本文介绍如何根据历史信号/交易制作股票曲线。
让我们以MARKET TIMING与DECISION MOOSE的历史信号为例,为该策略创建股票曲线。
#*****************************************************************
# 加载信号
#*****************************************************************
# 提取交易历史
temp = extract.table.from.webpage(txt, 'Transaction History', has.header = F)
temp = trim(temp\[-1,2:5\])
colnames(temp) = spl('id,date,name,equity')
tickers = toupper(trim(gsub('\\\)','', sapply(temp\[,'name'\], spl, '\\\('))))\[2,\]
load(file=filename)
#plota(make.xts(info$equity, info$date), type='l')
去年在某些文章里面提到过关于交易系统回测的问题,很多朋友就发出各种质疑:“为什么要回测?直接实盘不行么?”、“回测有啥好处?”,最近提问的人又有很多,今天就专门捋一捋这个问题,为什么我们要回测?回测的意义何在?
关于交易系统的回测,我个人认为有4个重大意义:
1、客观取舍,快速排除:
一天一小悟,一周一大悟,不停地思考、创新、假设,在交易的世界可不是你一个人在干这事,大家都聪明过人,都在追求进步和突破,然而大多数人也只能到这一步,剩下的呢就是想当然地这里试一试、那里摸一摸,三天打鱼两天晒网,亏了3次就觉得这个方法不行,那个技术不靠谱,一定还有更完美的策略,一定还有必赚的绝技。
如果回到多年以前,我和大多数人一样,日思夜想,都找不到交易的出路,什么是趋势?行情波动的规律是什么?突破和回调到底哪个好用?抄底摸顶真的靠谱么?交易盈利的原理是什么?为什么越努力越失败?为什么懂得越多越是混乱?为什么我工作出色事业辉煌却在金融市场一败涂地?各种挫败感如影随形,挥之不去。
因为技术分析有时候有效,有时候失灵,让人捉摸不透、身心疲惫,最后的结果就是每天想当然的换来换去,摇摆不定,自己把自己搞废了,十八般武艺样样不精通,技术学了一大堆,资金跟着缩了水。
这样下去,我们并不能看出某种技术真正的优劣所在,因为没有长期大量的数据证明,仅凭主观的短时间体验,样本太少,根本不能反映一个交易规则的真实效果。就拿1根均线来说,单边的时候赚得起飞,震荡的时候亏到吐血,背后的逻辑原理是什么?有多少人亲自做过实验呢?1天、1周、1个月的效果反馈和1年、10年、20年的效果反馈你觉得哪个更靠谱?如果有人用1根均线在特定的周期和规则下能这个市场长期稳定盈利你信么?
所以90%的交易者在亏1次的时候还能接受,亏3次就想放弃,亏5次就说这个技术是垃圾,刚好第6次来了大行情就会因为踏空而怀疑人生,这样的大有人在,本质上还是对于各种技术的评判过于主观了,缺乏实际行动,缺乏长期且大量的数据检验,以至于短期内完全看不出一种技术、一种规则的真实效果,从而不断发现新大陆看到了希望,然后又快速抛弃而陷入绝望,尴尬地恶性循环,俗称-狗熊掰棒子。
通过回测得出的结论就是,基本上用突破开仓,可以守在行情的必经之路,是趋势的充分且必要条件,只要有行情,就一定有突破,不管是形态突破还是区间突破或者均线突破。
所以回测的第1个意义在于让我们通过实际行动,通过大量回测,去快速验证各种想法、策略、技术是否真的可行;快速检验是否存在逻辑问题;快速做排除法做减法,把没有价值的想法都PASS掉;快速地客观取舍,重新进行组合,从而提高交易系统磨合的效率。
这样那些看上去很美好的技术、策略可能效果真的很烂,反而那些看上去不起眼很粗糙的技术却效果惊人,这就是回测的意义-客观取舍、快速排除。
综上,我们在判断不确定事件发生的概率时,很容易会违背大数定律-大样本的客观判断,而不由自主地使用“小数定律”-小样本的主观判断,造成以偏概全的偏见,滥用典型事件,从而导致自己在追求完美技术的道路上死磕一生,而通过对大量的历史数据的回测,能快速验证一个交易系统、一种开仓规则、一种止损策略、一种出场设计是否合理、是否有效果,从而做排除法。
