这个数据集常用于数据概述、可视化和聚类模型。
它包括三个鸢尾花品种,每个品种有50个样本,以及一些属性。
数据集概述
其中一个花种与其他两个花种是线性可分离的,但其他两个花种之间不是线性可分离的。
这个数据集的给定列是:
i> Id
ii> 萼片长度(Cm)
iii>萼片宽度(Cm)
iv> 花瓣长度(Cm)
v> 花瓣宽度 (Cm)
vi> 品种
可下载资源
让我们把这个数据集可视化,并用kmeans进行聚类。
基本可视化
IRIS数据,聚类前的基本可视化
plot(data, aes(x , y ))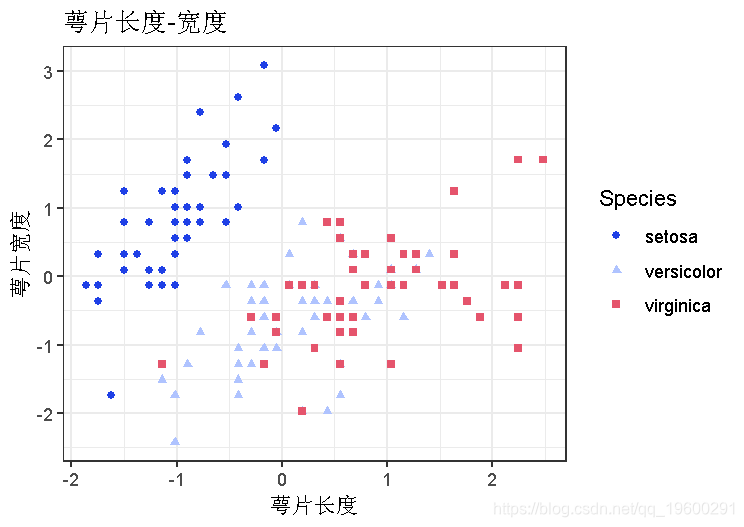
plot(data,geom_density(alpha=0.25)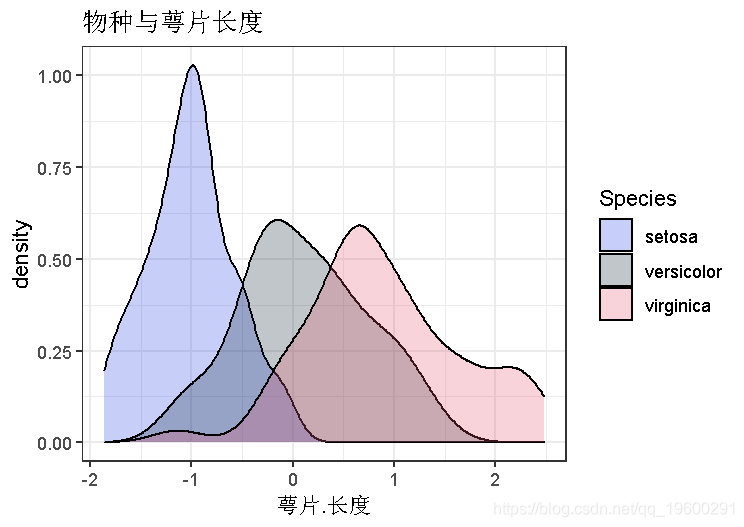
火山图
plot( iris, stat_density(aes(ymax = ..density.., ymin = -..density..,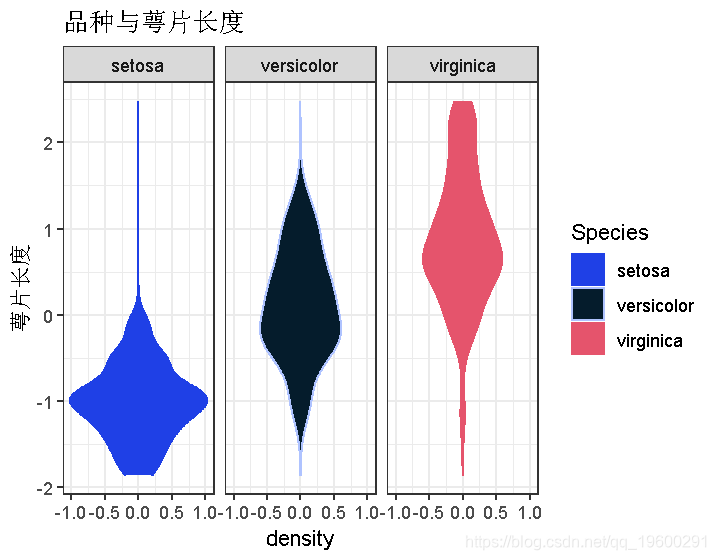
plot(data, aes(x ),stat\_density= ..density.., facet\_grid. ~ Species)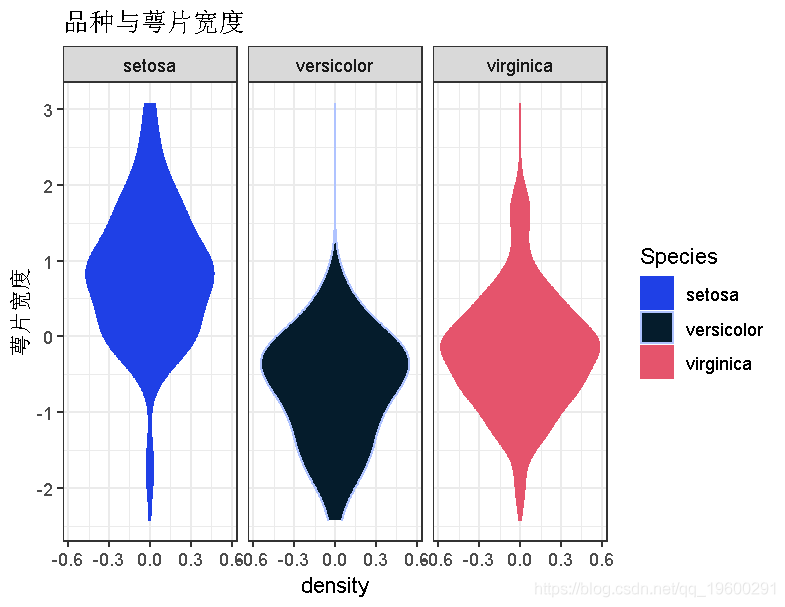
聚类数据 :: 方法-1
# 在一个循环中进行15次的kmeans聚类分析
for (i in 1:15)
kmeans(Data, i)
totalwSS\[i\]<-tot
