
时序数据的聚类方法
去年,我们为一位客户进行了短暂的咨询工作,他正在构建一个主要基于KShape的分析应用程序。该算法按照以下流程执行。
- 使用基于互相关测量的距离标度(基于形状的距离:SBD)
- 根据 1 计算时间序列聚类的质心。(一种新的基于质心的聚类算法,可保留时间序列的形状)
- 划分成每个簇的方法和一般的kmeans一样,但是在计算距离尺度和重心的时候使用上面的1和2。
×
如果关注不同序列在统计特性上的差异,那么可以提取时许的统计特征,基于提取的统计等特征进行计算欧式距离的KMeans的聚类,如果关注形状的相似,那么可以使用执行SBD计算距离的k-shape聚类。另外,如果想要捕捉时序的动态特性,也是可以使用深度学习的seq2seq对隐式向量进行聚类。
作为一种广泛的数据挖掘手段,时间序列聚类的用途,就个人理解来说,首先是辅助机器学习建模预测,可以把聚类结果作为一种特征放入模型中,当然也可以用于不同序列分类预测的标签,其次是,用于新品预测等,依据形状相似度,找到相似的产品,发现商品潜在的未来规律,等等。
k-shape算法优点就是针对形状计算距离,优点很鲜明,同时不得不说的是计算复杂度很高,且我们使用tslearn包进行聚类,是需要不同的序列长度一致的。
import pandas as pd

# 读取数据帧,将其转化为时间序列数组,并将其存储在一个列表中 tata = \[\] for i, df in enmee(dfs): # 检查每个时间序列数据的最大长度。 for ts in tsda: if len(s) > ln_a: lenmx = len(ts) # 给出最后一个数据,以调整时间序列数据的长度 for i, ts in enumerate(tsdata): dta\[i\] = ts + \[ts\[-1\]\] * n_dd # 转换为矢量 stack_list = \[\] for j in range(len(timeseries_dataset)): stack_list.append(data) # 转换为一维数组 trasfome\_daa = np.stack(ack\_ist, axis=0) return trafoed_data
数据集准备
# 文件列表
flnes= soted(go.ob('mpldat/smeda*.csv'))
# 从文件中加载数据帧并将其存储在一个列表中。 for ienme in fiemes: df = pd.read\_csv(filnme, indx\_cl=one,hadr=0) flt.append(df)
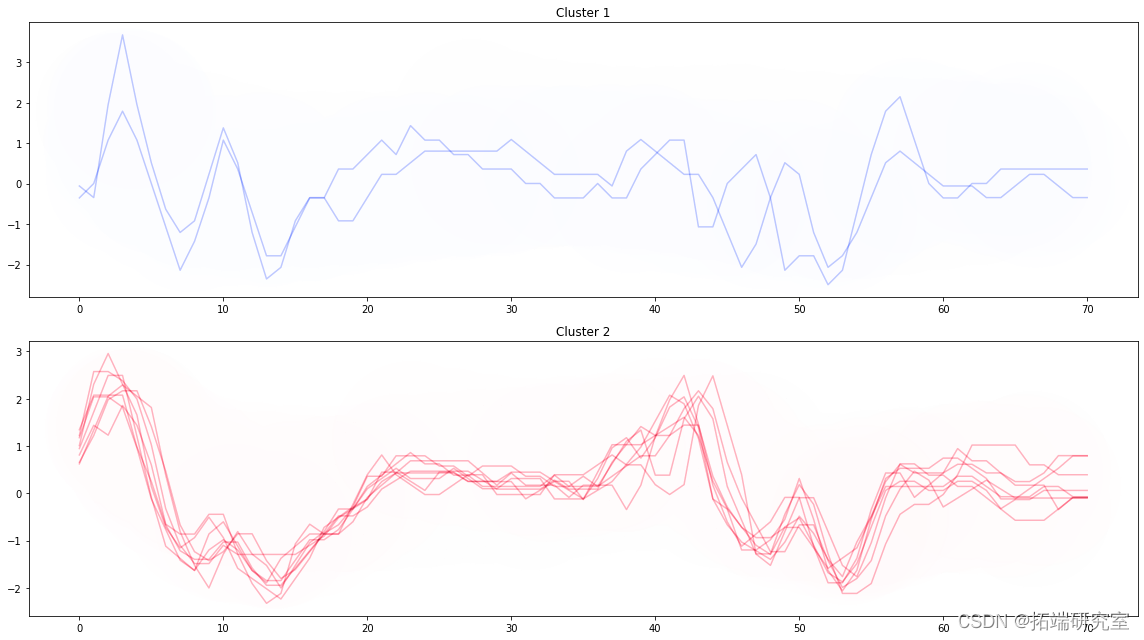
聚类结果的可视化
# 为了计算交叉关系,需要对它们进行归一化处理。 # TimeSeriesScalerMeanVariance将是对数据进行规范化的类。 sac\_da = TimeeiesalerMVarne(mu=0.0, std=1.0).fit\_trnform(tranfome_data) # KShape类的实例化。 ks = KShpe(\_clusrs=2, n\_nit=10, vrboe=True, rano_stte=sed) yprd = ks.ft\_reitsak\_ata) # 聚类和可视化 plt.tight_layout() plt.show()

用肘法计算簇数
- 什么是肘法…
- 计算从每个点到簇中心的距离的平方和,指定为簇内误差平方和 (SSE)。
- 它是一种更改簇数,绘制每个 SSE 值,并将像“肘”一样弯曲的点设置为最佳簇数的方法。
随时关注您喜欢的主题
#计算到1~10个群组 for i in range(1,11): #进行聚类计算。 ks.fit(sacdta) #KS.fit给出KS.inrta_ disorons.append(ks.netia_) plt.plot(range(1,11), disorins, marker='o')


可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据 Python+FPN+ResNet特征金字塔网络目标检测多尺度特征融合|附AI智能体、代码和数据
Python+FPN+ResNet特征金字塔网络目标检测多尺度特征融合|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