2、从0到1,快速上手:
通过回测,可以让我们快速了解交易系统的架构,它有哪些环节?各个环节是如何协同工作的?资金管理能起到什么样的作用?资金曲线是怎样的?从而能够快速的看清交易真相,回归交易本质-概率。
基本上这是一个从0到1,从无到有的蜕变过程,当你能够设计出第1个交易系统,那么就能有第2个、第3个、第N个……然后触类旁通,举一反三,可以演变出适合自己个性需求的交易系统。
比如你追求高胜率应该怎么办?追求高赔率应该调整哪些环节?追求低回撤应该如何优化?追求收益要不要加仓?这些问题当你在熟练的掌握各种环节的基础上才能迎刃而解,那么在技术分析的交易道路上不会再存在什么盲点了。
所以,如果没有回测,很多人一生都无法上手,无法入门,这1步将会是交易路上的重要里程碑,好比我们小时候学骑自行车一样,从有人扶到没人扶;从踩半圈到整圈,从骑出去1米到100米,意义重大。
3、心中有数,面对亏损:
通过回测你才有可能彻底承认走势的不确定性和不可预测性,你才能悟到技术分析的本质就是赌概率,而不是神仙算命。另外,通过对各种交易系统的回测,一个交易模型的回测数据可以反映出整体效果,比如胜率、赔率、频率、回撤、总收益、连续亏损等等,都能看出来,对于一种开仓技术、一种止损规则、一种出场设计、一套交易系统的整体效果,优劣利弊自然清晰,不会过于纠结一时的得失和短暂的失利,而是眼光看得更远。
哪怕遇到连续亏损也不会慌里慌张,因为在过去的5-20年的历史回测中你自然会经历这种情况,最极端的情况是什么,心中有数,到了警戒线自然会警觉,在可承受范围以内则一切视为常态。比如我过去回测的某个周期某个品种最大连续亏损为10次,那么现在经常连续亏5次、6次则非常正常,如果单品种连续亏损超过10次我则会查找原因,看哪里出了问题,是否要停下来还是继续?此为心中有数。
4、心里有底,坚定信念:
并不是所有的交易系统都能赚钱,也并不是所有的周期和品种都能赚钱,所以通过回测,可以让我们对不同的交易系统进行评估取舍,它适应能力如何?长期是否是正期望值?适合哪些周期和品种?失效是短暂的还是长期的?策略失效还是品种死亡如何判断?缺陷在哪里?实盘用哪个?
有了回测数据论证,选择和坚持就不会过于纠结了,从而可以更加坚定自己的信念,加强对交易系统的信任。因为我知道,只要我这么重复下去,一定是必赚,只是赚多赚少而已。
因此,回测的第4个意义对我来说就是让我心里有底,坚定信念,不会经常性地杞人忧天,给自己制造假想敌,给自己设置原本都没有发生的各种障碍。
最后简单说下常见的回测方式:
①有条件的编程:
期货常用的回测软件有金字塔、开拓者、文华8,对应的语言不同,入门难度也不同,优点是回测检验速度快,缺点是门槛高,一般人无法快速上手,需要自己钻研或者找专业人士编写,策略越复杂难度越大,另外一些重大缺陷不一定能看得出来,可能存在过度优化的问题。
②没条件的手动:
没有编程条件的只能自己手动记录每一笔交易的情况,优点是笨鸟先飞,勤能补拙,虽然慢一点,但是对交易规则会更加熟练,一些细节问题和重大隐患能感知出来,缺点是速度太慢,如果回测周期太小则数据庞大或者找数据困难,最主要是比较费眼睛。
在我看来,回测是检验一切幻想是否真实可行的重要标准,不过回测也并不能万能神药,只能解决基础问题-交易系统的构建,不能解决逻辑问题,不能保证每个交易系统都是正期望,不能解决实盘中的滑点、中断交易、执行力等问题,所以不能保证实盘稳赚。
还要注意一个回测陷阱-过度优化,有些人在回测中会刻意避开某些震荡期,刻意在更好的地方去平仓,缺乏一致性和连贯性,这些做法并不可取,会导致在实盘交易的时候效果会严重缩水。
风险提示:以上内容仅供交流探讨,不作为实际操作意见,据此交易盈亏自负。
#*****************************************************************
# 加载历史数据
#*****************************************************************
tickers = unique(info$tickers)
# 加载保存的代理原始数据
load('data/data.proxy.raw.Rdata')
# 定义现金
tickers = gsub('3MOT','3MOT=BIL+TB3M', tickers)
