Python对2018-2024年全国多省份高考数据分析:录取概率预测可视化模型应用与位次关联实践
高考,这场牵动千万家庭的考试,从1977年恢复至今,已经走过了近半个世纪。最初,它只是一张试卷定乾坤,数据记录靠手写;后来,随着计算机普及,分数统计开始电子化,但各省数据分散在不同平台,格式五花八门——有的存在PDF里,有的藏在网页表格中,考生想查个历年分数对比,得翻遍十几个网站。

高考数据专题项目文件已分享在交流社群,阅读原文进群和500+行业人士共同交流和成长。
我和团队在去年的一个咨询项目中就遇到过这样的事:一位河南考生家长,为了给孩子选志愿,手动抄了五个省份三年的录取数据,结果因为各省满分不同(海南900分、上海660分),算到最后全乱了。这让我们意识到:高考数据的价值,藏在碎片化的表象下,需要系统化的梳理和分析才能释放。 于是,我们从掌上高考、阳光高考等平台收集了2018-2024年29个省份的一分一段表、3000多所高校的录取数据,用Python工具一点点清洗、标准化,再通过统计分析找规律,最后建了个录取概率预测模型。现在,这些成果整理成了这份报告,希望能帮学生和家长少走弯路。
数据预处理:给高考数据“做体检”
从“乱糟糟”到“有条理”
收集来的数据就像刚买回来的菜,带着泥土和杂质。我们先把这些数据(有一分一段表、考生人数、高校录取分等)存成CSV格式,用Python的Pandas库打开,看看里面有多少行多少列,有没有明显的错误。比如打开考生人数表时,我们发现有的年份写的是“2018年”,有的写的是“18年”,得先统一成“2018”这种格式,方便后续计算。
给数据“挑毛病”
数据里最常见的问题是“缺胳膊少腿”(缺失值)和“双胞胎”(重复值)。我们用代码检查了每张表:
# 检查专业录取表的缺失值
major_admission = pd.read_csv('admission_score.csv')
# 查看各字段缺失情况
print(major_admission.info())
# 统计缺失值数量
print(major_admission.isnull().sum())
# 处理专业名称缺失的行(直接删除)
major_admission_clean = major_admission.dropna(subset=['专业名称'])
# 去除重复记录
major_admission_clean = major_admission_clean.drop_duplicates()
这段代码的作用是,先读取专业录取数据,查看哪些字段有缺失,发现“专业名称”缺失的话,这些记录就没用了,直接删掉;对于重复的记录(可能是爬数据时多抄了一遍),也一并删掉。像考生人数表中,有些年份的增长率没写,查了下都是第一年的数据,本来就没法算增长率,那就不用管了。
给各省分数“统一尺子”
最麻烦的是各省满分不一样:海南900分,上海660分,江苏2018-2020年才480分。就像用不同尺子量身高,没法直接比。我们想了个办法,都转换成750分制,公式很简单: 标准化分数 =(原始分数 ÷ 该省满分)× 750 用代码实现是这样的:
# 定义函数获取各省满分
def get_full_score(province, year):
if province == '海南':
return 900
elif province == '上海':
return 660
elif province == '江苏' and 2018 <= year <= 2020:
return 480
else:
return 750
# 计算标准化分数
score_distribution['std_mid_score'] = score_distribution.apply(
lambda row: (row['分数区间中值'] / get_full_score(row['省份'], row['年份'])) * 750, axis=1
)
比如海南考生考了600分,转换成750分制就是(600÷900)×750=500分,这样全国各省的分数就能放在一起比了。
统计性分析:高考数据里藏着哪些秘密?