# 聚类碎石图 - 使用plot函数绘制total_wss与no-of-clusters的数值。
plot(x=1:15, # x= 类数量, 1 to 15
totalwSS, #每个类的total_wss值
type="b" # 绘制两点,并将它们连接起来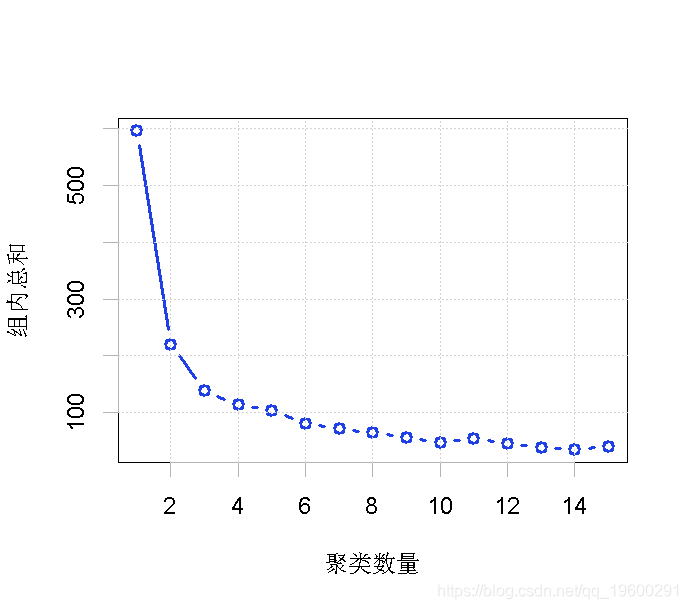
聚类数据 :: 方法-2
使用聚类有效性测量指标
library(NbClust)
# 设置边距为: c(bottom, left, top, right)
par(mar = c(2,2,2,2))
# 根据一些指标来衡量聚类的合适性。
# 默认情况下,它检查从2个聚类到15个聚类的情况 # 花费时间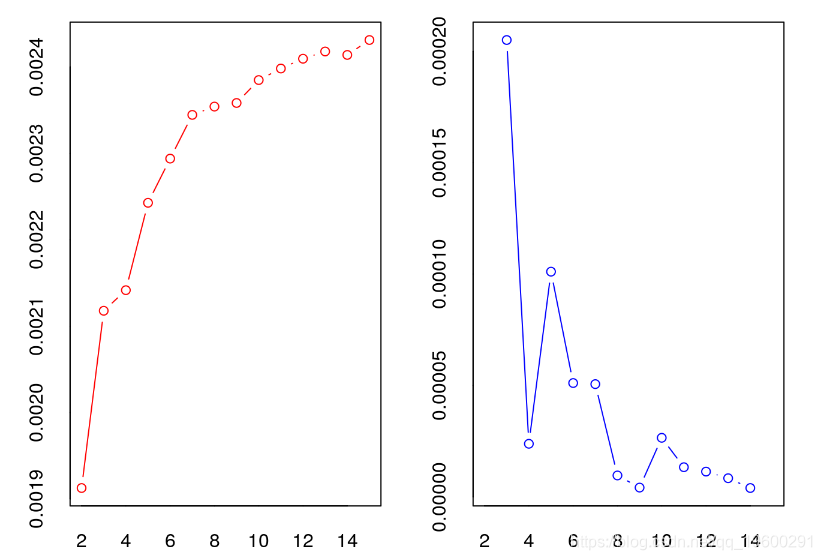
休伯特指数
休伯特指数是一种确定聚类数量的图形方法。
在休伯特指数图中,我们寻找一个明显的拐点,对应于测量值的明显增加,即休伯特指数第二差值图中的明显峰值。
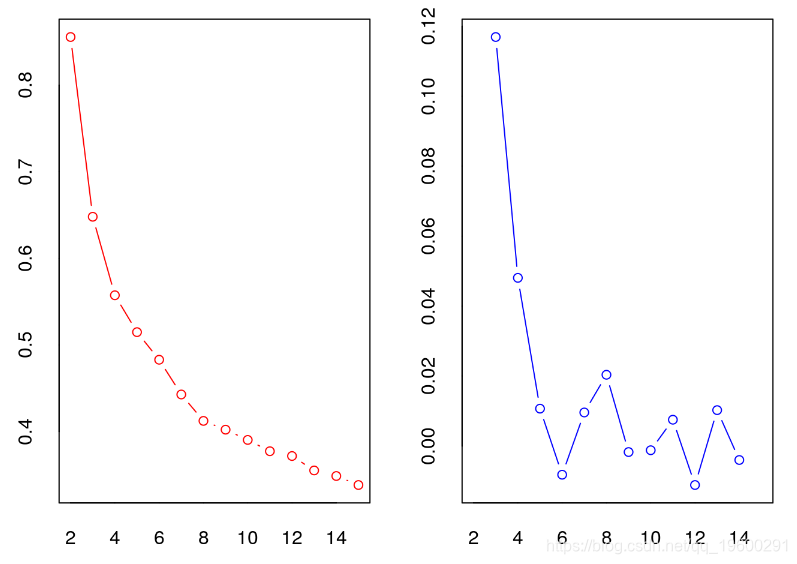
D指数
在D指数的图表中,我们寻找一个重要的拐点(D指数第二差值图中的重要峰值),对应于测量值的显著增加。
随时关注您喜欢的主题
##
## *******************************************************************
## * 在所有指数中:
## * 10 proposed 2 as the best number