ARIMA模型是一种流行的且广泛使用的用于时间序列预测的统计方法。
ARIMA是首字母缩写词,代表自动回归移动平均。
它是一类模型,可在时间序列数据中捕获一组不同的标准时间结构。
可下载资源
在本教程中,您将发现如何使用Python开发用于时间序列数据的ARIMA模型。
完成本教程后,您将知道:
- 关于ARIMA模型,使用的参数和模型所作的假设。
- 如何使ARIMA模型适合数据并使用它进行预测。
- 如何针对您的时间序列问题配置ARIMA模型。
它明确地迎合了时间序列数据中的一组标准结构,因此提供了一种简单而强大的方法来进行熟练的时间序列预测。
ARIMA是首字母缩写词,代表自动回归移动平均线。它是对简单的自动回归移动平均线的概括,并增加了差分的概念。
该首字母缩写是描述性的。简而言之,它们是:
- AR: 自回归。一种模型,它使用观察值和一些滞后观察值之间的依赖关系。
- I: 综合。为了使时间序列平稳,使用原始观测值的差异(例如,从上一个时间步长的观测值中减去观测值)。
- MA: 移动平均。一种模型,该模型使用观察值与应用于滞后观察值的移动平均模型的残差之间的依赖关系。
每一个都在模型中明确指定为参数。使用ARIMA(p,d,q),其中参数替换为整数值以快速指示所使用的特定ARIMA模型。
ARIMA模型的参数定义如下:
- p:模型中包括的滞后观测值的数量,也称为滞后阶数。
- d:原始观测值相差的次数,也称为相异度。
- q:移动平均窗口的大小,也称为移动平均的顺序。
构建包括指定数量和类型的项的线性回归模型,并通过一定程度的差分来准备数据,以使其保持平稳,即消除对回归模型产生负面影响的趋势和季节结构。
可以将值0用作参数,这表示不使用模型的该元素。这样,可以将ARIMA模型配置为执行ARMA模型甚至简单的AR,I或MA模型的功能。
对于时间序列采用ARIMA模型,则假定生成观测值的基础过程是ARIMA过程。这看起来似乎很明显,但是有助于激发需要在原始观测值和模型预测的残差中确认模型的假设。
接下来,让我们看一下如何在Python中使用ARIMA模型。我们将从加载简单的单变量时间序列开始。
洗发水销售数据集
该数据集描述了3年期间洗发水的每月销售量。
单位是销售数量,有36个观察值。
下载数据集并将其放在文件名“ shampoo-sales.csv ”的当前工作目录中。
下面是使用自定义函数解析日期时间字段的加载销售数据集的示例。数据集以任意年份为基准,在这种情况下为1900。
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
print(series.head())
series.plot()
pyplot.show()
运行示例将输出数据集的前5行。
Month
1901-01-01 266.0
1901-02-01 145.9
1901-03-01 183.1
1901-04-01 119.3
1901-05-01 180.3
Name: Sales, dtype: float64随时关注您喜欢的主题
数据还绘制为时间序列,其中x轴为月份,y轴为销售数字。
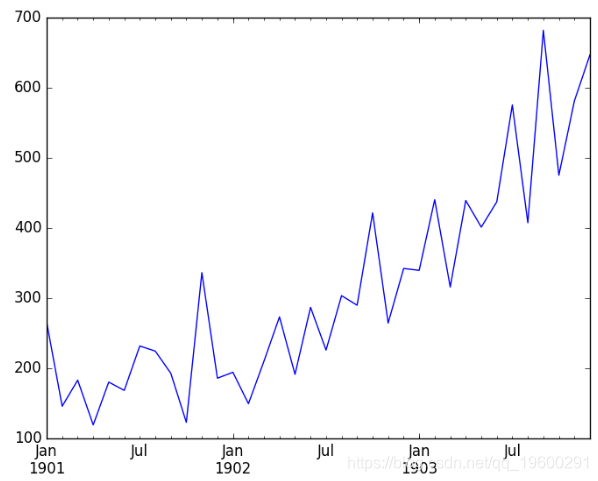
洗发水销售数据集图
我们可以看到,洗发水销售数据集具有明显的趋势。
这表明时间序列不是平稳的,并且需要进行差分才能使其稳定,至少相差1。
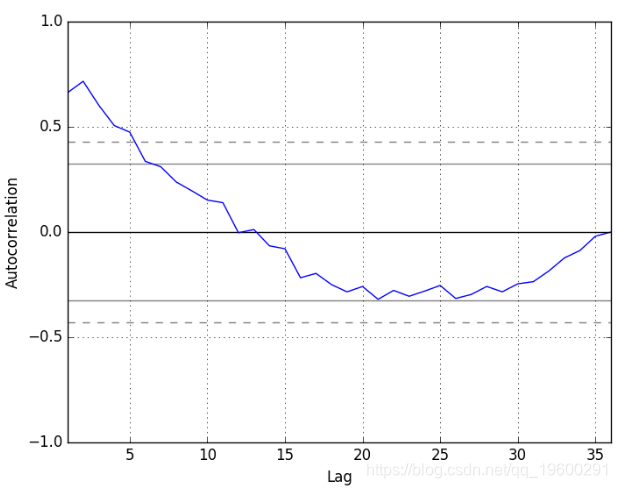
我们还快速浏览一下时间序列的自相关图。下面的示例绘制了时间序列中滞后的自相关。
通过运行示例,我们可以看到与前10到12个之后之间存在正相关,这可能对前5个之后具有显着的意义。
首先,我们拟合ARIMA(5,1,0)模型。
这会将自回归的滞后值设置为5,使用1的差分阶数使时间序列平稳,并使用0的移动平均模型。
拟合模型时,会提供许多有关线性回归模型拟合的调试信息。我们可以通过将disp 参数设置为0 来关闭此功能 。
运行示例将显示拟合模型的摘要。这总结了所使用的系数值以及对样本中观测值进行拟合的技巧。
