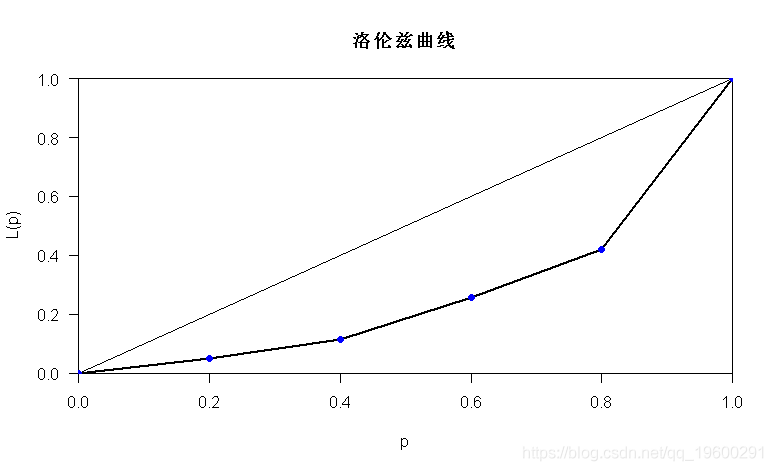
洛伦兹曲线来源于经济学,用于描述社会收入不均衡的现象。
将收入降序排列,分别计算收入和人口的累积比例。
本文,我们研究收入和不平等。我们从一些模拟数据开始
可下载资源
洛伦兹曲线来源于经济学,用于描述社会收入不均衡的现象。将收入降序排列,分别计算收入和人口的累积比例,并将其分别作为y和x绘制曲线。
首先,极端的情况下,每个人的收入都是一样的,那么每个人的收入就等于人均收入,则收入累积比例一定会等于收入累积比例,也就是图中的对角线,表示的是绝对的财富均衡。而实际上,我们是按照收入降序来分别计算收入的,头部的高收入群占人口总数较少,但其收入占全体收入的比例却很高,即随着收入的下降,收入累积占比优先于人口累积占比迅速上升,最后增加较少,而人口累积占比在低收入段的增长却会大于收入累积占比,从而表现出上图中向左上凸起的曲线,这条曲线约贴合于y轴,则说明收入越不平等,极端的情况下,1%的人口占了99%的收入,则该曲线基本呈直角的折线。
> (income=sort(income))
[1] 19246 23764 53237 61696 218835 为什么说这个样本中存在不平等?如果我们看一下最贫穷者拥有的财富,最贫穷的人(五分之一)拥有5%的财富;倒数五分之二拥有11%,依此类推
> income[1]/sum(income)
[1] 0.0510
> sum(income[1:2])/sum(income)
[1] 0.1140 如果我们绘制这些值,就会得到 洛伦兹曲线
> plot(Lorenz(income))
> points(c(0:5)/5,c(0,cumsum(income)/sum(income)) 
现在,如果我们得到500个观测值。直方图是可视化这些数据分布的方法
> summary(income)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2191 23830 42750 77010 87430 2003000
> hist(log(income), 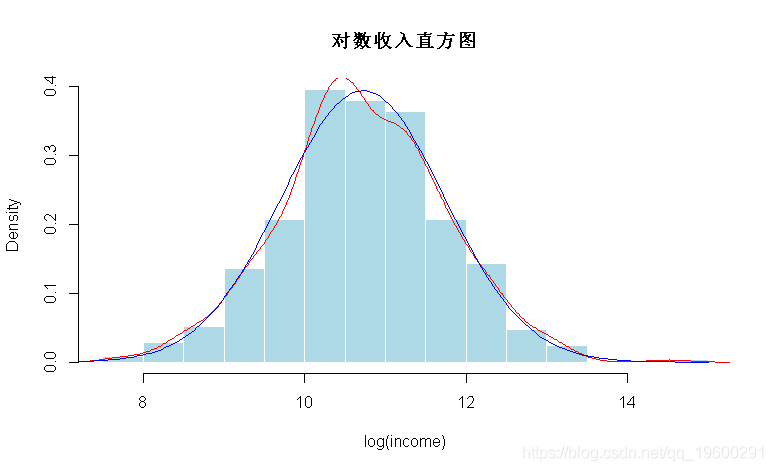
在这里,我们使用直方图将样本可视化。但不是收入,而是收入的对数(由于某些离群值,我们无法在直方图上可视化)。现在,可以计算 基尼系数 以获得有关不平等的一些信息
> gini=function(x){
+ mu=mean(x)