各省分数“画像”大不同
我们算了各省每年的平均分、中位数和标准差。平均分就是大家常说的“平均成绩”,中位数是中间那位考生的分数(一半人比他高,一半比他低),标准差越大,说明分数差距越大。
以上海和云南为例:2018年上海综合类平均分530.23,中位数535.2,说明多数考生分数集中在中等偏上;云南文科平均分465.33,中位数463.0,分数整体低一些,但标准差和上海差不多,说明两地考生内部差距相近。
我们还把分数分成三段:高分段(≥600分,相当于750分制的80%)、中分段(390-540分)、低分段(<300分)。从2024年的数据看,北京、上海的高分段考生占比明显高于其他省份,这和当地教育资源丰富有很大关系。
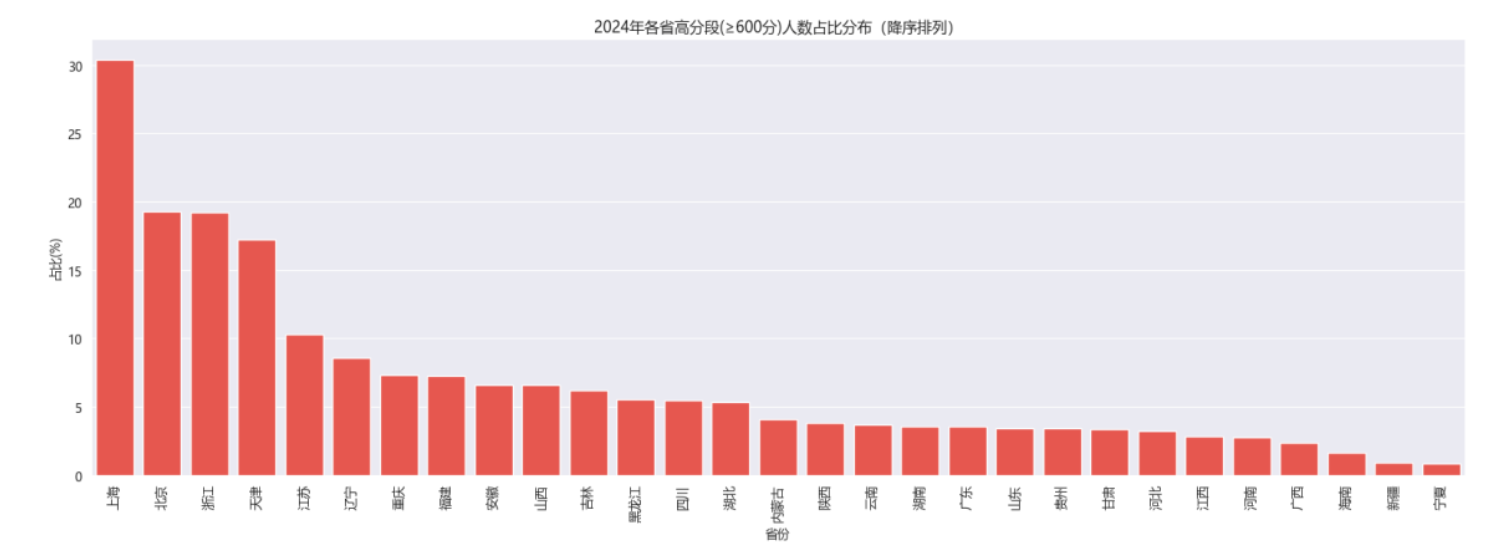
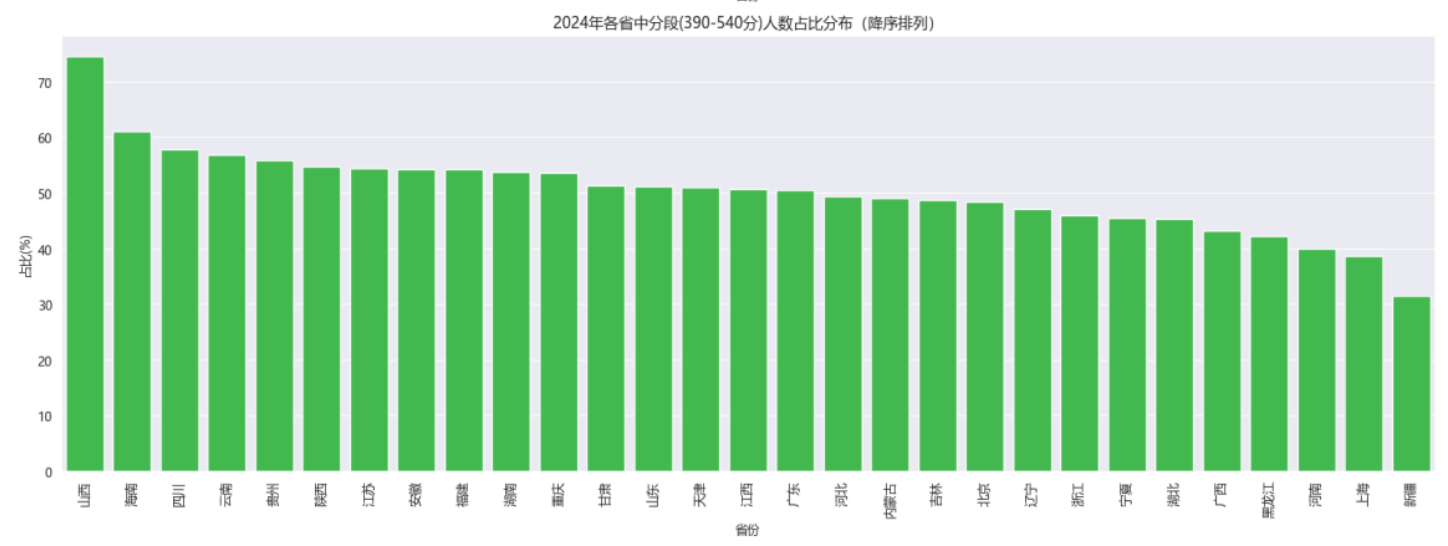
考生人数:河南、山东“压力山大”
全国考生人数分布很不均。我们画了张热力图,一眼就能看出:河南、山东的考生密密麻麻,而甘肃、新疆等省份考生就少多了。2024年河南考生人数比甘肃多了快10倍,这意味着在河南考大学,竞争自然更激烈。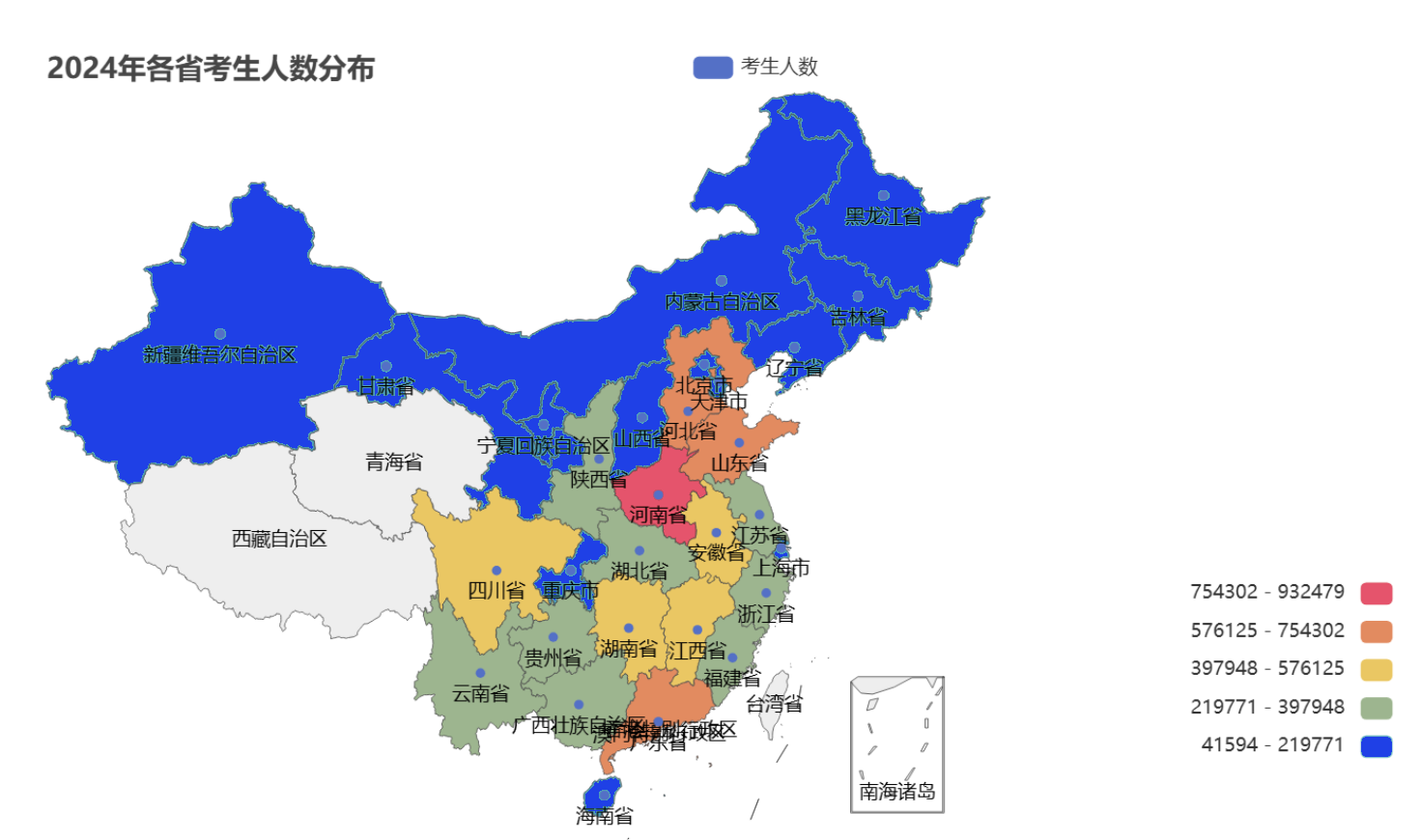
院校层次:985/211门槛有多高?
