)可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解:BSNet模型(双边监督网络)结合医学CT影像与半监督学习SSL、卷积神经网络CNN的图像分割方案
视频讲解:BSNet模型(双边监督网络)结合医学CT影像与半监督学习SSL、卷积神经网络CNN的图像分割方案 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 Python农产品产量预测数据分析:神经网络、PCA、随机森林、模型融合建模实践
Python农产品产量预测数据分析:神经网络、PCA、随机森林、模型融合建模实践