+ g=2/(n*(n-1)*mu)*sum((1:n)*sort(x))-(n+1)/(n-1) 实际上,没有任何置信区间的系数可能毫无意义。计算置信区间,我们使用boot方法
> G=boot(income,gini,1000)
> hist(G,col="light blue",border="white" 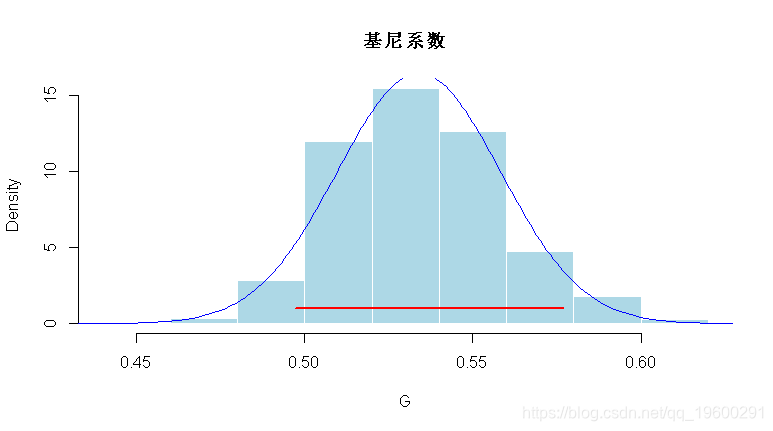
红色部分是90%置信区间,
5% 95%
0.4954235 0.5743917 还包括了一条具有高斯分布的蓝线,
> segments(quantile(G,.05),1,quantile(G,.95),1,
> lines(u,dnorm(u,mean(G),sd(G)), 另一个流行的方法是帕累托图(Pareto plot),我们在其中绘制了累积生存函数的对数与收入的对数,
> plot(x,y) 
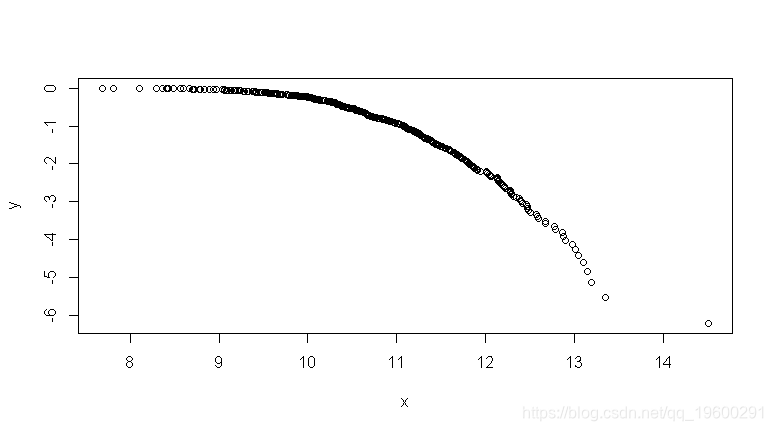
如果点在一条直线上,则意味着可以使用帕累托分布来建模收入。
前面我们已经看到了如何获得洛伦兹曲线。实际上,也可以针对某些参数分布(例如,一些对数正态分布)获得Lorenz曲线,
> lines(Lc.lognorm,param=1.5,col="red")
> lines(Lc.lognorm,param=1.2,col="red")
> lines(Lc.lognorm,param=.8,col="red") 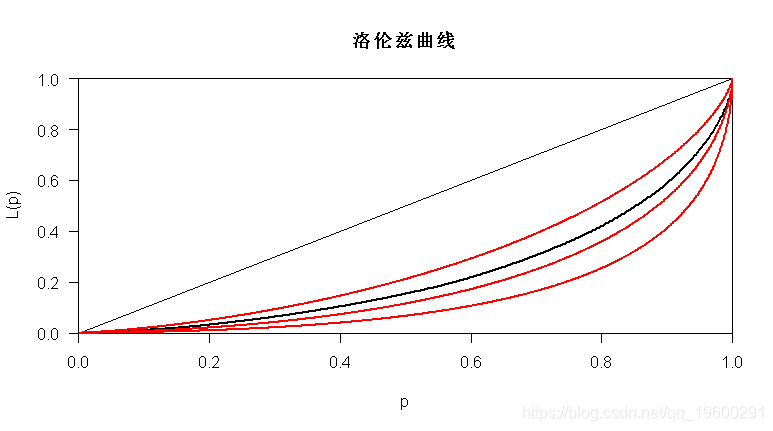
随时关注您喜欢的主题
在这里, 对数正态分布是一个很好的选择。帕累托分布也许不是:
> lines(Lc.pareto,param=1.2,col="red") 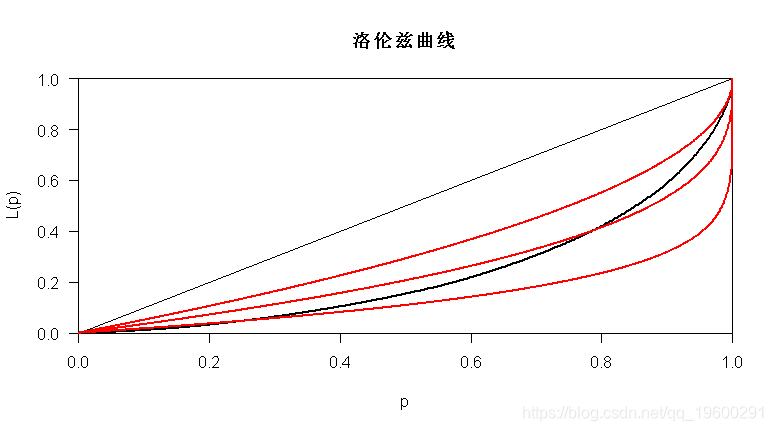
实际上,可以拟合一些参数分布。
shape rate
1.0812757769 0.0140404379
(0.0604530180) (0.0009868055) 现在,考虑两种分布,伽马分布和对数正态分布(适用于极大似然方法)
shape rate
1.0812757769 0.0014040438
(0.0473722529) (0.0000544185)
meanlog sdlog
6.11747519 1.01091329
(0.04520942) (0.03196789) 我们可以可视化密度
> hist(income,breaks=seq(0,2005000,by=5000),
