客户流失/流失,是企业最重要的指标之一
因为获取新客户的成本通常高于保留现有客户的成本。
事实上,根据一个 study by Bain & Company,随着时间的推移,现有客户倾向于从公司购买更多产品,从而降低企业的运营成本,并可能将他们使用的产品推荐给其他人。
可下载资源
例如,在金融服务领域,客户保留率每增加 5%,利润就会增加 25% 以上。
通过使用生存分析,公司不仅可以预测客户是否可能停止开展业务,还可以预测该事件何时发生。
数据集
描述和概述
团队想要使用的数据集包含以下变量:
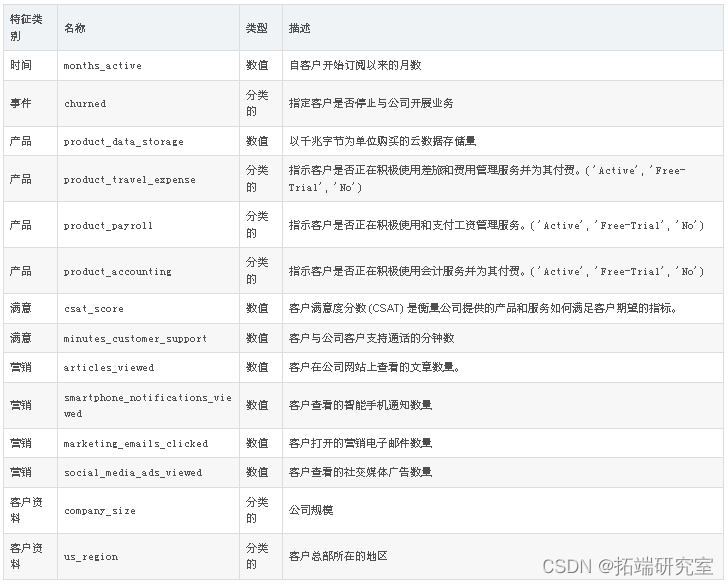
从分类到数值
有几个分类特征需要编码为 one-hot 向量:
# 创建向量 dtset = pd.get_dummies(rawdaset, columns=caegres) # 创建时间和事件列 timeolun = 'onth_tive ent_clmn = 'chuned' (事件列)。 # 提取特征 特征 = np.setdiff1d(daaet.oums, \[tie_olmn,\] ).tolist()
探索性数据分析
在这里,我们将只检查数据集是否包含 Null 值或是否有重复的行。然后,我们将看看特征相关性。
空值和重复
首先要做的是检查 raw_dataset 是否包含 Null 值和重复的行。
# 检查是否为空值 Null = sum(dtaet\[feaues\].isnull().sum()) # 如果存在重复的数据,则将其删除 daast = datt.drop\_duplicates(keep='first').reset\_index(drop=True) # 数据集中的样本数 N = det.shape\[0\] 。
事实证明,数据集没有任何 Null 值或重复项。
相关性
让我们计算和可视化特征之间的相关性

图 1 – 相关性
建模
构建模型
为了稍后执行交叉验证并评估模型的性能,让我们将数据集拆分为训练集和测试集。

# 建立训练和测试集 dex\_train, index\_test = train\_test\_split( range(N), test_size = 0.35) # 创建X、T和E输入 X\_tain, Xtst = daa\_ain\[ftures\], datts\[fees\] T\_tin, T\_tst = daa\_rain\[ie\_olumn\], dta\_est\[tme\_olumn\] E\_tain, \_tst = daa\_tain\[vent\_cumn\], dattet\[evet_lumn\]
注意:超参数的选择是使用网格搜索选择获得的。
# 拟合模型 cf.fit(\_trai, T\_tra, \_tain, ax\_eatrs='sqrt',
变量重要性
建立生存森林模型后,我们可以计算特征重要性:
随时关注您喜欢的主题
# 计算变量的重要性 sf.vaialeipotanetle.head(5)
这是最重要的功能中的前 5 个。
