
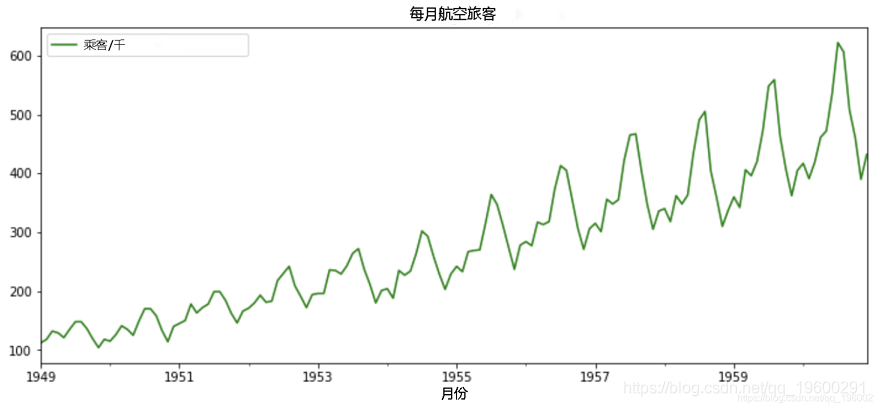
时间序列 被定义为一系列按时间顺序索引的数据点。时间顺序可以是每天,每月或每年。
以下是一个时间序列示例,该示例说明了从1949年到1960年每月航空公司的乘客数量。
ETS模型
之前介绍的指数模型都可拆分为三个部分:
-
误差项(Error) 可以是相加模型或相乘模型
-
趋势项(Trend)可以是无、相加模型、相乘模型
-
季节项(Seasonality)可以是无、相加模型、相乘模型
这三个部分的任意组合构成了ETS模型,ETS可以理解为Error,Trend,Seasonality,也可以理解为ExponenTial Smoothing模型。
-
ETS模型采用最大似然法进行参数估计
-
误差项为相加模型时,最大似然法等价于使SSE最小来进行参数估计
-
自动尝试不同的ETS各项组合并通过使AICc最小来选择最佳模型
作者:新云旧雨
链接:https://www.jianshu.com/p/961df4ffcfa4
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
时间序列预测
时间序列预测是使用统计模型根据过去的结果预测时间序列的未来值的过程。
时间序列预测是一种通过分析历史时间序列数据(如按时间顺序排列的销售数据、股票价格、气温等),来预测未来某一时间段内该数据的发展趋势和具体数值的方法。它利用数学模型和统计技术,考虑时间序列数据的趋势性、季节性、周期性等特征,以确定未来可能的取值。例如,通过对过去几年每月的销售额进行时间序列预测,可以帮助企业制定生产计划和库存管理策略;对股票价格的时间序列预测可以辅助投资者做出投资决策。
一些示例
- 预测未来的客户数量。
- 检测异常事件并估计其影响的程度。
- 估计新推出的产品对已售出产品数量的影响。
- 解释销售中的季节性模式。
时间序列的组成部分:
时间序列是按时间顺序排列的一组数据。时间序列的组成部分通常包括趋势、季节性、周期性和随机性。
趋势是时间序列在长期内的总体变化方向,可以是上升、下降或保持稳定。例如,经济增长可能会导致某一产品的销售量在较长时间内呈现上升趋势。
季节性是指在一年内以固定周期重复出现的变化。比如,某些商品的销售在特定季节会有明显的增加,如冬季的羽绒服销售。
周期性是指时间序列中出现的较长周期的波动,通常与经济周期等因素有关。
随机性则是时间序列中无法预测的随机波动部分。
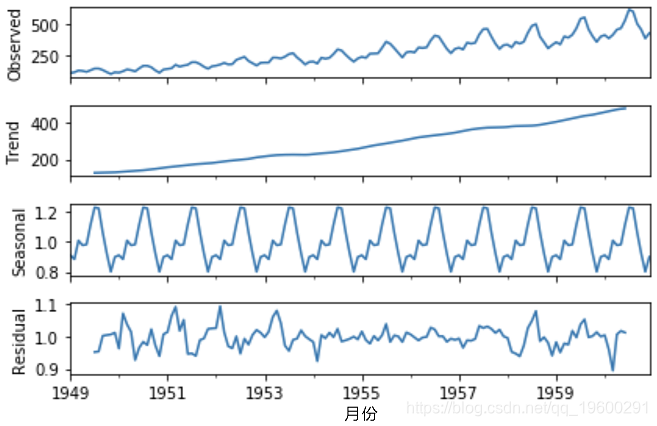
代码:航空公司乘客的ETS分解数据集:

# 导入所需的库
import numpy as np
# 读取AirPassengers数据集
airline = pd.read_csv('data.csv',
index_col ='Month',
parse_dates = True)
# 输出数据集的前五行
airline.head()
# ETS分解
# ETS图
result.plot()输出:
ARIMA时间序列预测模型
ARIMA代表自回归移动平均模型,由三个阶数参数 (p,d,q)指定。