以河南为例,2024年不同层次院校的录取分差得很明显:985高校文科平均624分,理科604分;而专科线文科才310分,理科314分。这意味着,想上顶尖大学,分数得比专科线高出一倍还多。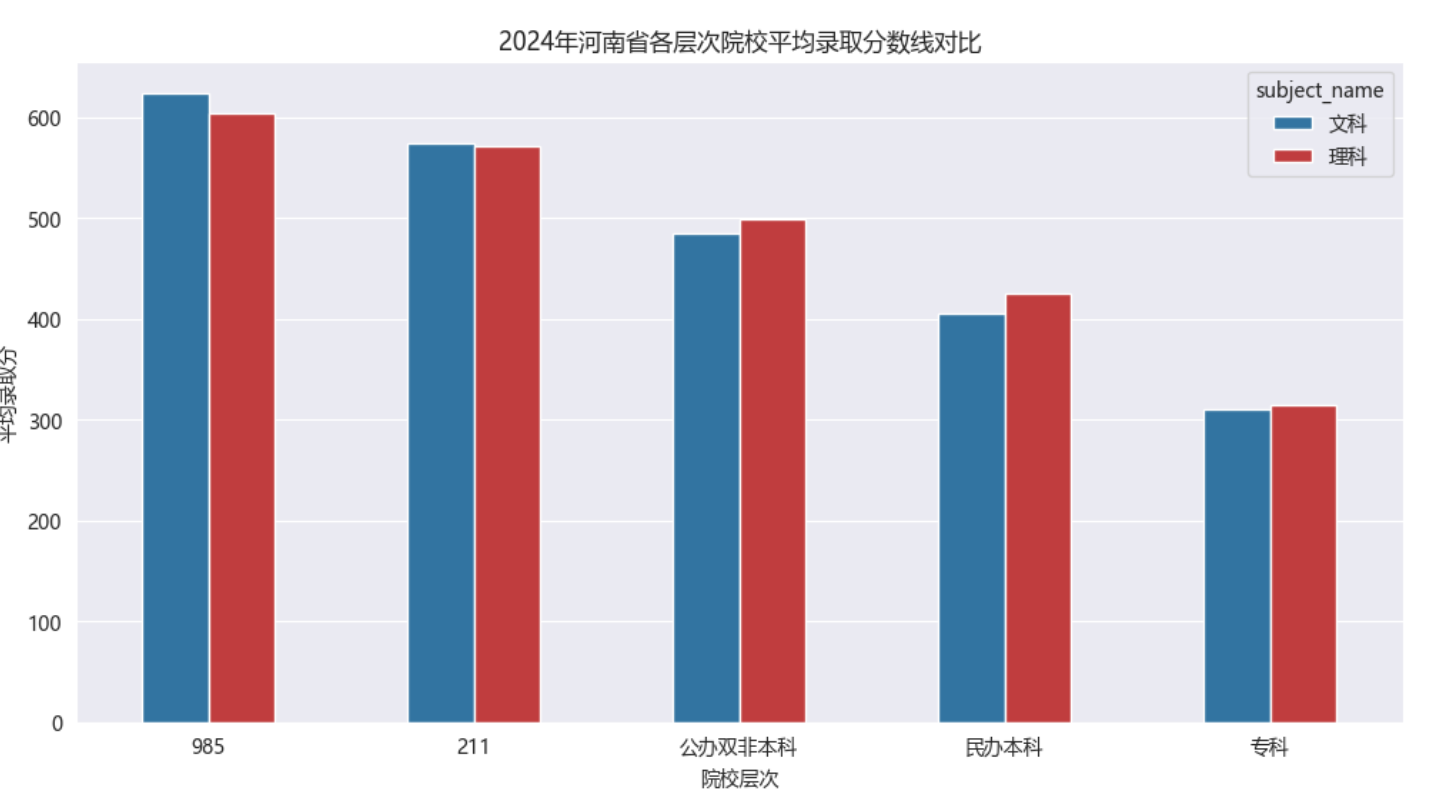
探索性分析:深挖数据里的“潜规则”
省份不同,分数线差多少?
