
Groupon是一个优惠券推荐服务,您可以免费注册Groupon。
并且Groupon每天都会向您发送包含该地区当天交易的电子邮件。
可下载资源
数据
这些数据是从Groupon网站的纽约市区域获得的。网站的布局分为所有不同groupon的专辑搜索,然后是每个特定groupon的深度页面。网站外观如下所示:
scrapy框架?
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
1、引擎(EGINE) 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。2、调度器(SCHEDULER)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址3、下载器(DOWLOADER)用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的4、爬虫(SPIDERS)SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求5、项目管道(ITEM PIPLINES)在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,6、爬虫中间件(Spider Middlewares)位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
scrapy框架+selenium的使用
1 使用情景:
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值
2 使用流程
1 重写爬虫文件的__init__()构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次).
2 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象,该方法是在爬虫结束时被调用.
3 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据.
4 在settings配置文件中开启下载中间件
两个页面的布局都不是动态的,所以建立了一个自定义scrapy ,以便快速浏览所有的页面并检索要分析的信息。然而,评论,重要的信息,通过JavaScript呈现和加载 。Selenium脚本使用从scrapy获取的groupons的URL,实质上模仿了人类点击用户注释部分中的“next”按钮。
for url in url_list.url[0:50]:
try:
driver.get(url)
time.sleep(2)
#关闭出现的任何弹出窗口
# if(driver.switch_to_alert()):
try:
close = driver.find_element_by_xpath('//a[@id="nothx"]')
close.click()
except:
pass
time.sleep(1)
try:
link = 视频
Python的天气数据爬虫实时抓取采集和可视化展示
视频
文本挖掘:主题模型(LDA)及R语言实现分析游记数据
driver.find_element_by_xpath('//div[@id="all-tips-link"]')
driver.execute_script("arguments[0].click();", link)
time.sleep(2)
except:
next
i = 1
print(url)
while True:
try:
time.sleep(2)
print("Scraping Page: " + str(i))
reviews = driver.find_elements_by_xpath('//div[@class="tip-item classic-tip"]')
next_bt = driver.find_element_by_link_text('Next')
for review in reviews[3:]:
