在本文中,我们将介绍一些技巧和窍门,这些技巧和窍门用于在线查找所需数据,将其存储到计算机上以及如何识别和清除“脏”数据。我们还将回顾一些常见的数据格式,以及如何从一种转换为另一种。
我们今天将使用的数据
gdp_percap.csv 世界银行关于1990年至2016年国家和国家集团人均国内生产总值(GDP)的数据,以当前国际美元计价,并根据不同地区的购买力进行了校正。
ucb_stanford_2014.csv2014年从UC Berkeley和斯坦福大学获得的联邦政府拨款数据可从USASpending.gov下载。wr_50m_sept_6_2018.pdfPDF,其中包含来自国际泳联,游泳和其他水上运动国际联合会的最新世界游泳记录。
搜索在线数据库
可以在线搜索许多重要的公共数据库,有些提供下载查询结果的选项。这些数据库中的大多数都提供一个简单的搜索框,但始终值得寻找高级搜索页面,该页面将提供更多选项来自定义搜索。例如,这里是ClinicalTrials.gov的高级搜索页面:

当您开始使用新的联机数据库时,请花一些时间来熟悉其搜索的工作方式:阅读帮助或常见问题解答,然后运行测试搜索以查看获得的结果。
还要找出数据库是否允许“通配符”,例如*或%可以放在搜索中的通配符,以获得带有单词或数字变化的结果。
从网上抓取数据
有时,您需要根据散布在一系列网页中的信息或在不允许简单下载数据或访问API的数据库中维护的信息来编译自己的数据。这就是Web抓取的地方。
使用R或Python之类的编程语言,可以编写脚本来从许多网页提取数据,或者查询Web搜索表单以逐段下载整个数据库。
我们已经通过操作Web搜索表单上的url并批量下载各个链接来执行Web抓取的某些元素。
PDF:数据
一些组织坚持将数据提供为PDF,而不是文本文件,电子表格或数据库。这使得数据难以提取。尽管您始终应该以更友好的格式(最好是CSV或其他简单的文本文件)来请求数据, 有时可能会发现自己需要从PDF中提取数据。
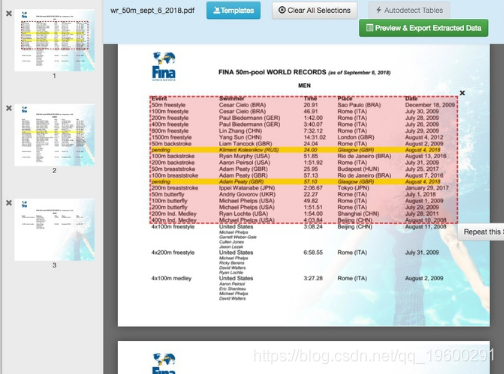
可以从数字PDFS中的表中提取数据。

启动 时,它会在Web浏览器中打开。但是,您加载到程序中的所有数据都将保留在计算机上-不会在线发布。
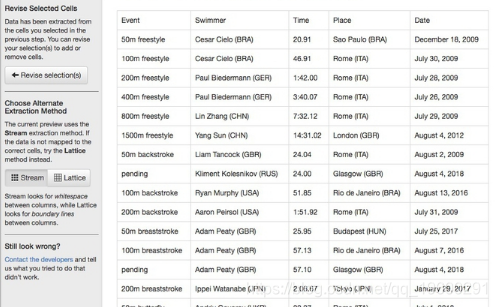

