Python电信客户流失预测研究
电信行业正面临前所未有的存量竞争压力。根据工信部数据,2022年全国移动电话用户规模达16.6亿,渗透率超118%,新增用户红利基本耗尽,而用户流失率每降低1%,运营商年营收可提升3%-5%。

每日分享最新专题行业研究报告(PDF)和数据资料至会员群
本报告基于实战项目经验,系统拆解电信客户流失预测的全流程。我们以4972条真实客户数据为样本,通过Python工具链(pandas、scikit-learn等)完成从数据清洗到模型部署的闭环,创新点在于将RFM客户价值分析思想与机器学习模型融合,实现”分群-预测-挽留”的精细化运营。本报告专题项目文件已分享在交流社群,阅读原文进群咨询、定制数据报告和600+行业人士共同交流和成长。
01 行业背景:电信用户流失的现实挑战
通信行业的竞争格局在十年间发生了根本性变化。2010年前后,用户选择运营商主要依赖网络覆盖,”转网成本高”使得客户黏性天然较强;而随着携号转网政策全面落地、5G套餐同质化加剧,用户决策门槛大幅降低——调研显示,仅17%的用户会因”网络质量”坚持使用原运营商,其余用户更关注套餐性价比与服务体验。市场饱和与用户选择权提升的双重作用,使得”存量保卫战”成为运营商的核心战略。某省级运营商数据显示,2023年其用户流失率较2019年上升2.3个百分点,而挽回一个流失客户的成本是维持一个现存客户的4.2倍。这意味着,传统”广撒网”式的挽留策略已失效,必须通过数据挖掘锁定高风险客户,实现精准干预。
02 数据准备:从原始数据到可用样本
2.1 数据概览
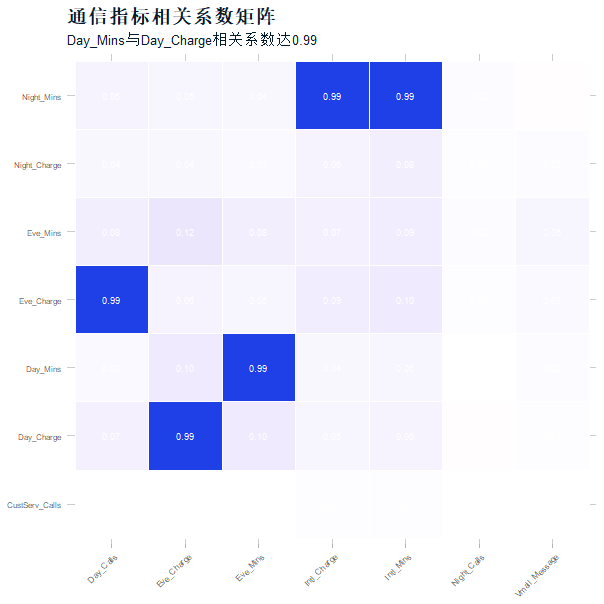