ARIMA Model Results
==============================================================================
Dep. Variable: D.Sales No. Observations: 35
Model: ARIMA(5, 1, 0) Log Likelihood -196.170
Method: css-mle S.D. of innovations 64.241
Date: Mon, 12 Dec 2016 AIC 406.340
Time: 11:09:13 BIC 417.227
Sample: 02-01-1901 HQIC 410.098
- 12-01-1903
=================================================================================
coef std err z P>|z| [95.0% Conf. Int.]
---------------------------------------------------------------------------------
const 12.0649 3.652 3.304 0.003 4.908 19.222
ar.L1.D.Sales -1.1082 0.183 -6.063 0.000 -1.466 -0.750
ar.L2.D.Sales -0.6203 0.282 -2.203 0.036 -1.172 -0.068
ar.L3.D.Sales -0.3606 0.295 -1.222 0.231 -0.939 0.218
ar.L4.D.Sales -0.1252 0.280 -0.447 0.658 -0.674 0.424
ar.L5.D.Sales 0.1289 0.191 0.673 0.506 -0.246 0.504
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 -1.0617 -0.5064j 1.1763 -0.4292
AR.2 -1.0617 +0.5064j 1.1763 0.4292
AR.3 0.0816 -1.3804j 1.3828 -0.2406
AR.4 0.0816 +1.3804j 1.3828 0.2406
AR.5 2.9315 -0.0000j 2.9315 -0.0000
-----------------------------------------------------------------------------首先,我们得到了残差的线形图,这表明该模型可能仍未捕获某些趋势信息。
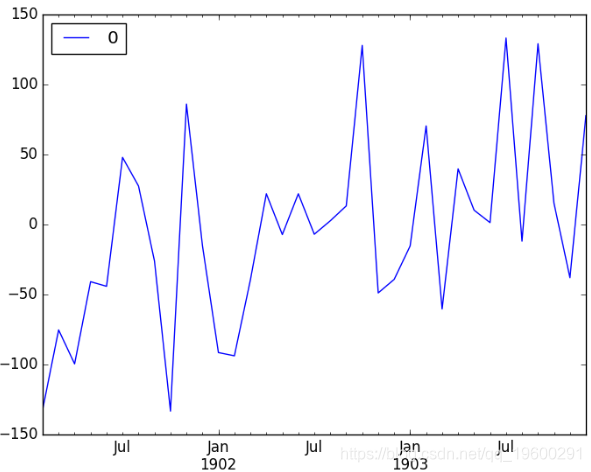
ARMA拟合残差线图
接下来,我们获得了残留误差值的密度图,表明误差为高斯分布。
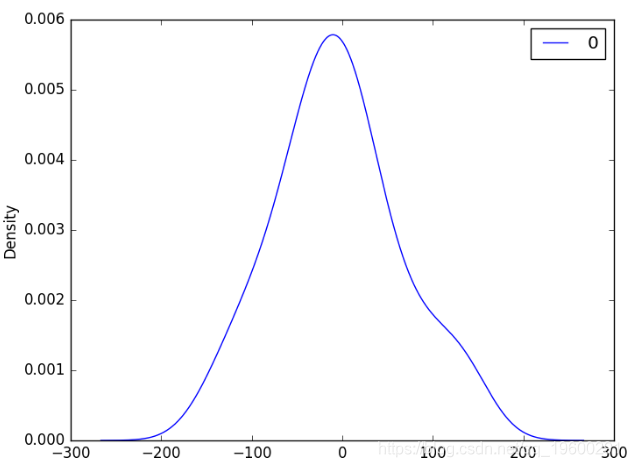
ARMA拟合残差密度图
显示剩余误差的分布。结果表明,确实在预测中存在偏差(残差均值非零)。
count 35.000000
mean -5.495213
std 68.132882
min -133.296597
25% -42.477935
50% -7.186584
75% 24.748357
max 133.237980请注意,尽管上面我们将整个数据集用于时间序列分析,但理想情况下,在开发预测模型时,我们仅对训练数据集执行此分析。
接下来,让我们看看如何使用ARIMA模型进行预测。
滚动预测ARIMA模型
ARIMA模型可用于预测未来的时间步长。
我们可以在ARIMAResults 对象上使用predict()函数 进行预测。它接受时间步长索引作为参数进行预测。这些索引与用于进行预测的训练数据集的开始有关。
如果我们在训练数据集中使用100个观察值来拟合模型,则将用于进行预测的下一个时间步长的索引指定为预测函数 start = 101,end = 101。这将返回一个包含一个包含预测的元素的数组。
