LangGraphSwarm的银行数据分析群体智能代理:Text-to-SQL、EDA可视化与动态任务编排|附代码数据
作为一名分析师,我经常面对企业客户这样的困惑:“我们拥有海量数据,却很难快速从中提取 actionable insights。”

本项目完整代码数据资料已分享至会员群
群体智能代理(Swarm Agents) 是指一组自治的AI实体,每个实体执行特定的子任务,并通过结构化通信共同完成复杂目标。这种设计模仿了自然界中的蚁群或蜂群:没有中央指挥官,但个体通过简单规则和局部信息交互,涌现出全局智能。
在数据分析场景中,我们可以将任务拆分为“数据获取”、“数据清洗”、“统计分析”、“可视化”等多个环节,每个环节由一个专门的代理负责。代理之间通过预定义的切换工具(handoff tools)传递上下文,从而实现流水线式的协作。
1.2 核心设计原则
成功的群体代理系统通常遵循以下原则:
- 去中心化决策:每个代理独立运行,没有单一故障点。代理之间通过消息共享信息,实现灵活的任务分配。
- 角色专精:每个代理只关注自己擅长的领域,例如数据分析代理只处理SQL查询,可视化代理只负责绘图。职责清晰可提高效率。
- 结构化通信:代理之间通过标准化的切换工具进行交互,共享上下文(如查询语句、中间结果),确保信息一致。
- 容错与可扩展:工作负载分散在多个代理上,单个代理失效不影响整体流程。新增代理只需定义其角色和通信方式即可。
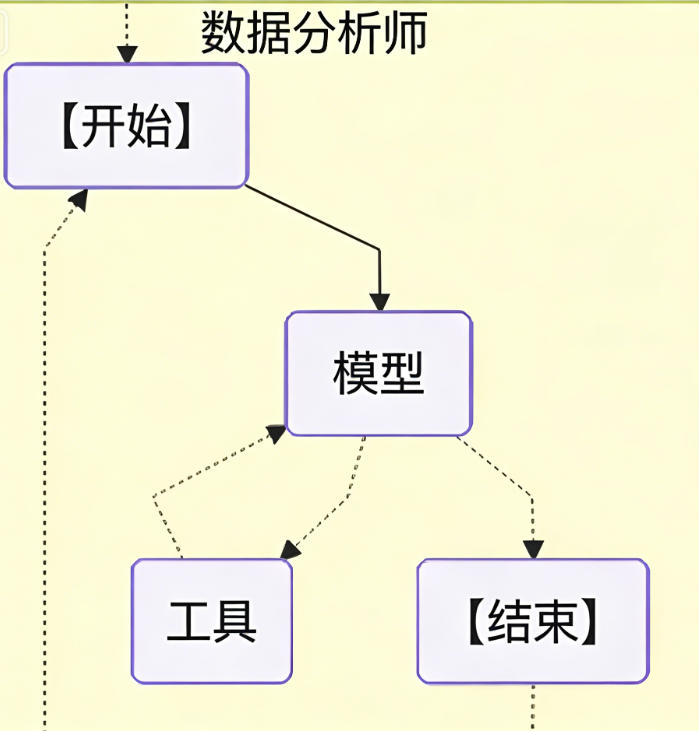
2. 系统架构设计
2.1 代理角色与职责
本系统包含两个核心代理和一个隐式协调者(由LangGraph Swarm框架自动管理):
本项目完整代码数据资料
- 数据分析代理(Data Analyst Agent) 职责:接收用户查询,解析为SQL语句,从数据库中提取数据,并返回结构化结果(如表格)。工具:SQL数据库工具包(SQLDatabaseToolkit),包含查询数据库、获取表结构等函数。
- 数据可视化代理(EDA Visualizer Agent) 职责:接收分析结果,选择合适的图表类型(如条形图、折线图),使用Python绘图库生成图表,并附带业务洞察。工具:Python REPL工具,用于执行绘图代码。
- 协调代理(Orchestrator) 由LangGraph Swarm内置,负责根据用户查询激活合适的代理,并在代理之间传递上下文。它相当于一个智能路由器。
2.2 数据流与协作机制
代理之间的协作通过**切换工具(handoff tools)**实现。当一个代理完成其任务后,可以主动调用切换工具,将控制权转交给另一个代理。整个数据流如下:
- 用户提交查询(例如:“按省份统计客户数,并绘制条形图”)。
- 协调代理启动,默认激活数据分析代理。
- 数据分析代理解析查询,执行SQL,返回结果表格。
- 数据分析代理调用切换工具,将结果传递给可视化代理。
- 可视化代理读取结果,生成图表并输出。
- 如有需要,可视化代理可再次切换回数据分析代理进行更深层次分析。
这种动态切换机制使得系统能够处理多轮迭代查询。
3. 基于LangGraph Swarm的实现
3.1 环境配置与依赖
首先安装所需Python库。我们使用LangChain生态的LangGraph Swarm模块来构建多代理系统。
pip install langchain==1.2.4 \
langgraph==1.0.6 \
langgraph-swarm \
langchain-openai==1.1.4 \
langchain-community==0.4.1 \
langchain-experimental==0.4.0
此外需要SQLite支持(本例使用本地银行数据库banking_insights.db)。
# 导入必要模块
from langchain_openai import ChatOpenAI
from langgraph_swarm import create_swarm, create_handoff_tool, SwarmState
from langgraph.checkpoint.memory import MemorySaver
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_experimental.utilities import PythonREPL
# 初始化大语言模型
model = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
# 连接数据库
database = SQLDatabase.from_uri("sqlite:///banking_insights.db")
# 创建SQL工具包
sql_tools_kit = SQLDatabaseToolkit(db=database, llm=model)
sql_tools = sql_tools_kit.get_tools()
3.2 代理提示词设计