2024年各省本科线(标准化到750分制后)差别不小:北京、上海的本科线普遍在450分以上,而有些西部省份可能不到400分。这不是说西部考生“更容易”,因为当地的教育资源、考生人数都不一样——北京考生少,高校多,分数线自然高一些;西部考生少但高校也少,分数线就低一些。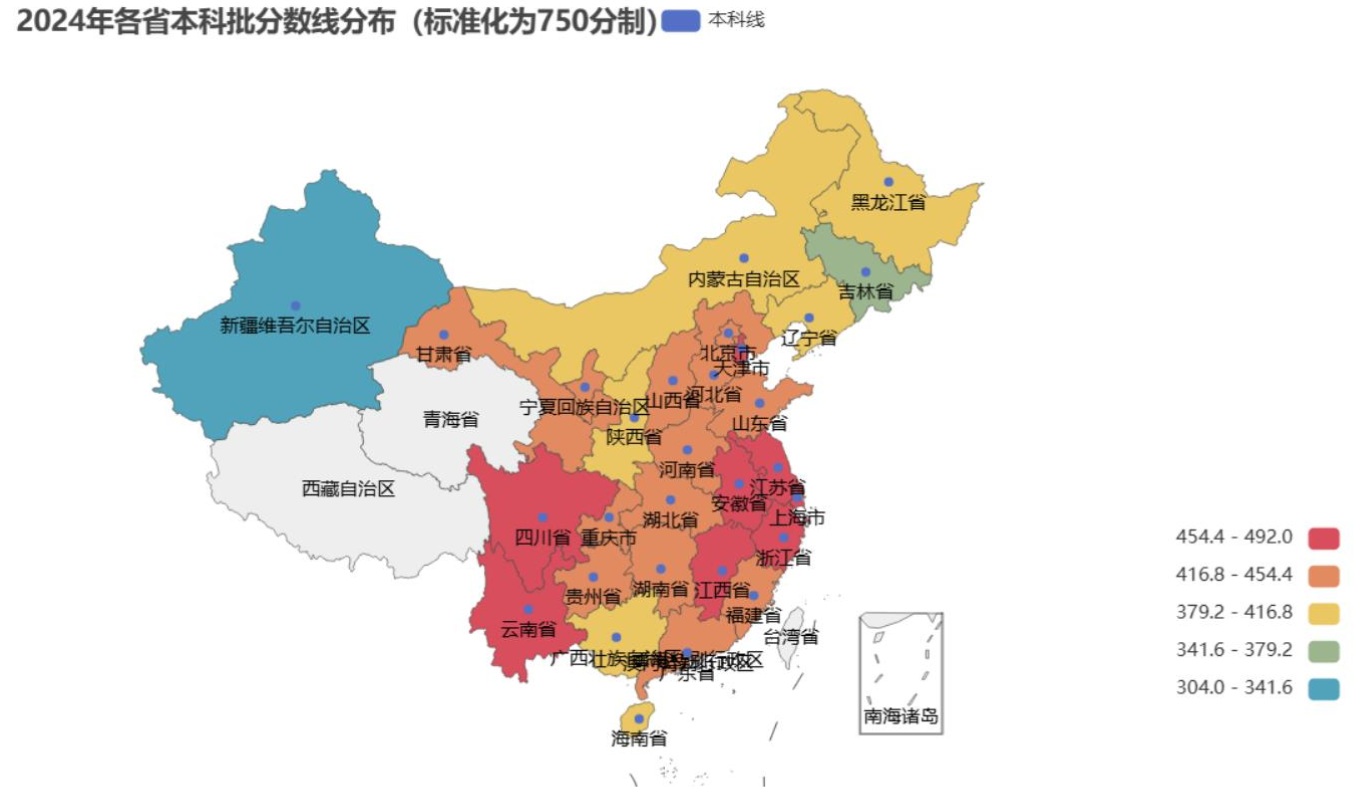
近7年分数线:涨了还是跌了?