of clusters
## * 8 proposed 3 as the best number of clusters
## * 2 proposed 4 as the best number of clusters
## * 1 proposed 5 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 1 proposed 14 as the best number of clusters
## * 1 proposed 15 as the best number of clusters
##
## ***** 结论*****
##
## * 根据多数规则,集群的最佳数量是2
##
##
## *******************************************************************画一个直方图,表示各种指数对聚类数量的投票情况。
在26个指数中,大多数(10个)投票给2个聚类,8个投票给3个聚类,其余8个(26-10-8)投票给其他数量的聚类。
直方图,断点=15,因为我们的算法是检查2到15个聚类的。
hist(Best.nc)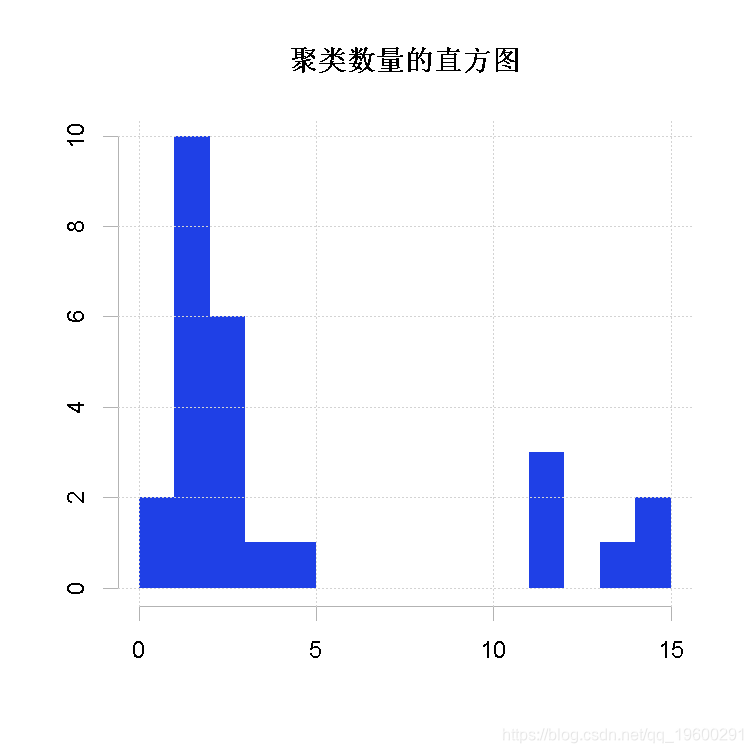
聚类数据 :: 方法-3
卡林斯基指标类似于寻找群组间方差/群组内方差的比率。
KM(Data, 1, 10) # 对聚类1至10的测试
