
假设调查人员有兴趣检查减肥干预方法的三个组成部分。
这三个组成部分是:
- 记录食物日记(是/否)
- 增加活动(是/否)
- 家访(是/否)
调查员计划调查所有 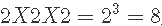 ,实验条件的组合。实验条件为
,实验条件的组合。实验条件为
- 要执行因子设计,您需要为多个因子(变量)中的每一个选择固定数量的水平,然后以所有可能的组合运行实验。
- 这些因素可以是定量的或定性的。
- 定量变量的两个水平可以是两个不同的温度或两个不同的浓度。
- 定性因素可能是两种类型的催化剂或某些实体的存在和不存在。
符号 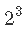 : – 因子数 (3) – 每个因子的水平数 (2) – 设计中有多少实验条件 (
: – 因子数 (3) – 每个因子的水平数 (2) – 设计中有多少实验条件 (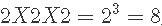 )
)
因子实验可以涉及具有不同水平数量的因子。

测试:
考虑一个 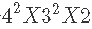 设计。
设计。
- 有多少因素?
- 每个因素有多少个水平?
- 多少实验条件(运行)?
答案:
(a) 有 2+2+1 = 5 个因数。
(b) 两个因素有4个水平,2个因素有3个水平,1个因素有2个水平。
(c) 有 288 个实验条件。
方差分析和因子设计之间的区别
在 ANOVA 中,目标是比较各个实验条件。
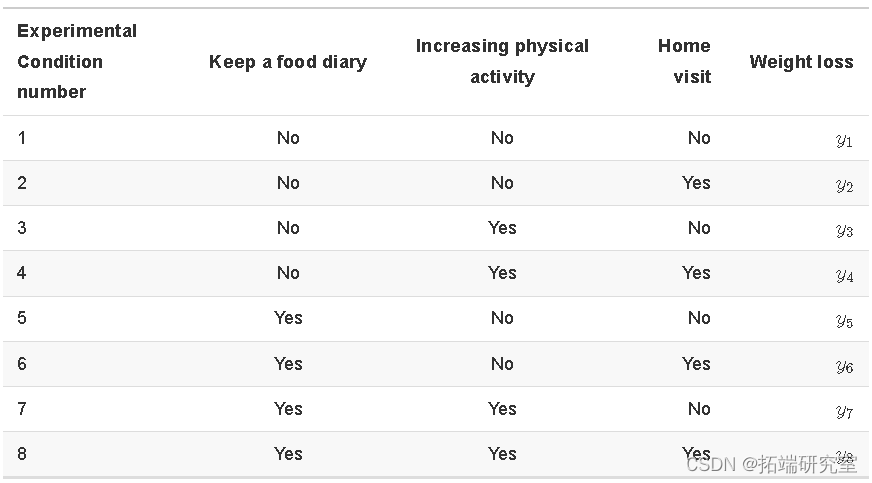
让我们考虑一下上面的食物日记研究。
我们可以通过比较食物日记设置为 NO(条件 1-4)的所有条件的平均值和食物日记设置为 YES(条件 5-8)的所有条件的平均值来估计食物日记的效应。这也被称为食物日记的 主效应 ,形容词 主要 是提醒这个平均值超过了其他因素的水平。
食物日记的主要作用是:
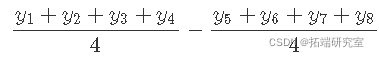
体育锻炼的主要作用是:
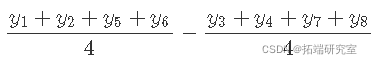
家访的主要作用是:
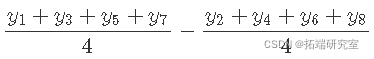