review_dict = {}
content = review.find_element_by_xpath('.//div[@class="twelve columns tip-text ugc-ellipsisable-tip ellipsis"]').text
author = review.find_element_by_xpath('.//div[@class="user-text"]/span[@class="tips-reviewer-name"]').text
date = review.find_element_by_xpath('.//div[@class="user-text"]/span[@class="reviewer-reviewed-date"]').text
review_dict['author'] = author
review_dict['date'] = date
review_dict['content'] = content
review_dict['url'] = url
writer.writerow(review_dict.values())
i += 1
next_bt.click()
except:
break
except:
next
csv_file.close()
driver.close()大约有89,000个用户评论。从每个评论中检索的数据如下所示。
print(all_groupon_reviews[all_groupon_reviews.content.apply(lambda x: isinstance(x, float))])
indx = [10096]
all_groupon_reviews.content.iloc[indx]
author date content \
10096 Patricia D. 2017-02-15 NaN
15846 Pat H. 2016-09-24 NaN
19595 Tova F. 2012-12-20 NaN
40328 Phyllis H. 2015-06-28 NaN
80140 Andre A. 2013-03-26 NaN
url year month day
10096 https://www.groupon.com/deals/statler-grill-9 2017 2 15
15846 https://www.groupon.com/deals/impark-3 2016 9 24
19595 https://www.groupon.com/deals/hair-bar-nyc-1 2012 12 20
40328 https://www.groupon.com/deals/kumo-sushi-1 2015 6 28
80140 https://www.groupon.com/deals/woodburybus-com 2013 3 26 Groupon标题
分类信息
交易功能位置
总评分数网址
作者日期
评论网址
大约有89,000个用户评论。从每个评论中检索的数据如下所示。
print(all_groupon_reviews[all_groupon_reviews.content.apply(lambda x: isinstance(x, float))])
indx = [10096]
all_groupon_reviews.content.iloc[indx]
author date content \
10096 Patricia D. 2017-02-15 NaN
15846 Pat H. 2016-09-24 NaN
19595 Tova F. 2012-12-20 NaN
40328 Phyllis H. 2015-06-28 NaN
80140 Andre A. 2013-03-26 NaN
url year month day
10096 https://www.groupon.com/deals/statler-grill-9 2017 2 15
15846 https://www.groupon.com/deals/impark-3 2016 9 24