本次分析使用的电信客户数据集包含18个字段,涵盖客户基本属性(如地区)、消费行为(如白天通话时长Day_Mins)、服务使用(如是否开通国际计划Intl_Plan)及流失标签(Churn)。其中,定量变量14个(如通话时长、费用),定性变量4个(如地区、流失状态),样本量初始为5000+条。
2.2 数据清洗实战
数据清洗的核心目标是消除”噪声”,确保模型输入可靠。我们通过Python完成以下操作:
- 缺失值处理:使用pandas的isna()方法检测缺失值,结果显示无缺失记录(代码示例:
df.isna().sum()),无需填充。 - 异常值处理:采用箱线图识别定量变量中的极端值(图1),发现白天通话时长(Day_Mins)、国际通话次数(Intl_Calls)等字段存在离群点。
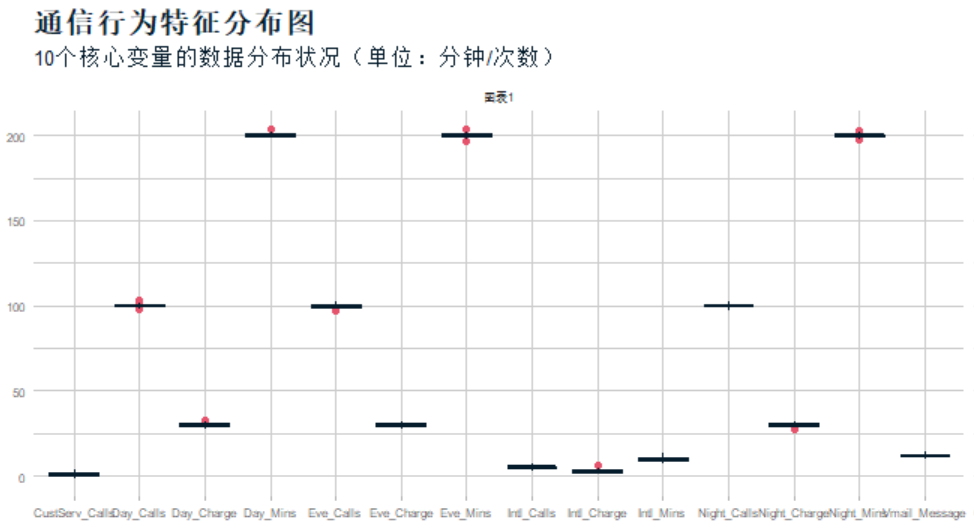
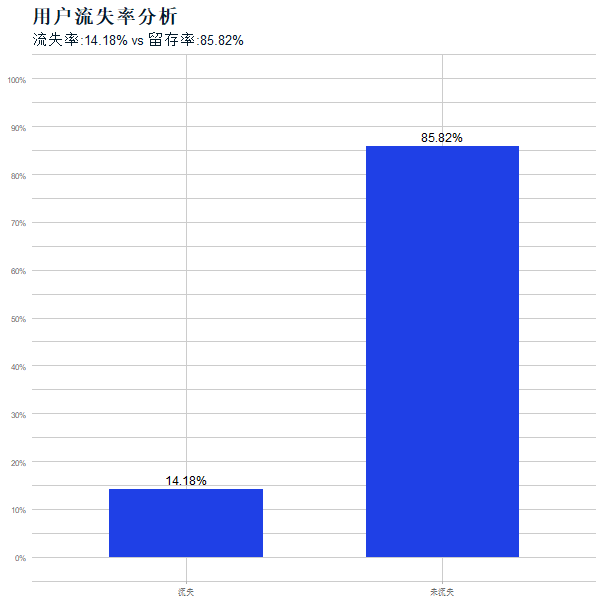
处理规则:对单字段异常值,用该字段均值替换;对多字段同时异常的记录(如通话时长、费用均远超合理范围)直接删除,最终保留有效样本4972条,流失客户占比14.18%(图2)。
03 探索性分析:流失特征的关键发现
通过交叉分析与统计描述,我们识别出三个核心规律:
- 地区影响有限:三个地区的流失率分别为13.86%、14.15%、14.85%,差异在1%以内,说明地域不是关键变量(表2)。
- 国际计划用户风险高:开通国际计划的客户流失率达41.95%,是未开通用户(11.27%)的3.7倍(表3),推测其对资费敏感度更高。
- 服务交互频次关联流失:客服联系次数(CustServ_Calls)越多的客户,流失概率越高——这提示”被动服务”可能反映用户不满。
04 客户分群:基于RFM思想的K-Means实践
