t检验是统计学中最常用的检验之一。双样本t检验允许我们基于来自两组中的每一组的样本来测试两组的总体平均值相等的零假设。
这在实践中意味着什么?如果我们的样本量不是太小,如果我们的数据看起来违反了正常假设,我们就不应过分担心。此外,出于同样的原因,即使X不正常(同样,当样本量足够大时),组均值差异的95%置信区间也将具有正确的覆盖率。当然,对于小样本或高度偏斜的分布,上述渐近结果可能不会给出非常好的近似,因此类型1误差率可能偏离标称的5%水平。
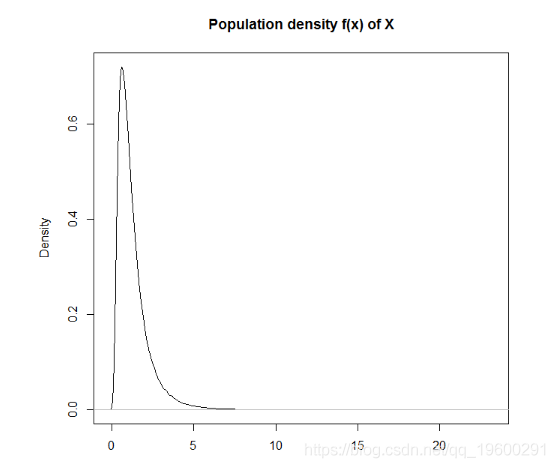
现在让我们用R来检验样本均值分布(在重复样本中)收敛到正态分布的速度。我们将模拟来自对数正态分布的数据 – 即log(X)遵循正态分布。我们可以通过从正态分布中取幂随机抽取来从此分布中生成随机样本。首先,我们将绘制一个大的(n = 100000)样本并绘制其分布以查看它的外观: 我们可以看到它的分布是高度偏斜的。从表面上看,我们会担心对这些数据使用t检验,假设X是正态分布的。

为了看看样本的样本分布,我们将选择样本大小为n,并从对数正态分布中重复绘制大小为n的样本,计算样本均值,然后绘制这些样本均值的分布。以下显示n = 3的样本平均值的直方图(来自10,000个重复样本):
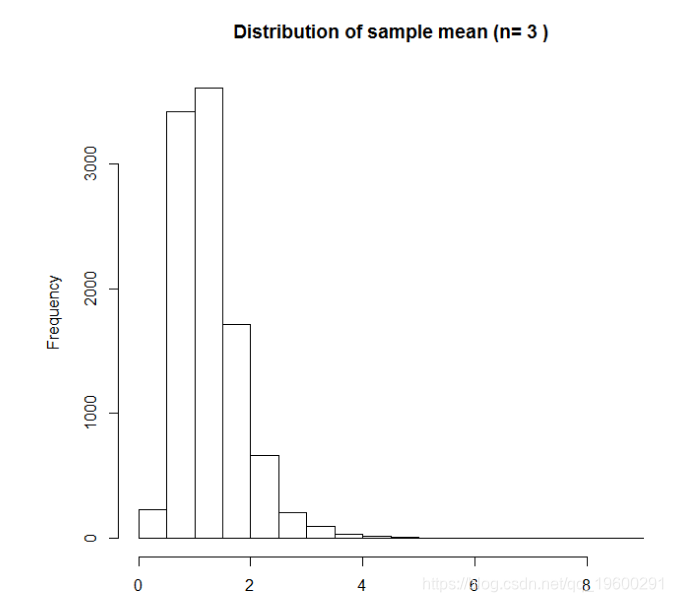

样本均值的分布,n = 3
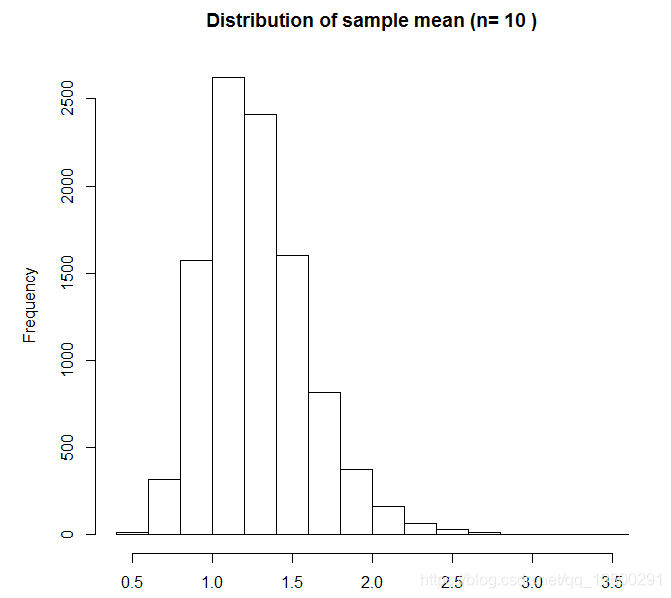
这里的采样分布是倾斜的。如此小的样本量,如果其中一个样本从分布的尾部具有高值,则这将给出与真实均值相差很远的样本均值。如果我们重复,但现在n = 10: 它现在看起来更正常,但它仍然是偏斜的 – 样本均值有时很大。请注意,x轴范围现在更小 – 样本均值的可变性现在小于n = 3。最后,我们尝试n = 100:

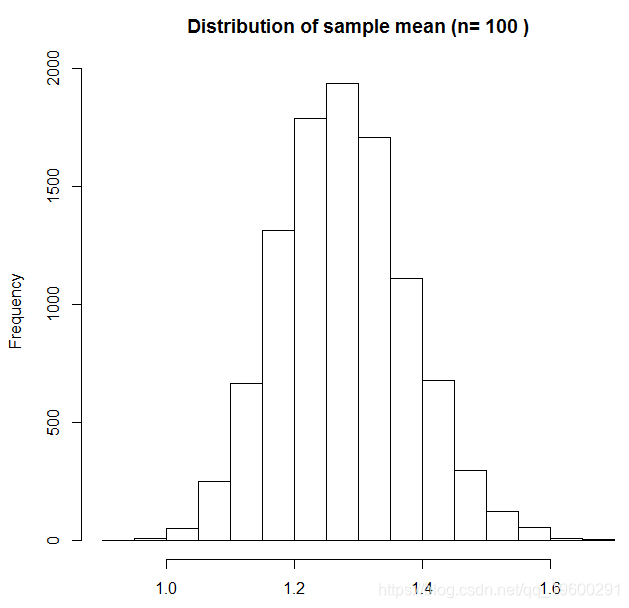

现在样本均值的分布(来自人口的重复样本)看起来非常正常。当n很大时,即使我们的一个观测结果可能位于分布的尾部,分布中心附近的所有其他观测值也会保持平均值。这表明对于这个特定的X分布,t检验应该是正确的,n = 100 。检查这种情况的更直接的方法是进行模拟研究,其中我们凭经验估计t检验的1型错误率,在给定的n选择下应用于该分布。
当然,如果X不是正态分布的,即使假设正态性的t检验的类型1错误率接近5%,测试也不会是最佳的。也就是说,将存在零假设的替代测试,其具有检测替代假设的更大功率。
非常感谢您阅读本文,有任何问题请在下面留言!
1
1
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
 Spss用K均值聚类Kmeans、决策树、逻辑回归和T检验研究不同因素对通勤出行交通方式选择的影响调查数据分析
Spss用K均值聚类Kmeans、决策树、逻辑回归和T检验研究不同因素对通勤出行交通方式选择的影响调查数据分析