# sortg = TRUE:将iris对象(行)作为其组别成员的函数排序
# 在热图中用颜色表示组成员类
# 排序是为了产生一个更容易解释的图表。
# 两个图。一个是热图,另一个是聚类数目与值(=BC/WC)。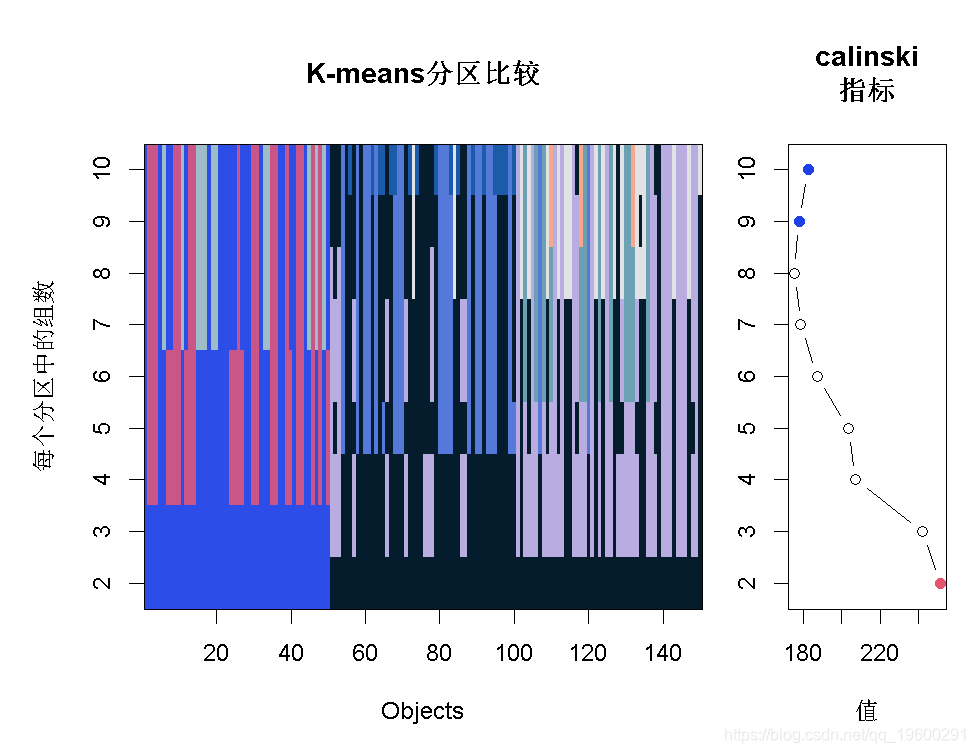
modelData$results\[2,\] # 针对BC/WC值的聚类
# 那么,这些数值中哪一个是最大的?BC/WC应尽可能的大
which.max(modelData$results\[2,\])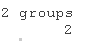
用Silhoutte图对数据进行聚类 :: 方法-4
先试着2个类
# 计算并返回通过使用欧氏距离测量法计算的距离矩阵,计算数据矩阵中各行之间的距离。
# 获取silhoutte 系数
silhouette (cluster, dis)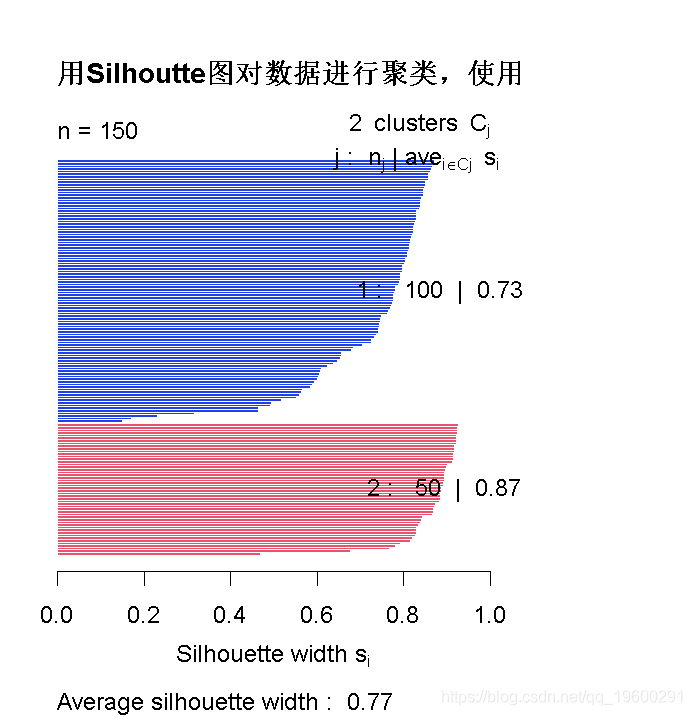
试用8个聚类
# 计算并返回通过使用欧氏距离测量法计算的距离矩阵,计算数据矩阵中各行之间的距离。
# 获取silhoutte 系数
silhouette (cluster, dis)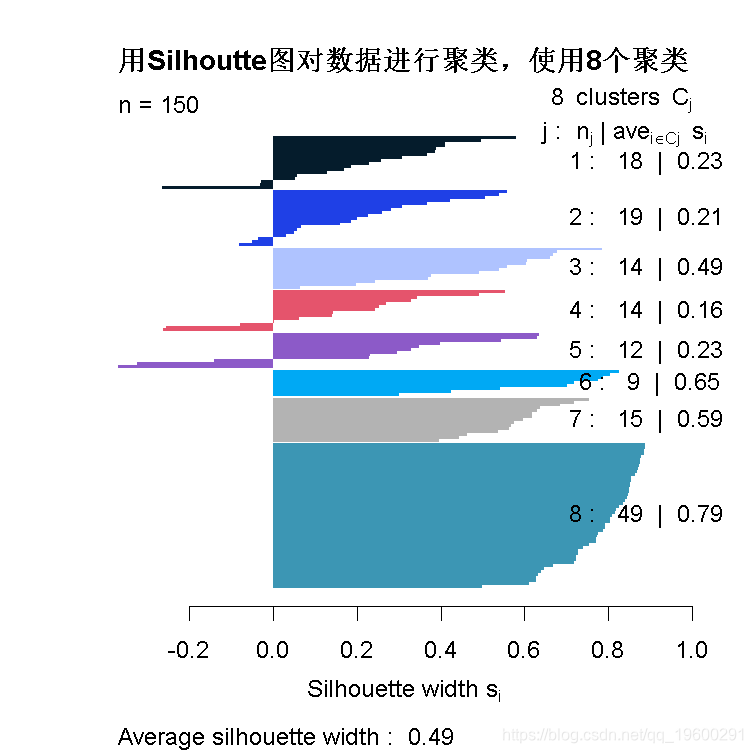
计算iris和随机数据集的霍普金统计值
分析聚类趋势
# 1. 给定一个数字向量或数据框架的一列 根据其最小值和最大值生成统一的随机数
runif(length(x), min(x), (max(x)))
# 2. 通过在每一列上应用函数生成随机数据
apply(iris\[,-5\], 2, genx)
# 3. 将两个数据集标准化
scale(iris) # 默认, center = T, scale = T
# 4. 计算数据集的霍普金斯统计数字
hopkins_stat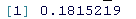
# 也可以用函数hopkins()计算。
hopkins(iris)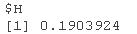
# 5. 计算随机数据集的霍普金斯统计量
hopkins_stat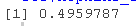
 R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码
R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码 SPSS大学生网络购物行为研究:因子分析、主成分、聚类、交叉表和卡方检验
SPSS大学生网络购物行为研究:因子分析、主成分、聚类、交叉表和卡方检验 R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化
R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化 R语言拟合线性混合效应模型、固定效应、随机效应参数估计可视化生物生长、发育、繁殖影响因素
R语言拟合线性混合效应模型、固定效应、随机效应参数估计可视化生物生长、发育、繁殖影响因素