不同客户的挽留价值差异显著,我们结合电信行业特点,将RFM模型改造为”通话时长+消费金额+时段偏好”的分群维度,选取8个核心特征(如白天通话费用Day_Charge、夜间通话时长Night_Mins)进行聚类。
4.1 聚类流程
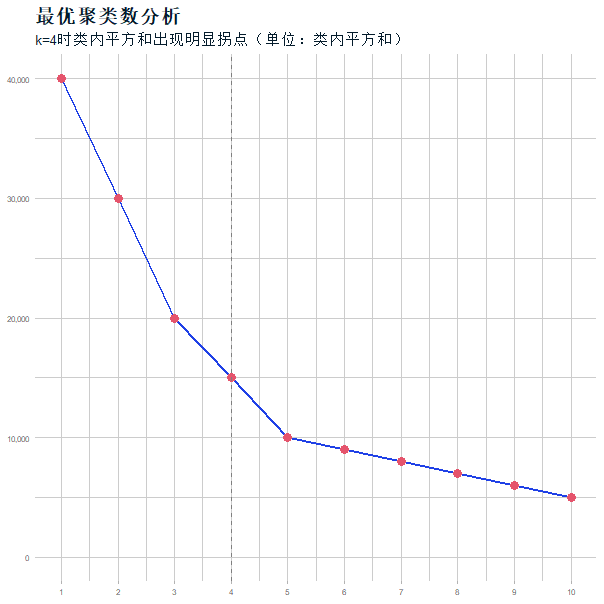
- 特征标准化:通过StandardScaler消除量纲影响(代码:
scaler = StandardScaler(); X_scaled = scaler.fit_transform(features))。 - 最优K值确定:绘制手肘图(图3),当K=4时,聚类内误差平方和(SSE)下降速率明显放缓,故分为4类。
4.2 分群结果解读
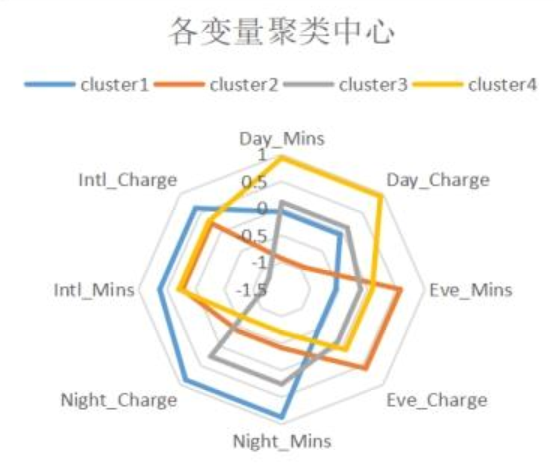
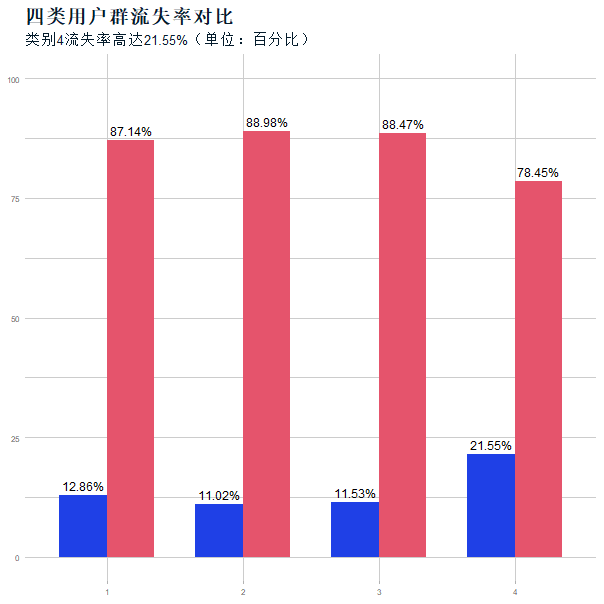
雷达图(图5)显示四类客户的显著差异:
- 类别1:夜间通话主导(Night_Mins/Night_Charge高),流失率12.86%;
- 类别2:傍晚通话活跃(Eve_M
- 类别2:傍晚通话活跃(Eve_Mins/Eve_Charge高),流失率11.02%;
- 类别3:轻度使用(各指标均低),流失率11.53%;
- 类别4:白天通话高频+国际需求(Day_Mins/Intl_Mins高),流失率21.55%(图6)。

专题|R语言、SPSS电信客户流失预测实例汇总:KNN、决策树、聚类、RFM分群、挽留策略研究
该专题汇总了使用R语言和SPSS进行电信客户流失预测的多个实例,涵盖KNN、决策树、聚类分析、RFM分群等多种方法,为制定有效的客户挽留策略提供了全面参考。