我们看了北京、河南、广东、四川四个省2018-2024年的本科线和专科线,发现2020年是个“转折点”:很多省份的分数线在这一年下降了,后来又慢慢回升。这可能和当年的考试难度、招生计划调整有关。比如河南的本科线,2020年比2019年低了20多分,2021年又涨了回来。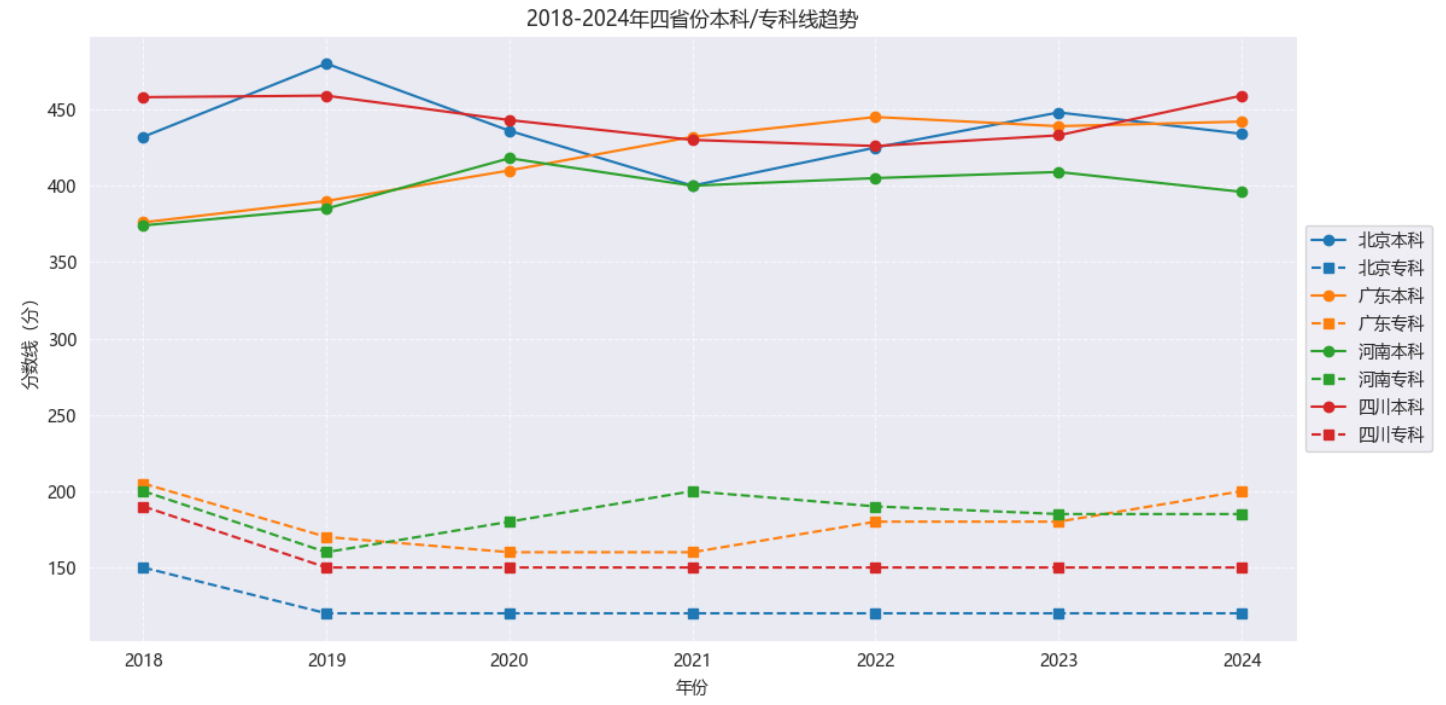

Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
运用多种数据分析方法对奥运奖牌进行预测研究,包括贝叶斯推断、梯度提升机等高级算法。
探索观点位次比分数更重要?
我们用河南2024年的数据做了个分析:把考生按位次百分比(排名越靠前,百分比越低)和院校层次(985=5分,211=4分,依此类推)画成散点图,发现两者关系很明显:位次每落后1%,能上的院校层次就降0.05分。也就是说,如果你在全省排前5%,可能稳上211;但排到20%,可能就只能上普通本科了。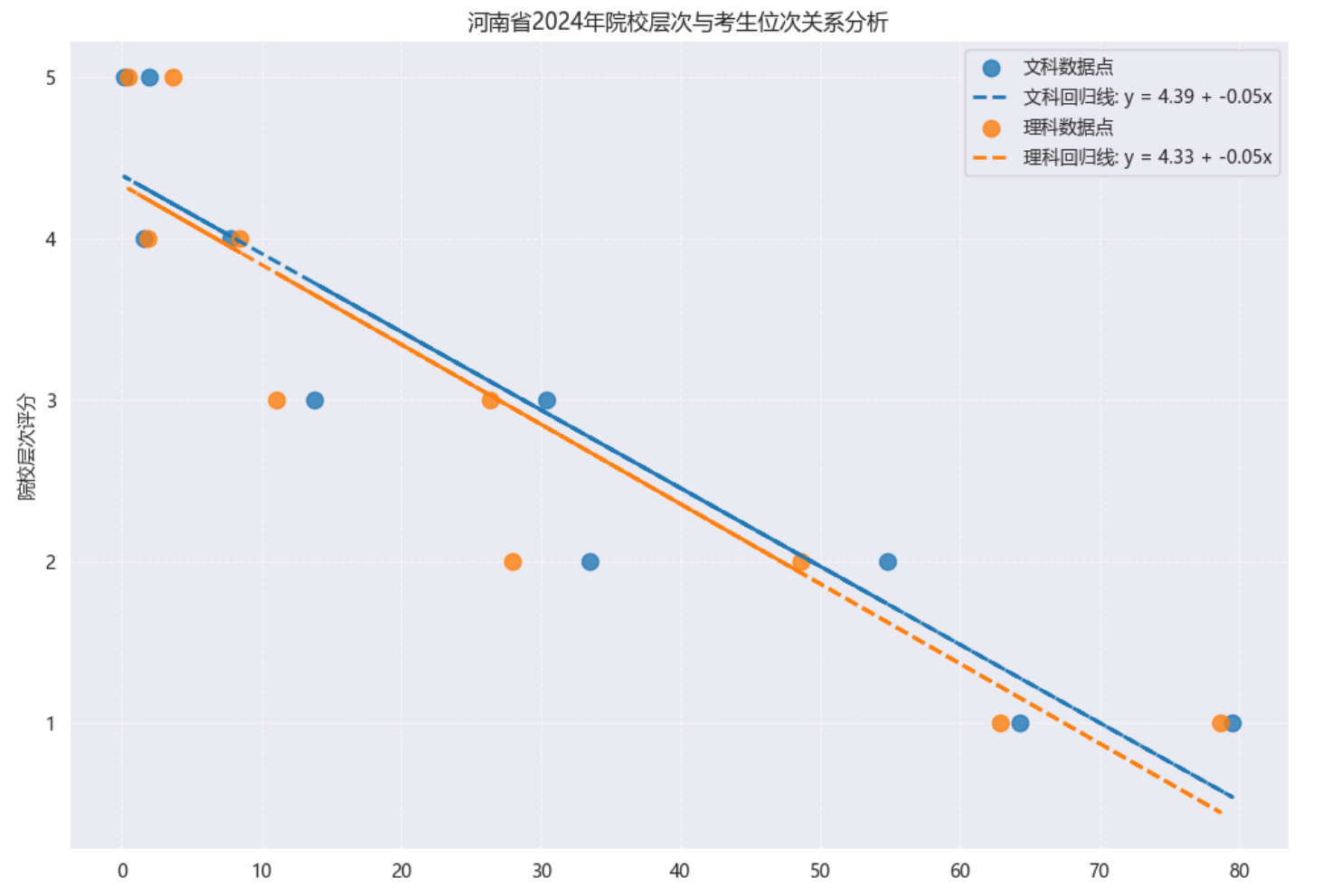
文理分科:分数分布不一样
拿黑龙江、河北、四川三省来说,2024年理科的中位数比文科高一点,而且分数更集中(箱线图的箱子更窄)。这可能是因为理科考生多,竞争更激烈,分数咬得紧;文科考生少,分数波动就大一些。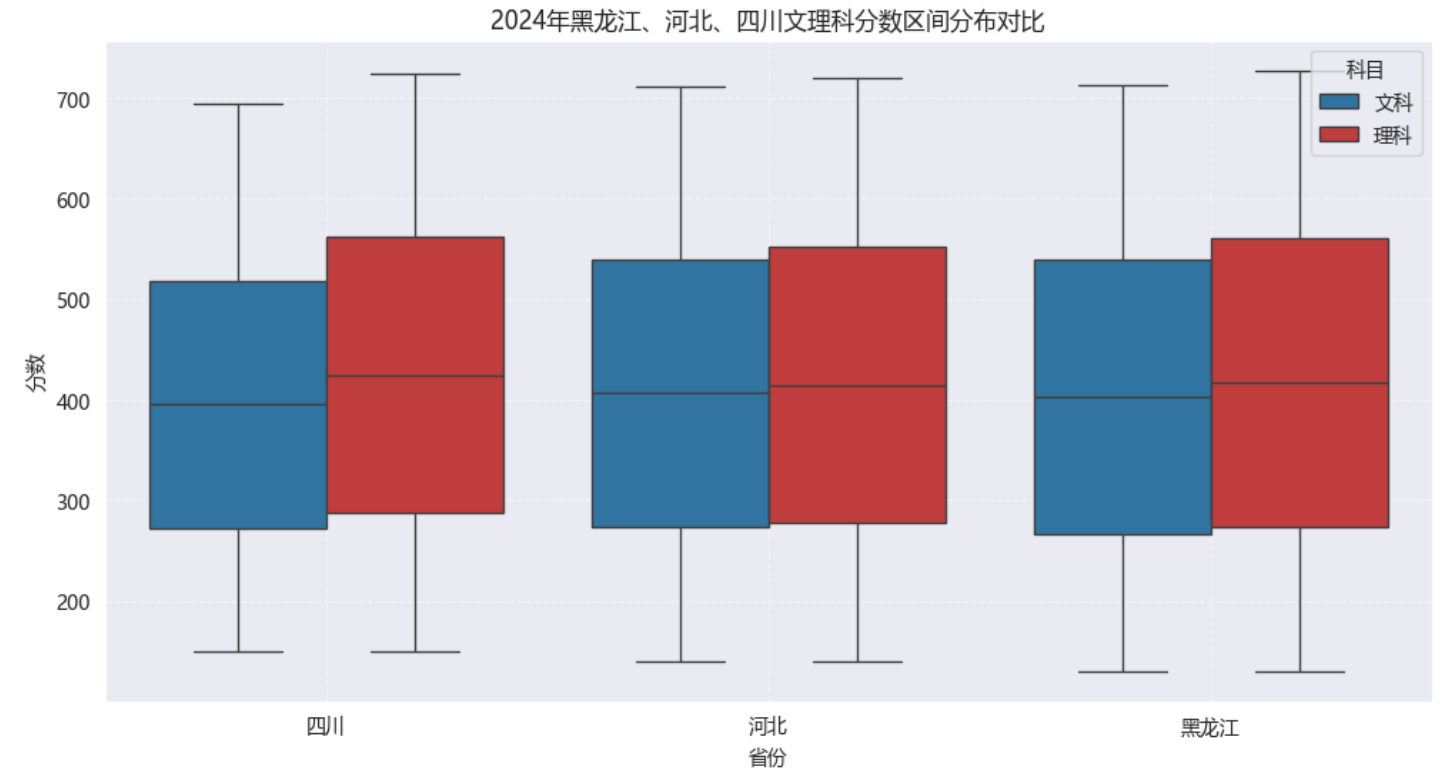
录取概率预测模型:给考生一个“定心丸”
怎么预测能不能被录取?