由于功能的重要性,我们可以更好地了解是什么推动了保留或流失。在这里,会计和薪资管理产品、满意度调查得分以及与客户支持通话的时间都发挥着重要作用。
注意:重要性是扰动和未扰动错误率之间的预测误差差异
交叉验证
为了评估模型性能,我们之前将原始数据集拆分为训练集和测试集,以便我们现在可以在测试集上计算其性能指标:
C-index
这C-index代表模型辨别能力的全局评估: 这是模型根据个体风险评分正确提供生存时间可靠排名的能力。
一般来说,当 C-index 接近 1 时,模型具有近乎完美的判别力;但如果接近0.5,则没有区分低风险和高风险对象的能力。
Brier score
这Brier score测量给定时间状态和估计概率之间的平均差异。 因此,分数越低(_通常低于 0.25_),预测性能就越好。为了评估跨多个时间点的整体误差测量,通常还计算综合 Brier 分数 (IBS)。
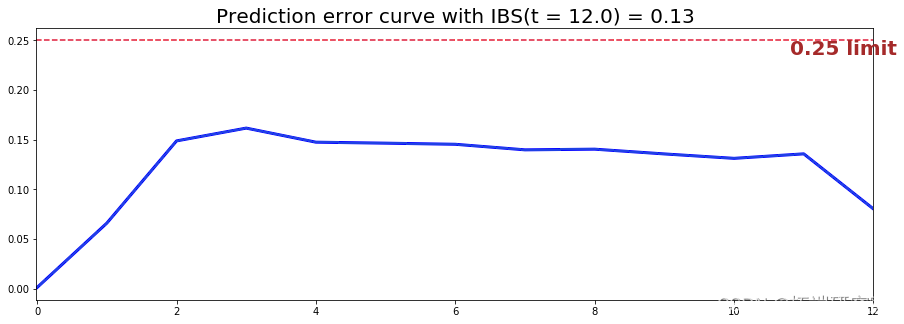
图 2 – 条件生存森林 – Brier 分数和预测误差曲线
总体预测
IBS 在整个模型时间轴上等于 0.13。这表明该模型将具有良好的预测能力。
预测
既然我们已经建立了一个似乎可以提供出色性能的模型,让我们比较每个时间 t 停止与 SaaS 公司开展业务的实际客户数量和预测客户数量的时间序列。
comroal(cf, X\_tst, T\_tst, E_tst
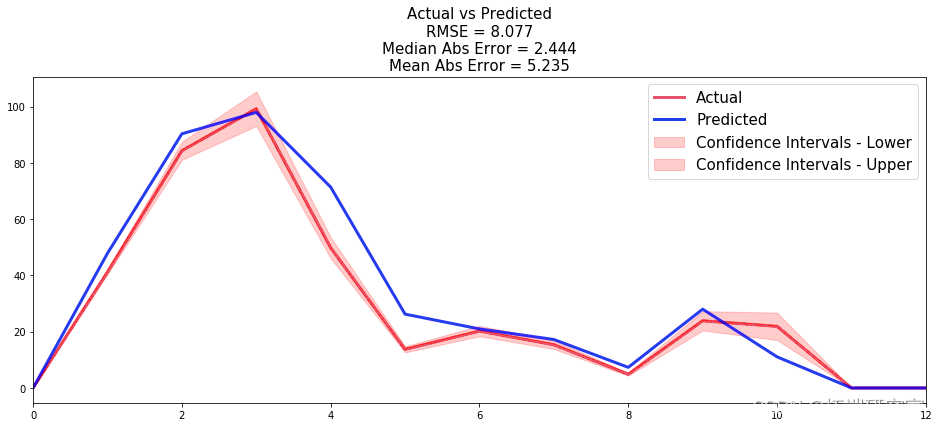
图 3 – 条件生存森林 – 流失的客户数量
该模型总体上提供了非常好的结果,因为在整个 12 个月的窗口中,它只会产生约 5 个客户的平均绝对误差。
个人预测
让我们计算在 所有时间 t 中保留客户的概率。
首先,我们可以根据风险评分分布构建风险组。
cree\_rskups(oel=csf, X=X\_test
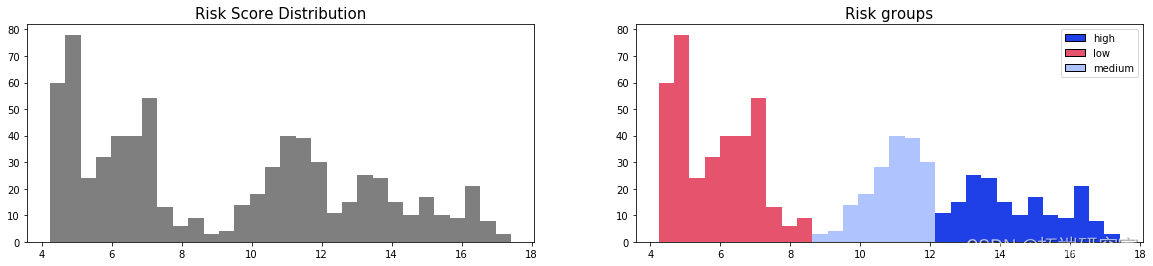
图 4 – 条件生存森林 – 风险组
在这里,可以区分 3 个主要群体, 低_风险、 _中_风险 和 _高 风险群体。由于 C 指数较高,模型将能够对每组随机单元的生存时间进行适当的排序。
让我们随机选择每组中的单个单元,并比较它们在所有时间 t 中保留客户的概率。为了证明我们的观点,我们将特意选择经历过事件的单位来可视化事件的实际时间。
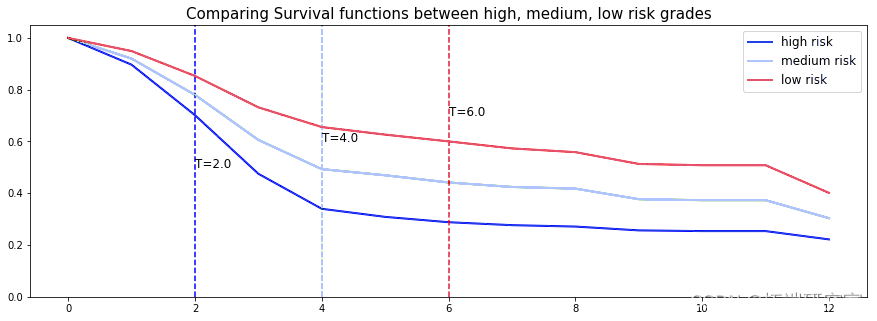
图 5 – 条件生存森林 – 预测个人保留客户的概率
在这里,我们可以看到该模型设法提供了对事件时间的出色预测。
结论
我们现在可以保存我们的模型,以便将其投入生产并为未来的客户评分。
总之,我们可以看到,可以预测客户在不同时间点停止与公司开展业务的时间。该模型将帮助公司在留住客户方面更加积极主动;并更好地了解导致客户流失的原因。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载