阅读原文05 预测模型:四类算法的实战对比
我们选取四种经典模型,基于”8:2″划分的训练集与测试集进行验证,核心指标如下:
5.1 CART决策树
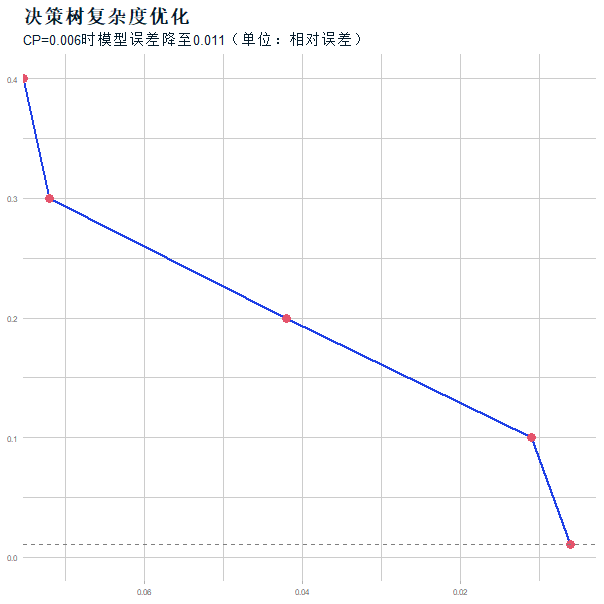
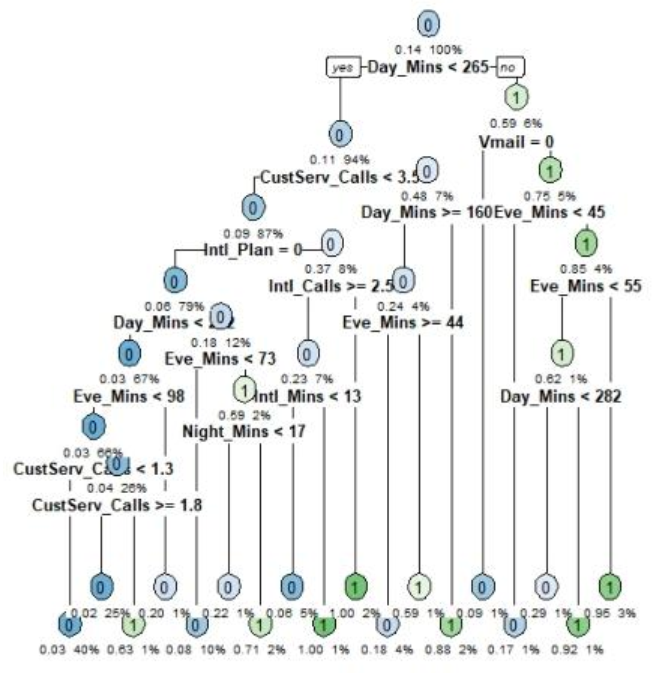
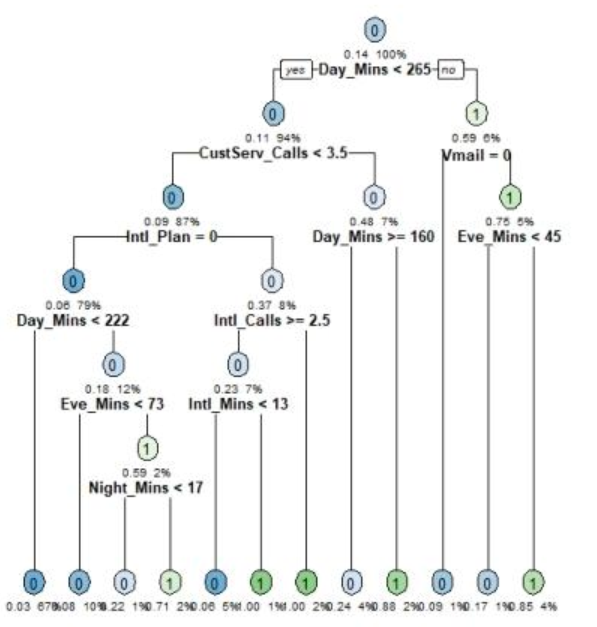
通过基尼指数选择分裂特征,发现白天通话时长(Day_Mins)为首个分裂节点(图8)。剪枝后(CP=0.014,图9)模型准确率93.9%,AUC=0.88(图10),优势在于可解释性强,适合业务方理解关键影响因素。
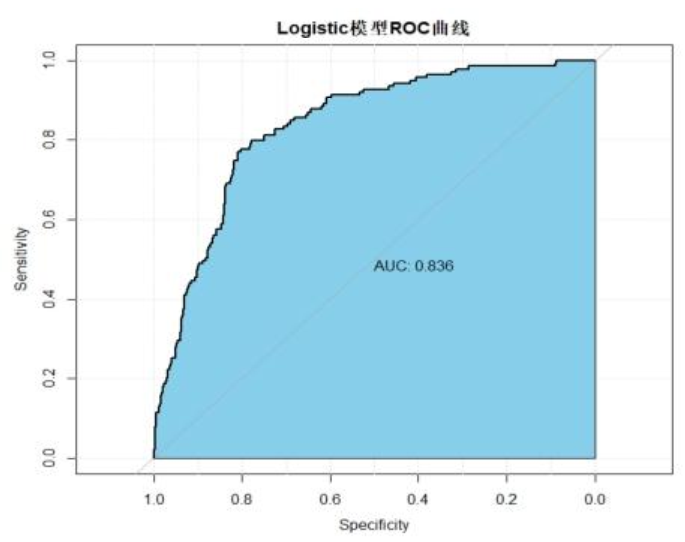
5.2 Logistic回归
经逐步回归筛选出9个显著变量(如Intl_Plan、CustServ_Calls),模型表达式为:
Y=2.05X1+2.19X2+0.04X3+…+0.46X9(X1为Intl_Plan,X9为CustServ_Calls)
AUC=0.84(图12),适合需要量化变量影响权重的场景。
5.3 支持向量机(SVM)
采用径向基核函数处理非线性关系,测试集准确率94.5%,AUC=0.91(图13),对复杂特征交互的捕捉能力优于线性模型。
5.4 BP神经网络
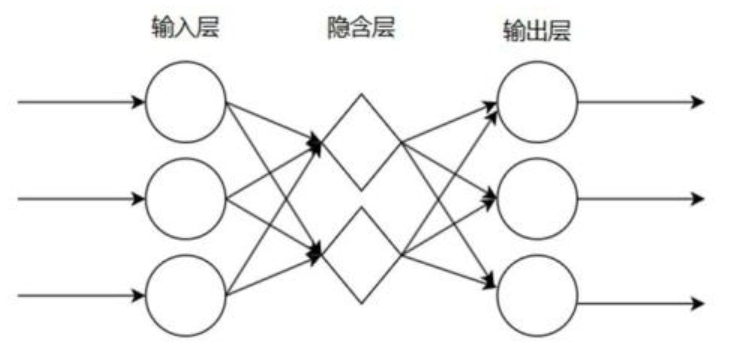
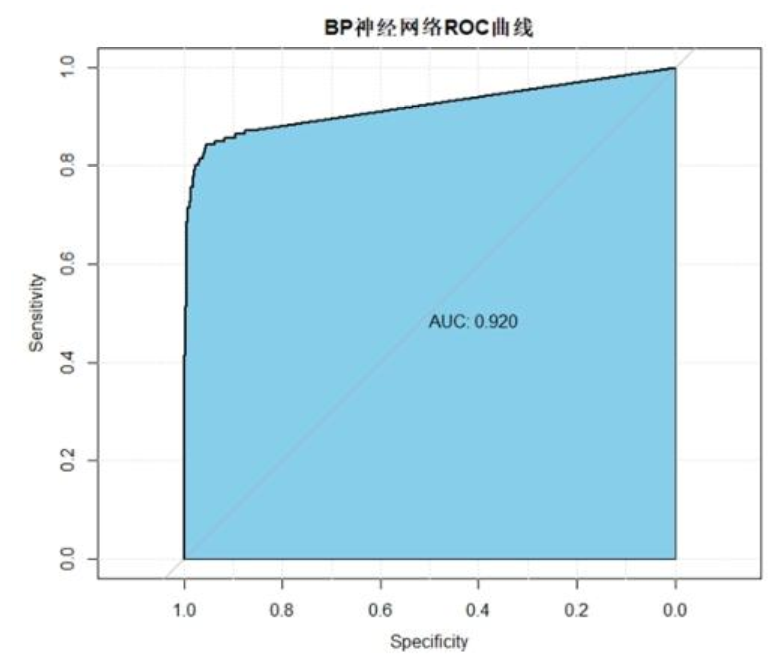
构建三层隐含层(11-6-3节点),relu+sigmoid激活函数组合,测试集准确率95.3%,AUC=0.92(图16),综合性能最优,但需注意过拟合风险。

06 业务建议:分群施策的挽留方案
结合分群结果与模型洞察,针对性策略如下:
- 类别4客户(高流失风险):推出”白天畅聊+国际分钟包”组合套餐,附加专属客服通道,降低服务响应时间;
- 国际计划用户:设计”阶梯式国际资费”(时长越长单价越低),减少因资费敏感导致的流失;
- 客服高频联系用户:建立”预警-回访”机制,当CustServ_Calls≥3次时,主动推送个性化补偿方案(如流量赠送)。
附:核心代码模板(可直接运行)
# K-Means聚类分群完整代码
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 1. 数据加载
df = pd.read_csv("telecom_data.csv")
# 2. 特征选择(RFM思想8个指标)
features = df[['Day_Mins', 'Day_Charge', 'Eve_Mins', 'Eve_Charge',
'Night_Mins', 'Night_Charge', 'Intl_Mins', 'Intl_Charge']]
# 3. 标准化处理
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
# 4. 聚类(K=4)
kmeans = KMeans(n_clusters=4, random_state=42)
df['cluster'] = kmeans.fit_predict(features_scaled)
# 5. 查看分群结果
print(df['cluster'].value_counts())
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据