如果我们进行了任何微分( 在配置模型时d> 0),我们也希望预测值在原始比例内。这可以通过将typ 参数设置为值 ‘levels’来指定 : typ =’levels’。
或者,我们可以通过使用Forecast() 函数避免使用所有这些规范,该 函数使用模型执行一步式预测。
我们可以将训练数据集分为训练集和测试集,使用训练集拟合模型,并为测试集上的每个元素生成预测。
鉴于对差分和AR模型的先前时间步长依赖于观察结果,因此需要滚动预测。执行此滚动预测的一种粗略方法是在收到每个新观测值后重新创建ARIMA模型。
我们手动在称为历史记录的列表中跟踪所有观察值,并且每次迭代都将新的观察值附加到该列表中。
综上所述,以下是ARIMA模型在Python中进行滚动预测的示例。
运行示例将在每次迭代时打印预测值和期望值。
我们还可以计算预测的最终均方误差得分(MSE),为其他ARIMA配置提供比较点。
predicted=349.117688, expected=342.300000
predicted=306.512968, expected=339.700000
predicted=387.376422, expected=440.400000
predicted=348.154111, expected=315.900000
predicted=386.308808, expected=439.300000
predicted=356.081996, expected=401.300000
predicted=446.379501, expected=437.400000
predicted=394.737286, expected=575.500000
predicted=434.915566, expected=407.600000
predicted=507.923407, expected=682.000000
predicted=435.483082, expected=475.300000
predicted=652.743772, expected=581.300000
predicted=546.343485, expected=646.900000
Test MSE: 6958.325创建一个折线图,显示与滚动预测预测(红色)相比的期望值(蓝色)。我们可以看到这些值显示出一些趋势并且处于正确的范围内。
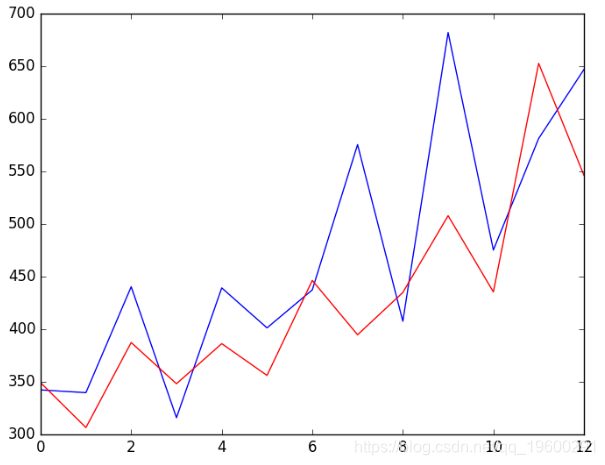
ARIMA滚动预测线图
该模型可以使用对p,d甚至q参数的进一步调整。
配置ARIMA模型
拟合ARIMA模型的经典方法是遵循 Box-Jenkins方法论。
此过程使用时间序列分析和诊断来发现ARIMA模型的良好参数。
总而言之,此过程的步骤如下:
- 模型识别。使用图和汇总统计信息来识别趋势,季节性和自回归元素,以了解差异量和所需滞后的大小。
- 参数估计。使用拟合过程来找到回归模型的系数。
- 模型检查。使用残差图和统计检验确定模型未捕获的时间结构的数量和类型。
重复该过程,直到在样本内或样本外观察值(例如训练或测试数据集)上达到理想的拟合水平为止。
在1970年经典的教科书中 ,George Box和Gwilym Jenkins 题为“ 时间序列分析:预测和控制”,对这一过程进行了描述 。如果您有兴趣深入研究这种类型的模型和方法,现在可以提供更新的第五版。
鉴于该模型可以有效地适合中等大小的时间序列数据集,因此该模型的网格搜索参数可能是一种有价值的方法。
摘要
在本教程中,您发现了如何为Python中的时间序列预测开发ARIMA模型。
具体来说,您了解到:
- 关于ARIMA模型,如何配置它以及模型进行的假设。
- 如何使用ARIMA模型执行快速的时间序列分析。
- 如何使用ARIMA模型进行样本预测之外的预测。
您对ARIMA或本教程有任何疑问吗?
在下面的评论中提出您的问题,我们会尽力回答。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据