#飞毛腿新亚洲基金(SAF),并入DWS新兴市场股票基金
tickers = gsub('SAF','SAF=SEKCX', tickers)
#添加虚拟股票,以保持交易日期,如果它们与数据不一致的话
dummy = make.stock.xts(make.xts(info$equity, info$date))
getSymbols.extra(tickers, src = 'yahoo', from = '1970-01-01', env = data, raw.data = data.proxy.raw, auto.assign = T)
# 可选择未被Adjusted捕获的分叉点
#data.clean(data, min.ratio=3)
for(i in ls(data)) data\[\[i\]\] = adjustOHLC(data\[\[i\]\], use.Adjusted=T)
#print(bt.start.dates(data))
data$dummy = dummy
#*****************************************************************
# 设置
#*****************************************************************
prices = data$prices
models = list()
#*****************************************************************
#代码策略,SPY - 买入和持有
#*****************************************************************
data$weight\[\] = NA
data$weight$SPY = 1
models$SPY = bt.run.share(data, clean.signal=T, silent=T)
#*****************************************************************
# 创建权重
#*****************************************************************
weight = NA * prices
for(t in 1:nrow(info)) {
weight\[info$date\[t\],\] = 0
weight\[info$date\[t\], info$ticker\[t\]\] = 1
}
#*****************************************************************
#创建报告
#******************************************************************
plota.matplot(scale.one(data$prices),main='Asset Perfromance')
plot(models, plotX = T)
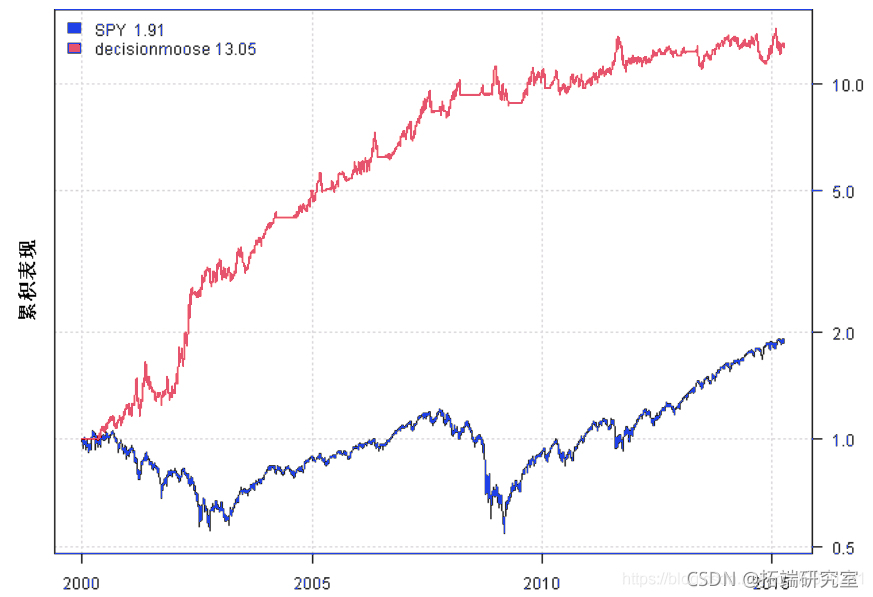
print(plotbt))


m = 'decisionmoose' plotbmap(models\[\[m\]\]$weight, name=m)
随时关注您喜欢的主题

 R语言神经网络模型金融应用预测上证指数时间序列可视化
R语言神经网络模型金融应用预测上证指数时间序列可视化 SPSS modeler利用类神经网络对茅台股价涨跌幅度进行预测
SPSS modeler利用类神经网络对茅台股价涨跌幅度进行预测 Python随机波动模型Stochastic volatility,SV随机变分推断SVI分析标普500指数股票价格时间序列数据波动性可视化
Python随机波动模型Stochastic volatility,SV随机变分推断SVI分析标普500指数股票价格时间序列数据波动性可视化 Python用GARCH对ADBL股票价格时间序列趋势滚动预测、损失、可视化分析
Python用GARCH对ADBL股票价格时间序列趋势滚动预测、损失、可视化分析