19595 https://www.groupon.com/deals/hair-bar-nyc-1 2012 12 20
40328 https://www.groupon.com/deals/kumo-sushi-1 2015 6 28
80140 https://www.groupon.com/deals/woodburybus-com 2013 3 26 探索性数据分析
一个有趣的发现是在过去的几年里,群体的使用已经大大增加了。我们通过检查评论提供的日期来发现这一点。看下面的图像,其中x轴表示月/年和y轴,表示计数,这个结论变得明显。最后的小幅下滑是由于当时的一些小组可能是季节性的。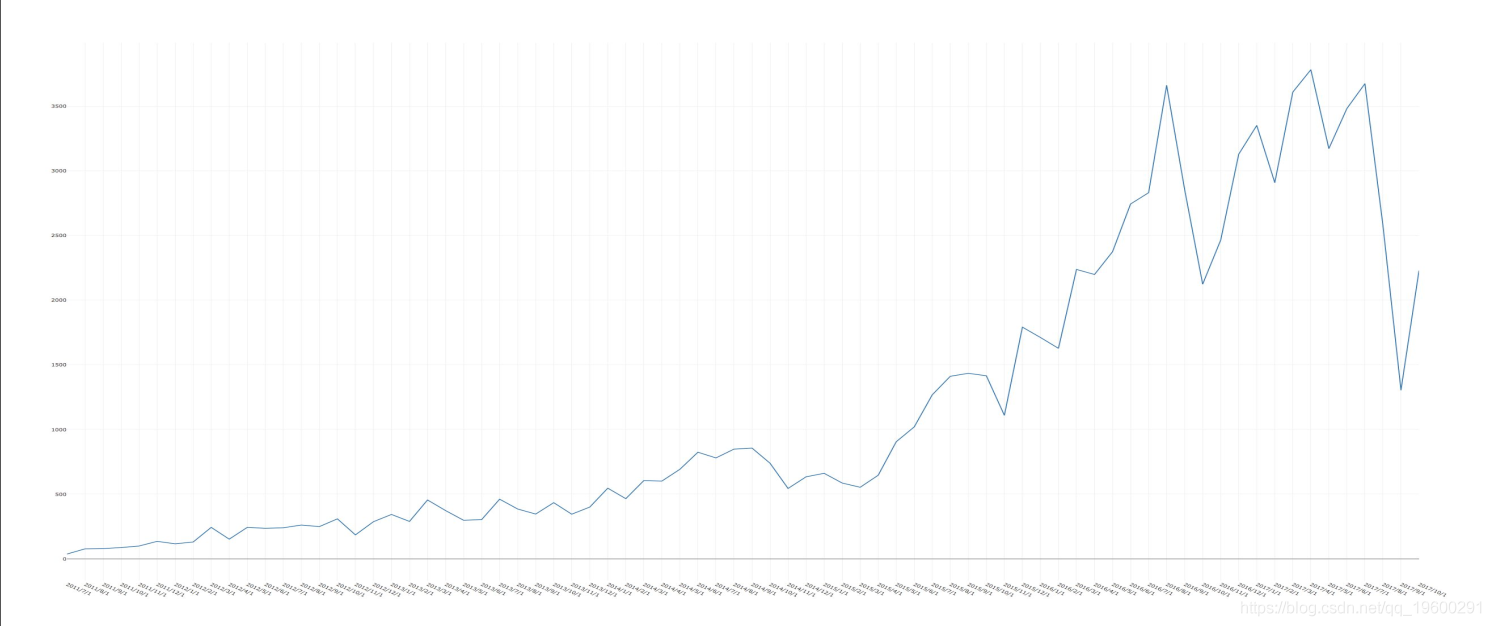
一个有趣的发现是在过去的几年里,群体的使用已经大大增加了。我们通过检查评论提供的日期来发现这一点。看下面的图像,其中x轴表示月/年和y轴,表示计数。最后的小幅下滑是由于当时的一些小组可能是季节性的。
pie_chart_df = Groupons.groupby('categories').agg('count')
plt.rcParams['figure.figsize'] = (8,8)
sizes = list(pie_chart_df.mini_info)
labels = pie_chart_df.index
plt.pie(sizes, shadow=True, labels = labels, autopct='%1.1f%%', startangle=140)
# plt.legend(labels, loc="best")
plt.axis('equal')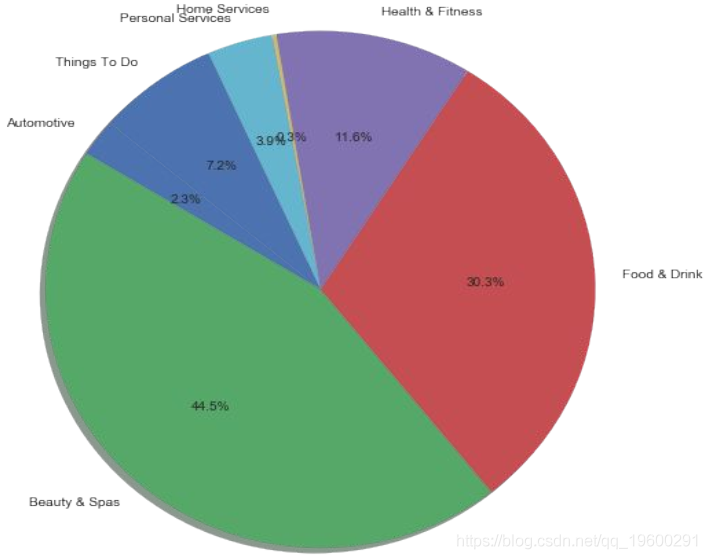
最后,由于大部分数据是通过文本:价格(原价),导出了一个正则表达式来解析价格信息,以及它们提供的交易数量。该信息显示在以下条形图中:
objects = list(offer_counts.keys())
