
在这篇文章中,我用R语言和python检测社交网络中的社区。
建立网络:
Kaggle数据集中包含了110个.egonet文件,每一个文件都代表了一个匿名Facebook用户的社交关系网络,为我们揭示了这110个用户与其朋友们之间错综复杂的关系网。每一个.egonet文件都如同一幅细致的画卷,描绘出该用户在Facebook上的社交圈层,以及他们与朋友们之间的连接纽带。
可下载资源
作者

Kaggle数据 在110个.egonet文件中(对应于110个匿名Facebook用户),每个文件都包含他的朋友的网络。
模块度定义其实很好理解,我们可以根据一个网络的空模型去进行理解。网络的空模型可以理解为只有节点的而没有连边,这时候一个节点可以和图中的任意其他节点相连,并且节点和相连的概率可以通过计算得到。随机选择一个节点与节点相连的概率为,随机选择一个节点与节点相连的概率为,那么节点和节点相连的概率为,边数的期望值。所以模块度其实就是指一个网络在某种社区划分下与随机网络的差异,因为随机网络并不具有社区结构,对应的差异越大说明该社区划分越好。
Newman提出的模块度具有两方面的意义:
(1)模块度的提出成为了社区检测评价一种常用指标,它是度量网络社区划分优劣的量化指标;
(2)模块度的提出极大地促进了各种优化算法应用于社区检测领域的发展。在模块度的基础之上,许多优化算法以模块度为优化的目标方程进行优化,从而使得目标函数达到最大时得到不错的社区划分结果。
当然,模块度的概念不是绝对合理的,它也有弊端,比如分辨率限制问题等,后期国内学者在模块度的基础上提出了模块度密度的概念,可以很好的解决模块度的弊端,这里就不详细介绍了。
常用的社区检测方法主要有如下几种:
(1)基于图分割的方法,如Kernighan-Lin算法,谱平分法等;
(2)基于层次聚类的方法,如GN算法、Newman快速算法等;
(3)基于模块度优化的方法,如贪婪算法、模拟退火算法、Memetic算法、PSO算法、进化多目标优化算法等。
让我们关注文件0.egonet,其中包含有关用户0的网络的所有信息。文件的每一行都是该行中直接属于网络一部分的第一个用户的朋友的列表。
1: 146 189 229 201 204 ...
2: 146 191 229 201 204 ...
3: 185 80 61 188 22 222 ...
4: 72 61 187 163 177 138 ...在下面,我附加了访问每个egonet文件的Python代码,并构建了Networkx构造函数的节点和边的列表。 构建图后,将计算其邻接矩阵并将其保存在csv文件中。
import networkx as nx
from os import listdir
from os.path import isfile, join
from sklearn.cluster import KMeans
def load_egonet_files(path):
"""
给定.egonet文件的路径,则返回包含所有文件的列表。
"""
onlyfiles = [fyle for fyle in listdir(path) if fyle.endswith('.egonet')]
return onlyfiles
提供的代码的结果是110个CSV文件,其中包含每个自我网络图的邻接矩阵。
检测社区
首先,让我们绘制一个图,看看它在社区聚类检测之前的样子。在R代码下方,从CSV文件加载数据,构建网络(我们使用0.egonet)并进行绘制。
#从csv文件读取图形
dat = read.csv('graph-0.csv', header=TRUE, row.names=1, check.names=FALSE)
m = as.matrix(dat)
# 从邻接矩阵构建图
g = graph.adjacency(m,mode="undirected",weighted=NULL)
# 绘制图形

R 提供了几种强大的社区检测算法。
模块化本质上是属于给定组的边缘的分数减去如果边缘随机分布的期望分数。所以越高越好。
在这里,您可以在用户0网络上找到结果。
> modularity(wc)
[1] 0.4629543
> modularity(wc)
[1] 0.4463902
> modularity(wc)
[1] 0.4330911
> modularity(wc)
[1] 0.4649535
> modularity(wc)
[1] 0.4511259
> modularity(wc)
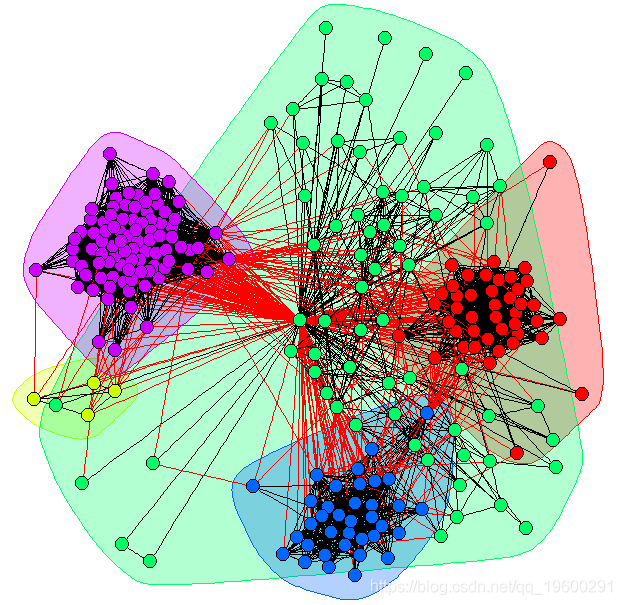
[1] 0.4314803spinglass.community算法是最好的算法,其模块化为0.4649。事实证明,可以发现小型自我社会网络中的社区 。
在下面,您也可以在R中发现检测到的群集的良好可视化效果。

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