导入PDF后,突出显示第一张表中显示男子个人记录的部分单击Preview & Export Extracted Data以查看提取的数据:
识别脏数据
在理想的世界中,我们找到的每个数据集都会经过精心策划,使我们能够开始分析和可视化,而不必担心其准确性。
但是,实际上,通常最好的可用数据都有一些缺陷,可能需要尽可能地加以纠正。因此,在开始使用新数据集之前,请将其加载到电子表格或数据库中,并查看常见错误。例如,这里是来自BMIS数据库的记录示例,其名称包括非字母字符,这显然是错误的:
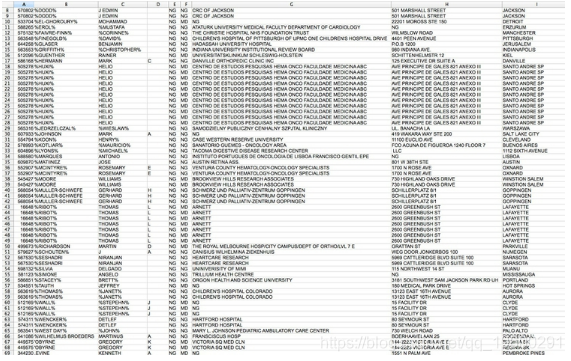

一些字段提供了一些明显的检查:例如,如果您看到的邮政编码少于5位,则知道它一定是错误的。
日期也可能输入错误,因此值得扫描那些不在数据范围之内的日期。
还要扫描代表连续变量的字段中的数字,以查找任何明显的异常值。
其他常见问题是某些条目前后的空白,可能需要将其删除。
使用Open Refine清理和处理数据
在许多数据新闻项目中,检查和清除“脏”数据以及将数据处理为所需的格式可能是最耗费人力的部分。但是,Open Refine(以前称为Google Refine)可以简化任务-还可以创建可复制的脚本,以对必须以相同方式清理和处理的数据快速重复该过程。
启动Open Refine时,它将在Web浏览器中打开。但是,您加载到程序中的所有数据都将保留在计算机上-不会在线发布。
打开屏幕应如下所示:
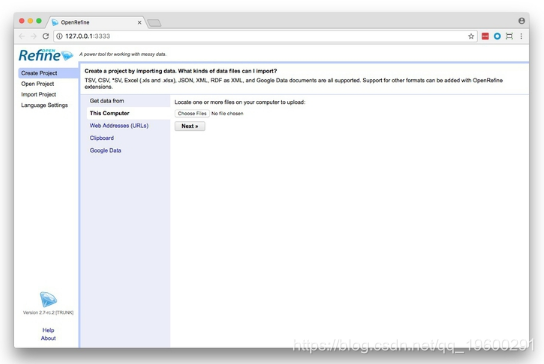

将数据从宽格式转换为长格式
单击Choose Files按钮并导航到文件gdp_percap.csv。单击Next>>,然后在下一个屏幕上确保Parse cell text into numbers, dates,...已选中
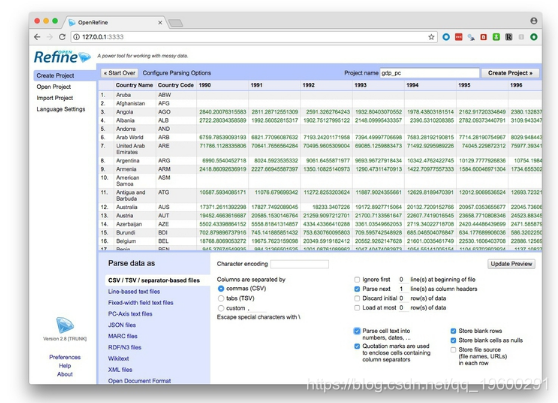

Open Refine以绿色显示数字和日期,以黑色显示整个文本。因此,选中此按钮应该使数字变为绿色。Open Refine还应该识别数据在CSV文件中,但是如果不是,则可以使用底部的面板为数据指定正确的文件类型和格式。
屏幕现在应如下所示:
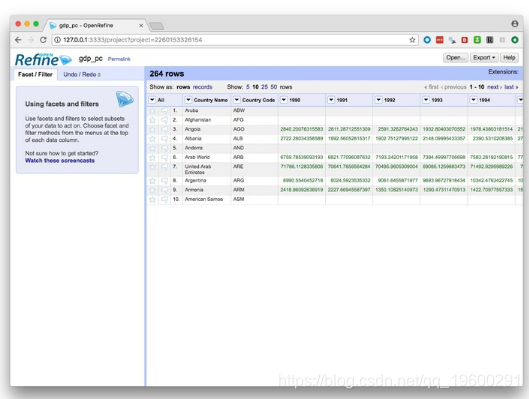