我们用随机森林模型,根据2018-2023年的数据训练了一个预测工具。简单说,就是把考生的分数、位次、省份这些信息输进去,模型会算出被目标大学录取的概率。 训练时,我们先造了些“模拟考生”:比如每个省份每年从300分到750分,每隔5分算一个,再看这些分数当年有没有被某所大学录取,用这些数据教模型“学习”。
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder
# 处理省份特征(把省份转换成数字编码)
encoder = OneHotEncoder()
province_encoded = encoder.fit_transform(major_admission_clean[['省份']]).toarray()
# 训练模型
model = RandomForestClassifier(n_estimators=50, random_state=42)
# 特征包括分数、位次百分比、省份编码
X = np.hstack([major_admission_clean[['分数', '位次百分比']], province_encoded])
# 标签:1=录取,0=未录取
y = major_admission_clean['是否录取']
model.fit(X, y)
模型准不准?
用2024年的数据测试,模型表现很好:平均AUC(区分录取与否的能力)接近1,精确率和召回率都在99%以上。这意味着,模型几乎能准确判断一个考生能不能被录取。
举个例子
河南省622分的考生,报哈尔滨工业大学,录取概率86%;报天津大学,概率42%。这说明,同样的分数,报不同学校风险差别很大。黑龙江462分考生报黑龙江大学,概率只有4%,看来得选个更稳妥的学校。