每个代理需要明确的系统提示词来限定其行为。
# 数据分析代理提示词(已翻译为中文)
DATA_ANALYST_PROMPT = """
你是一位数据分析专家,精通零售银行业务的SQL查询。
你的主要任务:
- 将用户的问题转换为正确的SQL语句
- 从数据库中准确提取数据
- 提供简洁的事实性摘要
- 当需要可视化时,将结果交给EDA可视化代理
"""
# 可视化代理提示词
EDA_VISUALIZER_PROMPT = """
你是一位EDA可视化专家,擅长数据分析和图表绘制。
你的职责:
- 创建清晰、业务就绪的图表
- 使用Python进行绘图
- 返回支持决策的可视化洞察
"""
3.3 切换工具与代理创建
代理之间通过切换工具进行通信。
# 定义切换工具
handoff_to_vis = create_handoff_tool(
agent_name="eda_visualizer",
description="将控制权交给EDA可视化代理,用于生成图表",
)
handoff_to_analyst = create_handoff_tool(
agent_name="data_analyst",
description="将控制权交还给数据分析代理,进行更多SQL分析",
)
from langgraph_swarm import create_agent
# 数据分析代理
data_agent = create_agent(
model,
tools=sql_tools + [handoff_to_vis],
system_prompt=DATA_ANALYST_PROMPT,
name="data_analyst"
)
# 可视化代理
vis_agent = create_agent(
model,
tools=[PythonREPL(), handoff_to_analyst],
system_prompt=EDA_VISUALIZER_PROMPT,
name="eda_visualizer"
)
3.4 构建群体工作流
使用create_swarm将两个代理组合成群体,并指定默认激活代理。
# 创建工作流
workflow = create_swarm(
agents=[data_agent, vis_agent],
default_active_agent="data_analyst",
state_schema=SwarmState
)
# 添加记忆功能
memory = MemorySaver()
swarm_app = workflow.compile(checkpointer=memory)
def run_banking_analysis(query_text: str, thread_id: str = "default"):
"""执行银行数据分析查询"""
return swarm_app.invoke(
{"messages": [("user", query_text)]},
config={"configurable": {"thread_id": thread_id}}
)
4. 银行数据分析案例
4.1 查询执行与结果
我们用一个典型的多层下钻查询来测试系统:从省份维度开始,逐层深入到支行和账户类型,统计账户数量。
output = run_banking_analysis(
"从客户省份开始,然后下钻到该省份内的支行,最后到每个支行下的账户类型,展示每一层的账户数量",
thread_id="drilldown_test"
)
======================================================================
群体分析结果: '从客户省份开始,然后下钻到该省份内的支行,最后到每个支行下的账户类型,展示每一层的账户数量'
======================================================================
USER: 从客户省份开始,然后下钻到该省份内的支行,最后到每个支行下的账户类型,展示每一层的账户数量
4.2 可视化输出与解读
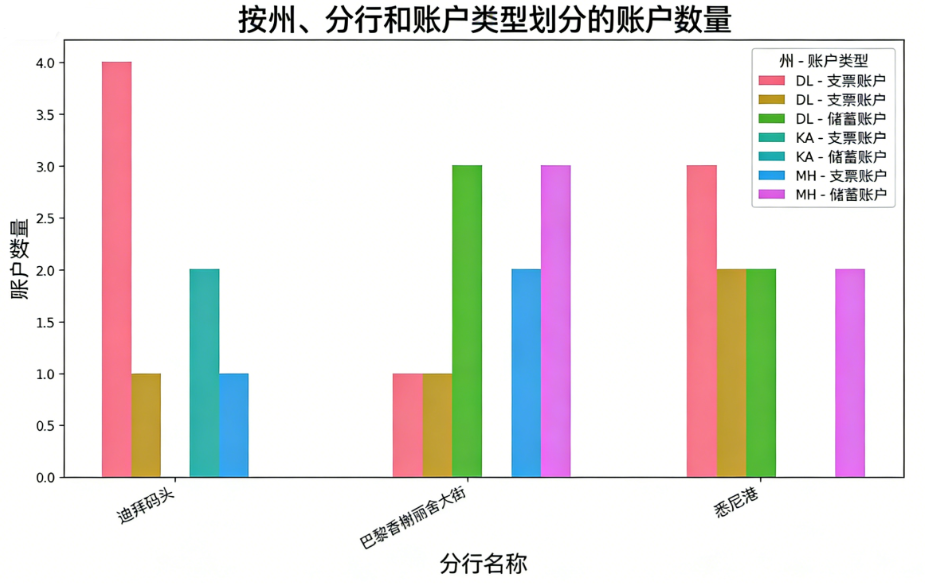
可视化代理生成了分组条形图,展示了各省份、支行、账户类型的账户数量分布。
可视化代理进一步提供了业务洞察:
EDA可视化代理: 我创建了一个分组条形图,展示了按客户省份、支行和账户类型划分的账户数量。每组条形代表一个支行,条形颜色和标签由省份与账户类型的组合决定。
洞察:
- 东部省份的A支行中,活期账户数量显著高于储蓄账户。
- 南部省份的B支行中,两类账户分布较为均衡,其中C省的储蓄账户在该支行数量最多。
- 西部省份的C支行中,活期账户在D省和E省占比较高,而储蓄账户在F省和G省更为突出。
该图有助于识别哪些支行和省份在特定账户类型上更集中,从而为营销资源分配提供依据。
如需更直观地展示从省份到支行再到账户类型的层级结构,我可以生成树状图或旭日图。是否需要我进一步处理?