+ col=rgb(0,0,1,.5),border="white",
+ fit_g$estimate[2])/1e2
+ fit_ln$estimate[2])/1e2
> lines(u,v_g,col="red",lwd=2)
> lines(u,v_ln,col=rgb(1,0,0,.4),lwd=2) 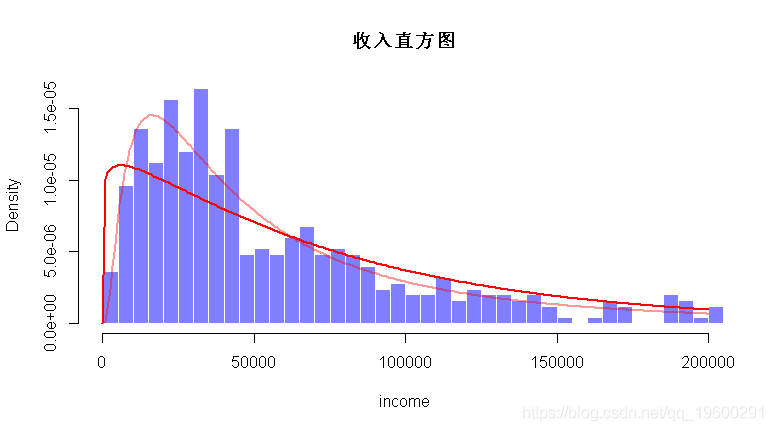
在这里,对数正态似乎是一个不错的选择。我们还可以绘制累积分布函数
`> plot(x,y,type="s",col="black",xlim=c(0,250000))
+ fit_g$estimate[2])
+ fit_ln$estimate[2])
> lines(u,v_g,col="red",lwd=2)`
现在,考虑一些更现实的情况,在这种情况下,我们没有来自调查的样本,但对数据进行了合并,
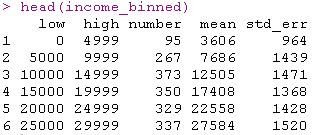
对数据进行建模,
fit(ID=rep("Data",n),
Time difference of 2.101471 secs
for LNO fit across 1 distributions 我们可以拟合对数正态分布(有关该方法的更多详细信息,请参见 从合并收入估算不平等 的方法)
`> y2=N/sum(N)/diff(income_binned$low)
+ fit_LN$parameters[2])
> plot(u,v,col="blue",type="l",lwd=2)
> for(i in 1:(n-1)) rect(income_binned$low[i],0,
+ income_binned$high[i],y2[i],col=rgb(1,0,0,.2),`
在此,在直方图上(由于已对数据进行分箱,因此很自然地绘制直方图),我们可以看到拟合的对数正态分布很好。
> v <- plnorm(u,fit_LN$parameters[1],
+ fit_LN$parameters[2])
> for(i in 1:(n-1)) rect(income_binned$low[i],0,
> for(i in 1:(n-1)) rect(income_binned$low[i],
+ y1[i],income_binned$high[i],c(0,y1)[i], 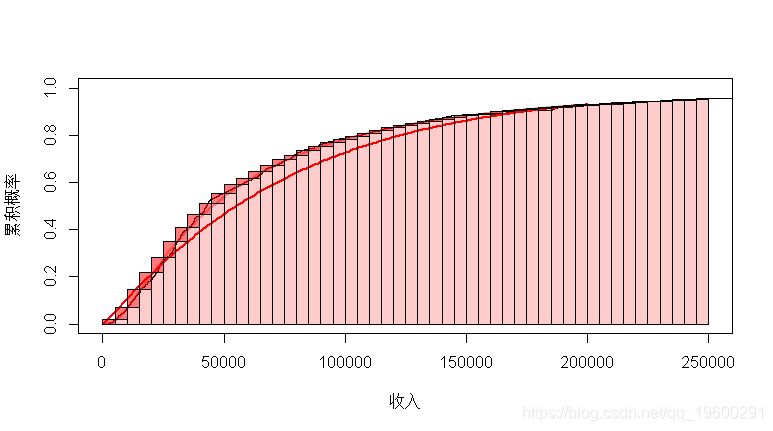
对于累积分布函数,我考虑了最坏的情况(每个人都处于较低的收入中)和最好的情况(每个人都具有最高可能的收入)。