ARIMA模型的类型
自动ARIMA
“ auto_arima” 函数 可帮助我们确定ARIMA模型的最佳参数,并返回拟合的ARIMA模型。
代码:ARIMA模型的参数分析
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
# 将自动arima函数拟合到AirPassengers数据集
autoarima(airline['# Passengers'], start_p = 1, start_q = 1,
max_p = 3, max_q = 3, m = 12,
stepwise = True # 设置为逐步
# 输出摘要
stepwise_fit.summary()随时关注您喜欢的主题
输出:
代码:将ARIMA模型拟合到AirPassengers数据集
# 将数据拆分为训练/测试集
test = iloc[len(airline)-12:] # 设置一年(12个月)进行测试
# 在训练集上拟合一个SARIMAX(0,1,1)x(2,1,1,12)
SARIMAX(Passengers,
order = (0, 1, 1),
seasonal_order =(2, 1, 1, 12
result.summary()
想了解更多关于模型定制、咨询辅导的信息?
输出:
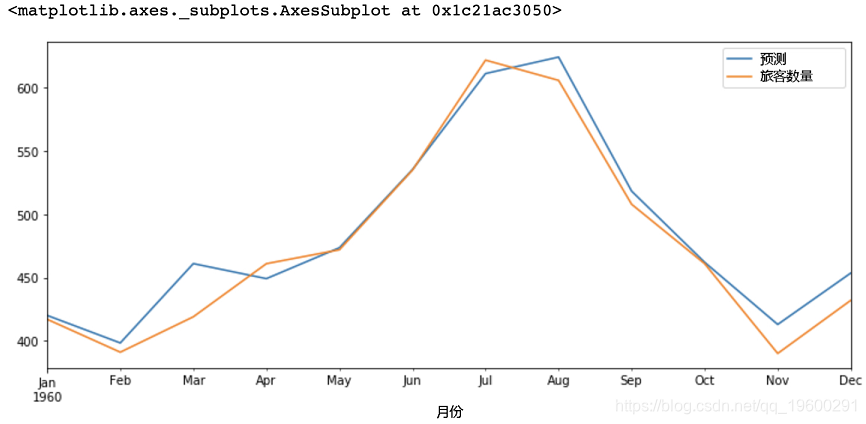
ARIMA模型对测试集的预测
# 针对测试集的一年预测
predict(start, end,
#绘图预测和实际值
predictions.plot 输出:
使用MSE和RMSE评估模型
代码:
# 加载特定的评估工具
# 计算均方根误差
rmse(test["# Passengers"], predictions)
# 计算均方误差
mean_squared_error(test["# Passengers"], predictions)输出:

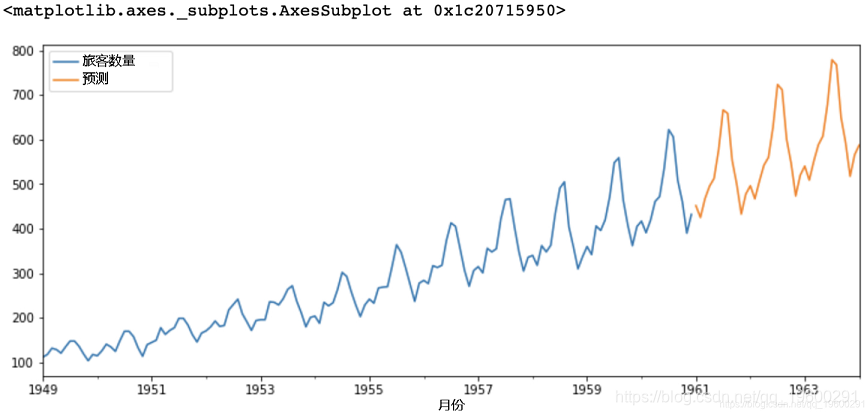
代码:使用ARIMA模型进行预测
# 在完整数据集上训练模型
result = model.fit()
# 未来3年预测
result.predict(start = len(airline),
end = (len(airline)-1) + 3 * 12,
# 绘制预测值
forecast.plot(legend = True)输出:
- 趋势:趋势显示了长时间序列数据的总体方向。趋势可以是增加(向上),减少(向下)或水平(平稳)。
- 季节性:季节性成分在时间,方向和幅度方面表现出重复的趋势。一些例子包括由于炎热的天气导致夏季用水量增加,或每年假期期间航空公司乘客人数增加。
- 周期性成分: 这些是在特定时间段内没有稳定重复的趋势。周期是指时间序列的起伏,通常在商业周期中观察到。这些周期没有季节性变化,但通常会在3到12年的时间范围内发生,具体取决于时间序列的性质。
- 不规则变化: 这些是时间序列数据中的波动,当趋势和周期性变化被删除时,这些波动变得明显。这些变化是不可预测的,不稳定的,并且可能是随机的,也可能不是随机的。
- ETS分解
ETS分解用于分解时间序列的不同部分。ETS一词代表误差、趋势和季节性。 - AR(_p_)自回归 –一种回归模型,利用当前观测值与上一个期间的观测值之间的依存关系。自回归(_AR(p)_)分量是指在时间序列的回归方程中使用过去的值。
- I(_d_) –使用观测值的差分(从上一时间步长的观测值中减去观测值)使时间序列稳定。差分涉及将序列的当前值与其先前的值相减d次。
- MA(_q_)移动平均值 –一种模型,该模型使用观测值与应用于滞后观测值的移动平均值模型中的残留误差之间的相关性。移动平均成分将模型的误差描述为先前误差项的组合。 q 表示要包含在模型中的项数。
- ARIMA:非季节性自回归移动平均模型
- SARIMA:季节性ARIMA
- SARIMAX:具有外生变量的季节性ARIMA
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证
Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察
专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