y = list(offer_counts.values())
tst = np.arange(len(y))
plt.bar(tst,y, align = 'center')
plt.xticks(tst, objects)
plt.ylabel('Total Number of Groupons')
plt.xlabel('Different Discounts Offers')
plt.show()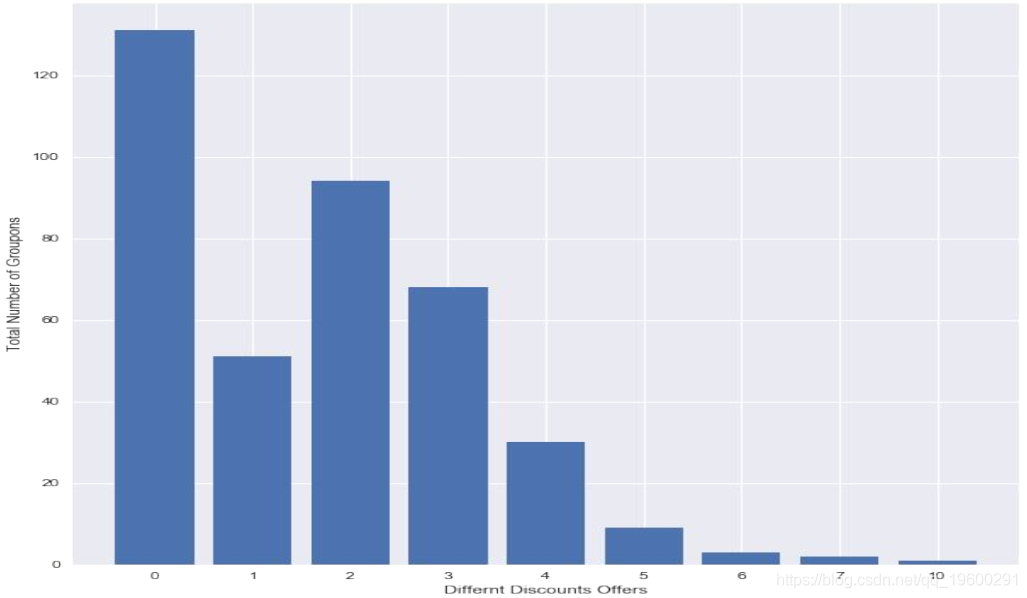
plt.ylabel('Number of Offerings')
plt.xticks(ind, ('Auto', 'Beauty', 'Food', 'Health', 'Home', 'Personal', 'Things'))
plt.xlabel('Category of Groupon')
plt.legend((p0[0], p1[0], p2[0], p3[0], p4[0], p5[0], p6[0], p7[0], p10[0]), ('0', '1', '2', '3', '4', '5', '6', '7', '10'))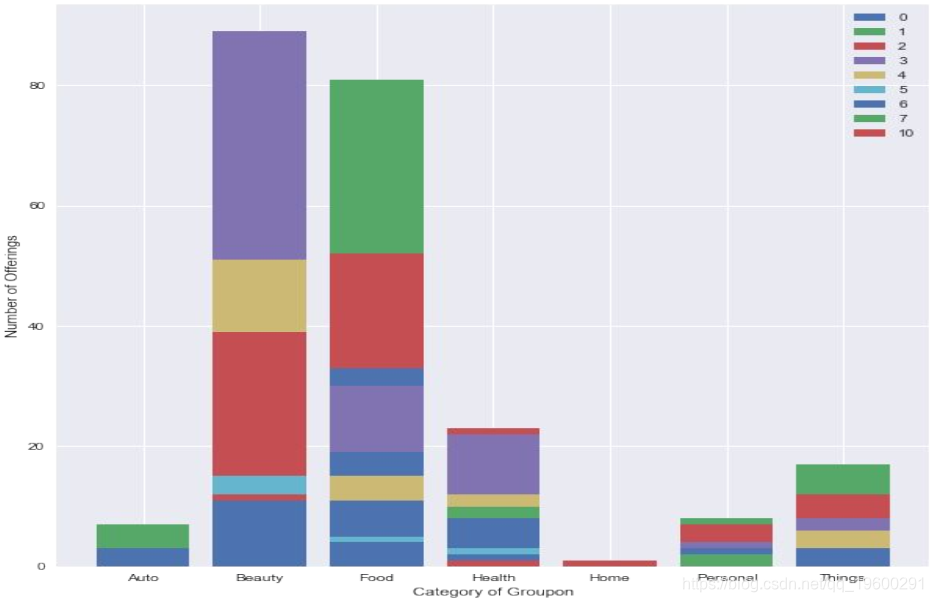
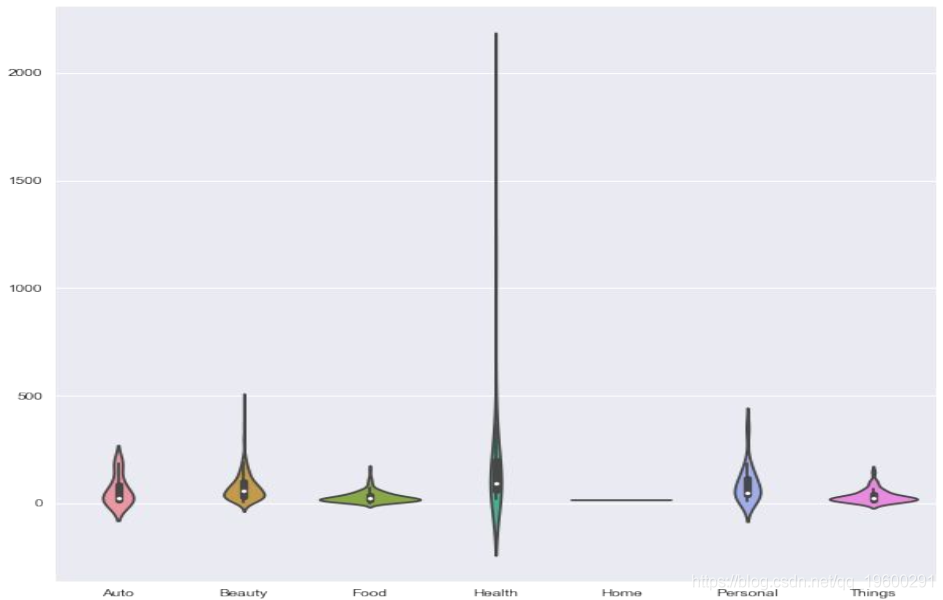
sns.violinplot(data = savings_dataframe)
最后,利用用户评论数据生成一个文字云:
plt.rcParams['figure.figsize'] = (20,20)
wordcloud = WordCloud(width=4000, height=2000, max_words=150, background_color='white').generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")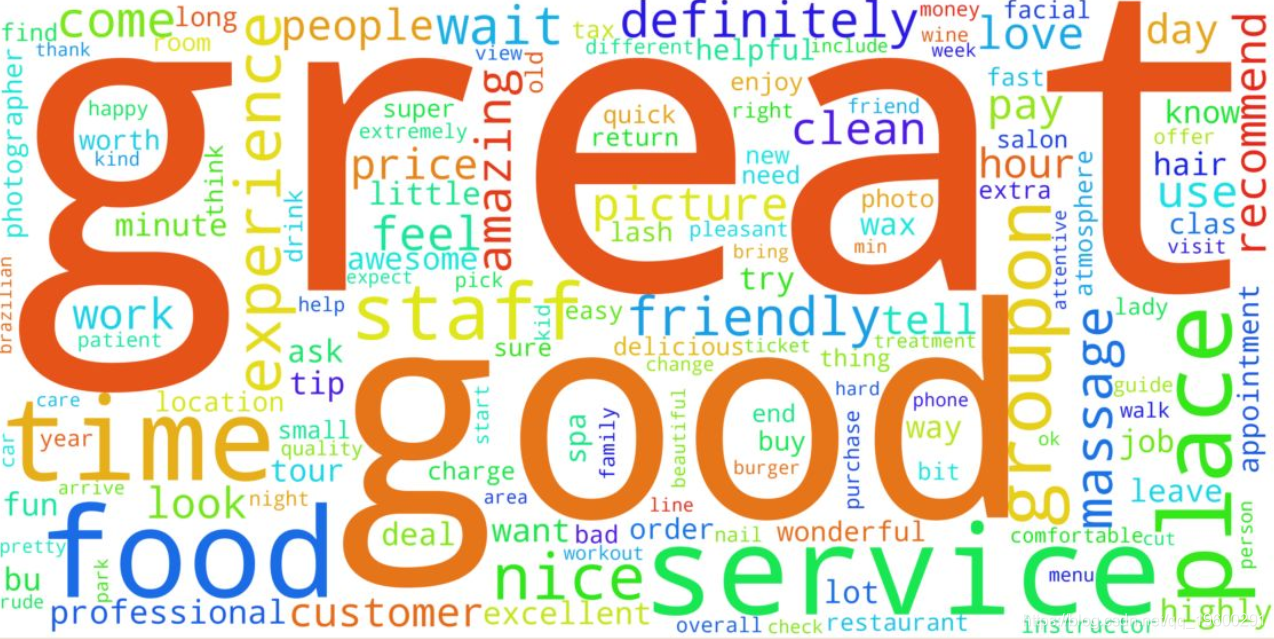
主题建模