也可以拟合广义beta分布
GB_family(ID=rep("Fake Data",n), 为了获得最佳模型,查看
> fits[,c("gini","aic","bic")] 结果很好,接下来看下真实数据:

fit(ID=rep("US",n),
+ distribution=LNO, distName="LNO"
Time difference of 0.1855791 secs
for LNO fit across 1 distributions同样,我尝试拟合对数正态分布
> v=dlnorm(u,fit_LN$parameters[1],
> plot(u,v,col="blue",type="l",lwd=2)
> for(i in 1:(n-1)) rect(data$low[i],
但是在这里,拟合度很差。同样,我们可以估算广义beta分布
>
GB_family(ID=rep("US",n),
+ ID_name="Country")可以得到基尼指数, AIC 和BIC
gini aic bic
1 4.413431 825368.5 825407.3
2 4.395080 825598.8 825627.9
3 4.451881 825495.7 825524.8
4 4.480850 825881.7 825910.8
5 4.417276 825323.6 825352.7
6 4.922122 832408.2 832427.6
7 4.341036 827065.2 827084.6
8 4.318667 826112.8 826132.2
9 NA 831054.2 831073.6
10 NA NA NA看到最好的分布似乎是 广义伽玛分布。
 R语言用随机森林模型的酒店收入和产量预测误差分析
R语言用随机森林模型的酒店收入和产量预测误差分析 R语言用决策树的酒店收入和产量预测可视化研究
R语言用决策树的酒店收入和产量预测可视化研究 数据分享|R语言回归模型诊断、离群值分析学生考试成绩、病人医护质量满意度、婴儿死亡率和人均收入、针叶树荫面积数据
数据分享|R语言回归模型诊断、离群值分析学生考试成绩、病人医护质量满意度、婴儿死亡率和人均收入、针叶树荫面积数据 R语言股票收益分布一致性检验KS检验Kolmogorov-Smirnov、置换检验Permutation Test可视化
R语言股票收益分布一致性检验KS检验Kolmogorov-Smirnov、置换检验Permutation Test可视化