如您所见,数据是宽格式的,按区域组织了各地区的石油产量值,每年一次。要将其转换为长格式,请单击这些年的第一列中的向下的小三角形,然后选择Transpose>Transpose cells across columns into rows。
如下所示填写对话框,确保正确地将From Column和To Column突出显示,并为Key column和Value column指定了适当的名称,并进行了Fill down in other columns选中。
单击Transpose,然后单击50行链接,以查看调整后的数据的前50行:
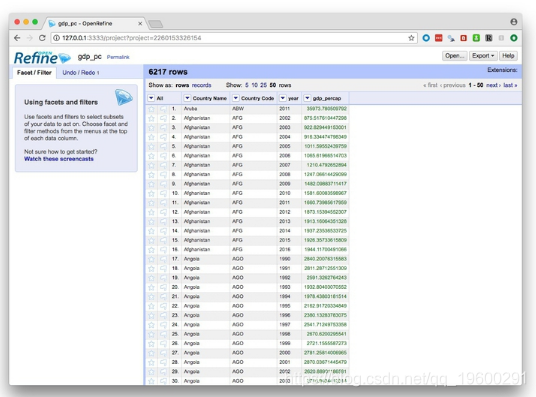

单击右上角的Export按钮,您将看到用于以各种文件类型(包括Comma-separated value和Excel电子表格)导出数据的选项。
清理和处理脏数据
单击左上角的“打开优化” 以返回到打开屏幕。从文件创建一个新项目ucb_stanford_2014.csv。
同样,每个字段/列都有一个带有指向下方的三角形的按钮。单击这些按钮,您将获得为列创建“构面”的选项,这提供了一种强大的方式来编辑和清除数据。
AllOpen Refine中的列下拉菜单可用于删除不需要的列并快速记录要保留的列。选择Edit Columns>Re-order / remove columns以弹出此对话框:
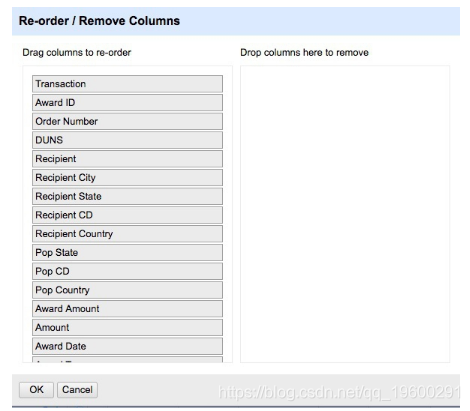

但是,在这里我们将保留所有数据。
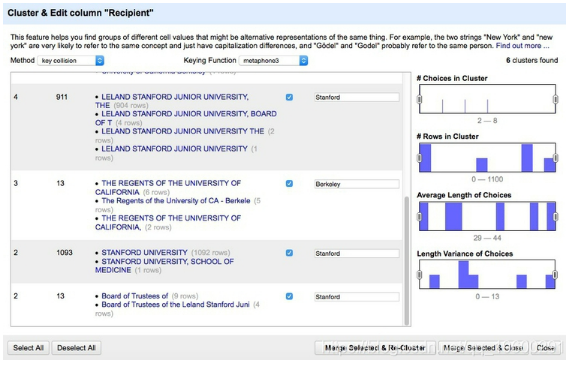
我们可以手动进行编辑,但是要说明Open Refine的编辑功能,请单击Cluster按钮。在这里,您可以尝试使用不同的聚类算法来编辑:

非常感谢您阅读本文,有任何问题请在下面留言!
1
1
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察
专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 Python基于SVM和RankGauss的低消费指数构建模型
Python基于SVM和RankGauss的低消费指数构建模型