结论与建议
给考生:分数重要,策略更重要
考生填志愿时,别只看分数绝对值,要结合位次和往年数据。比如你考了600分,在河南可能能上不错的211,但在江苏可能只是中等水平。可以用我们的模型先算算概率,再决定冲一冲、稳一稳还是保一保。
给高校:招生计划要“看菜下饭”
高校在分配招生名额时,可以多看看各省的高分段比例。比如北京高分考生多,就可以多放些名额;河南考生多,适当增加计划能吸引更多优质生源。
给教育部门:缩小区域差距是关键
从数据看,各省分数线、考生机会还是有差距。可以多往西部投放优质教育资源,让更多地方的孩子有机会上好大学。 未来,我们还想把新高考的科目组合、综合素质评价这些因素加进模型,让预测更准。毕竟,高考数据里藏着千万考生的未来,把这些数据用好,就能帮更多人少走弯路。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 Python对历年高考分数线数据用聚类、决策树可视化分析一批、二批高校专业、位次、计划人数数据|附代码数据
Python对历年高考分数线数据用聚类、决策树可视化分析一批、二批高校专业、位次、计划人数数据|附代码数据 r语言逻辑回归(对数几率回归,Logistic)分析研究生录取数据实例
r语言逻辑回归(对数几率回归,Logistic)分析研究生录取数据实例 R语言可视化:ggplot2冲积/桑基图sankey分析大学录取情况、泰坦尼克幸存者数据
R语言可视化:ggplot2冲积/桑基图sankey分析大学录取情况、泰坦尼克幸存者数据