为了进行主题建模,使用的两个最重要的软件包是gensim和spacy。创建一个语料库的第一步是删除所有停用词,如“,”等。最后创造trigrams。
选择的模型是Latent Dirichlet Allocation,因为它能够区分来自不同文档的主题,并且存在一个可以清晰有效地将结果可视化的包。由于该方法是无监督的,因此必须事先选择主题数量,在模型的25次连续迭代中最优数目为3。结果如下:
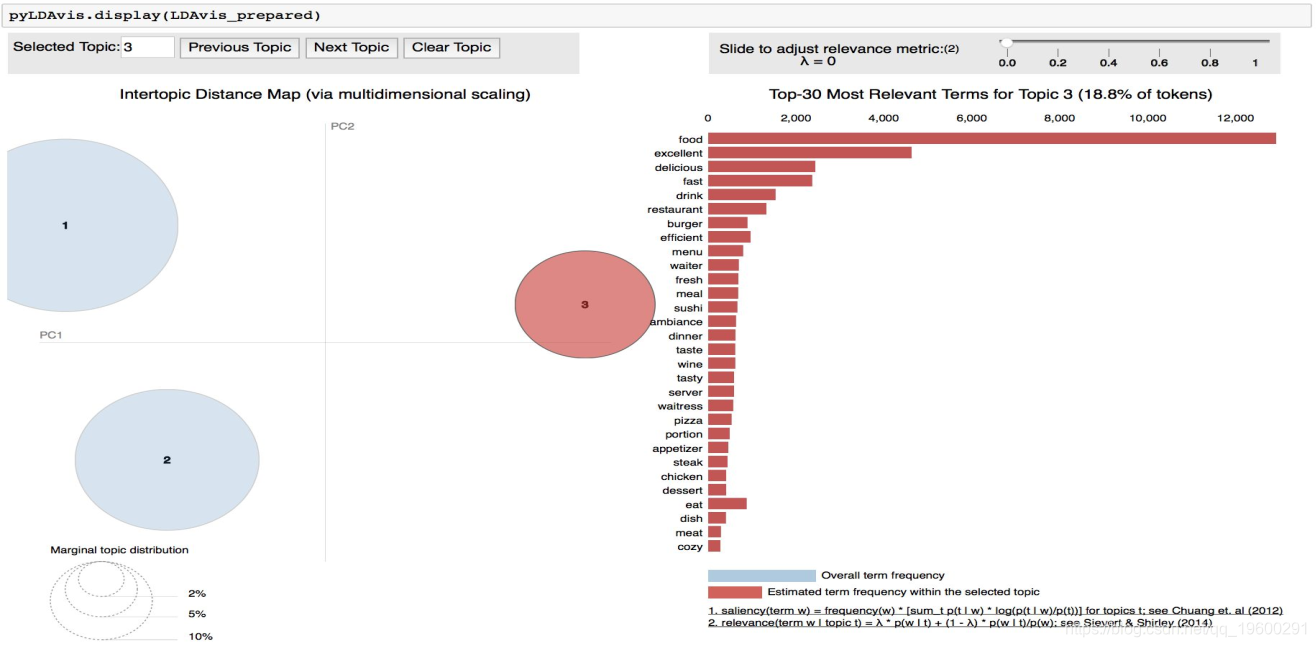
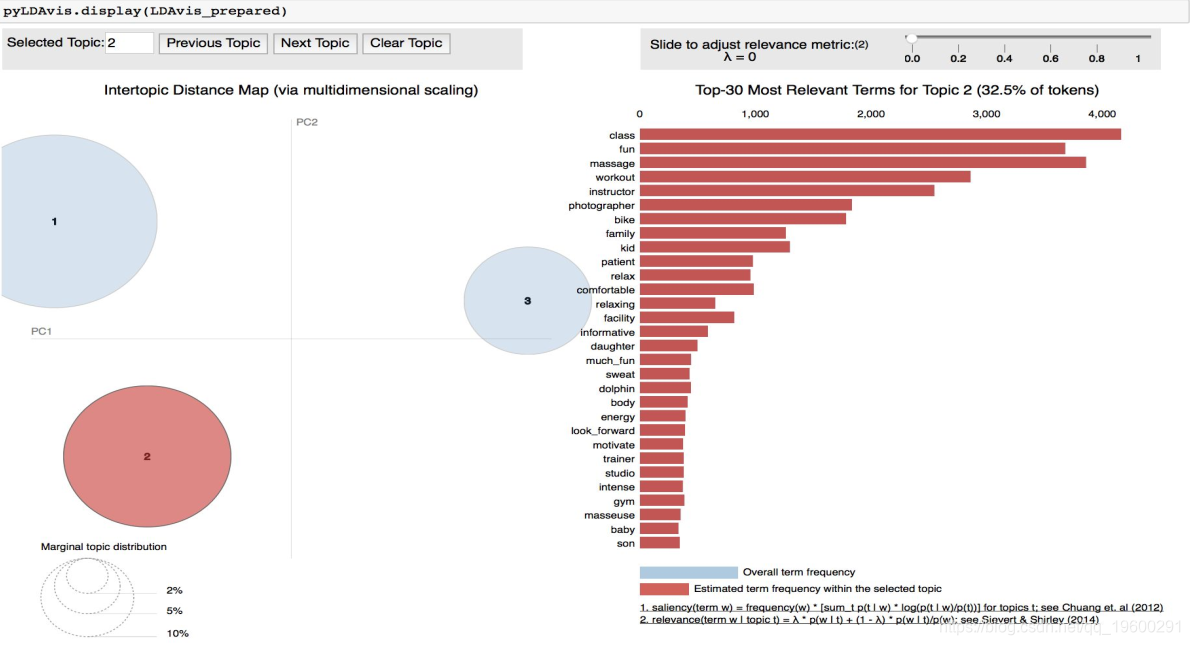
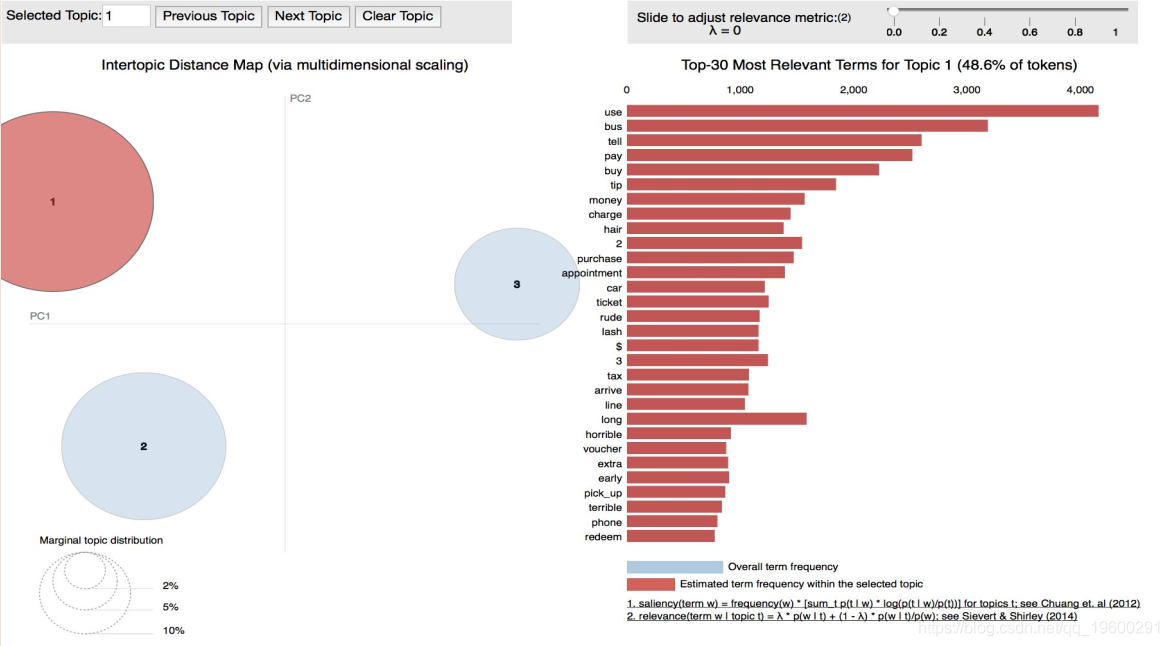
上面的可视化是将主题投影到两个组件上,其中相似的主题会更接近,而不相似的主题会更远。右边的单词是组成每个主题的单词,lambda参数控制单词的排他性。0的lambda表示每个主题周围的最排斥的单词,而1的lambda表示每个主题周围的最频繁的单词。
第一个话题代表服务的质量和接待。第二个话题有描述锻炼和身体活动的词语。最后,第三个话题有属于食品类的词语。
结论
主题建模是无监督学习的一种形式,这个项目的范围是简要地检查在基础词语背后发现模式的功能。虽然我们认为我们对某些产品/服务的评论是独一无二的,但是这个模型清楚地表明,实际上,某些词汇在整个人群中被使用。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察
专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 【视频】文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化
【视频】文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化



1 comment on “scrapy爬虫框架和selenium的使用:对优惠券推荐网站数据LDA文本挖掘”