相关文章(后面要换一行)
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
5. 结论与展望
本文展示了如何利用LangGraph Swarm框架构建一个由数据分析代理和可视化代理组成的群体智能系统。通过将复杂查询拆解为SQL提取与图表绘制两个子任务,并让专业代理各司其职,系统实现了:
- 自动化端到端分析:从自然语言到业务图表,全程无需人工干预。
- 可解释性:代理生成的图表附带文字洞察,帮助用户理解数据背后的含义。
- 可扩展性:未来可加入更多代理,如数据清洗代理、异常检测代理等,进一步增强系统能力。
这一模式已在多个咨询项目中验证其有效性,特别适合需要快速响应、多维度下钻的数据分析场景。随着大语言模型能力的不断提升,群体智能代理将成为企业数据决策的核心引擎。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂“怎么做”,也懂“为什么这么做”;遇代码运行问题,更能享24小时调试支持。
附录:项目文件目录
project/
├── banking_insights.db # 银行示例数据库
├── swarm_agents.py # 代理定义与工作流(完整代码进群获取)
├── requirements.txt # 依赖库列表
├── utils.py # 工具函数(如数据库连接)
└── run_analysis.py # 执行入口
注:为保护核心逻辑,部分代码已省略。获取完整代码请按文末方式加入社群。
# 数据分析代理提示词
DATA_ANALYST_PROMPT = """
你是一位数据分析专家,精通零售银行业务的SQL查询。
你的主要任务:
- 将用户的问题转换为正确的SQL语句
- 从数据库中准确提取数据
- 提供简洁的事实性摘要
- 当需要可视化时,将结果交给EDA可视化代理
"""
# 可视化代理提示词
EDA_VISUALIZER_PROMPT = """
你是一位EDA可视化专家,擅长数据分析和图表绘制。
你的职责:
- 创建清晰、业务就绪的图表
- 使用Python进行绘图
- 返回支持决策的可视化洞察
"""
3.3 切换工具与代理创建
代理之间通过切换工具进行通信。
现在创建两个代理实例。
获取完整代码请阅读原文加入社群。
3.4 构建群体工作流
使用create_swarm将两个代理组合成群体,并指定默认激活代理。
最后定义一个执行函数作为对外接口。
4. 银行数据分析案例
4.1 查询执行与结果
我们用一个典型的多层下钻查询来测试系统:从省份维度开始,逐层深入到支行和账户类型,统计账户数量。
执行过程中,代理会自动完成SQL编写、数据提取和图表绘制。以下是部分输出摘要:
获取完整代码请阅读原文加入社群。
4.2 可视化输出与解读
可视化代理生成了分组条形图,展示了各省份、支行、账户类型的账户数量分布。
可视化代理进一步提供了业务洞察:
……
获取完整代码请阅读原文加入社群。
5. 结论与展望
本文展示了如何利用LangGraph Swarm框架构建一个由数据分析代理和可视化代理组成的群体智能系统。通过将复杂查询拆解为SQL提取与图表绘制两个子任务,并让专业代理各司其职,系统实现了:
- 自动化端到端分析:从自然语言到业务图表,全程无需人工干预。
- 可解释性:代理生成的图表附带文字洞察,帮助用户理解数据背后的含义。
- 可扩展性:未来可加入更多代理,如数据清洗代理、异常检测代理等,进一步增强系统能力。
这一模式已在多个咨询项目中验证其有效性,特别适合需要快速响应、多维度下钻的数据分析场景。随着大语言模型能力的不断提升,群体智能代理将成为企业数据决策的核心引擎。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载 2025无人驾驶智能驾驶报告:从L2平权到L4商业化,技术、成本与政策的共振时刻 | 附120+份报告PDF、数据、可视化模板汇总下载
2025无人驾驶智能驾驶报告:从L2平权到L4商业化,技术、成本与政策的共振时刻 | 附120+份报告PDF、数据、可视化模板汇总下载