使用了所有实验对象,但重新排列以进行每次比较。受试者被回收以测量不同的效应。这是析因实验更有效的原因之一。
执行 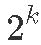 因子设计
因子设计
要执行因子设计:
- 为每个因子选择固定数量的水平。
- 以所有可能的组合运行实验。
我们将讨论每个因子只有两个水平的设计。因素可以是定量的或定性的。两个水平的定量变量可以是两个不同的温度或浓度。定量变量的两个级别可以是两种不同类型的催化剂或某些实体的存在/不存在。
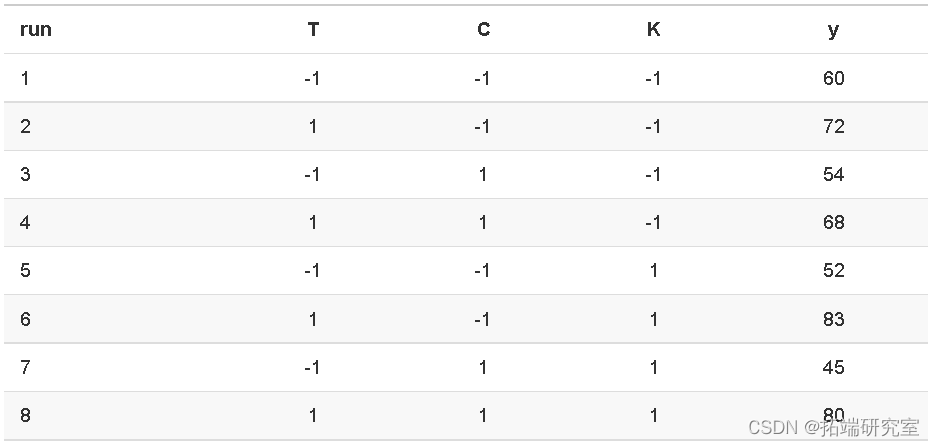
一项实验采用 2^3 因子设计,具有两个定量因素 – 温度 (T) 和浓度 (C) – 以及一个定性因素 – 催化剂 K 类型。
温度T(C∘)有两个等级:160C∘和180C∘。它们分别编码为 -1 和 +1。
浓度 C (%) 有两个级别:20 和 40。它们分别编码为 -1 和 +1。
催化剂 K 有两个级别:A 和 B。它们分别编码为 -1 和 +1。
记录的每个数据值都是针对两次重复运行的平均因变量产量 y。
随时关注您喜欢的主题
立方图
下图显示了立方体角处因子 T、C 和 K 的各种组合的 y 值。例如,当 T=-1、C = 1 和 K=-1 时,从运行 3 获得 y=54。
- 立方体展示了这种设计如何沿着立方体的 12 个边缘进行 12 次比较:温度变化影响的四个测量值;浓度变化影响的四种测量方法;催化剂变化效应的四种测量方法。
- 在立方体的每条边上,只有一个因子发生变化,而其他两个因子保持不变。
bh4 <- lm
Plot
因子效应
主要影响
运行 1 和 2 的影响仅因温度而不同,因为浓度为 20%,催化剂类型为 A。差异 72-60 = 12 提供了一种温度影响的测量值,而其余因素保持不变。对于浓度和催化剂的四种组合中的每一种,有四种这样的温度效应测量方法。

T 的主要(平均)影响是
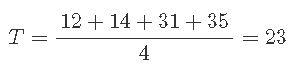
有一组类似的浓度 C 测量值。在这些测量值中的每一个中,水平 T 和 K 都保持不变。浓度 C 的主要影响是:

C的主要(平均)影响是

K 的主要影响是
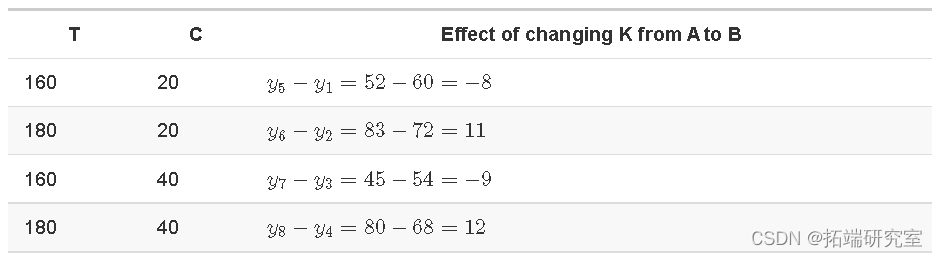
K 的主要(平均)影响是
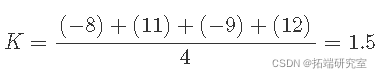
所有 8 次运行都用于估计每个主效应。这就是因子设计比一次检查一个因子更有效的原因。
一般来说,主要影响是两个平均值之间的差异:
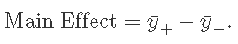
其中 ¯y+ 是对应于因子 +1 水平的平均响应,而 ¯y− 是对应于因子 -1 水平的平均响应。
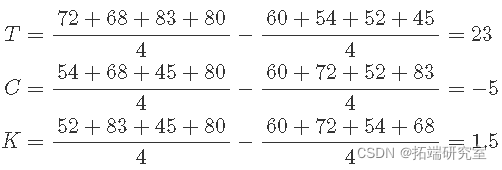
交互效应
两因素相互作用
当催化剂 K 为 A 时,温度效应为:
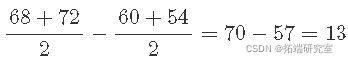
当催化剂 K 为 B 时,温度效应为:
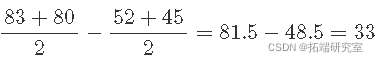
这两个平均差异之间的平均差异称为温度和催化剂之间的 相互作用 ,用 TK 表示。这就是温度和催化剂两个因素之间的相互作用——温度和催化剂之间的两个因素相互作用。
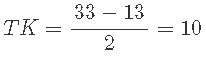
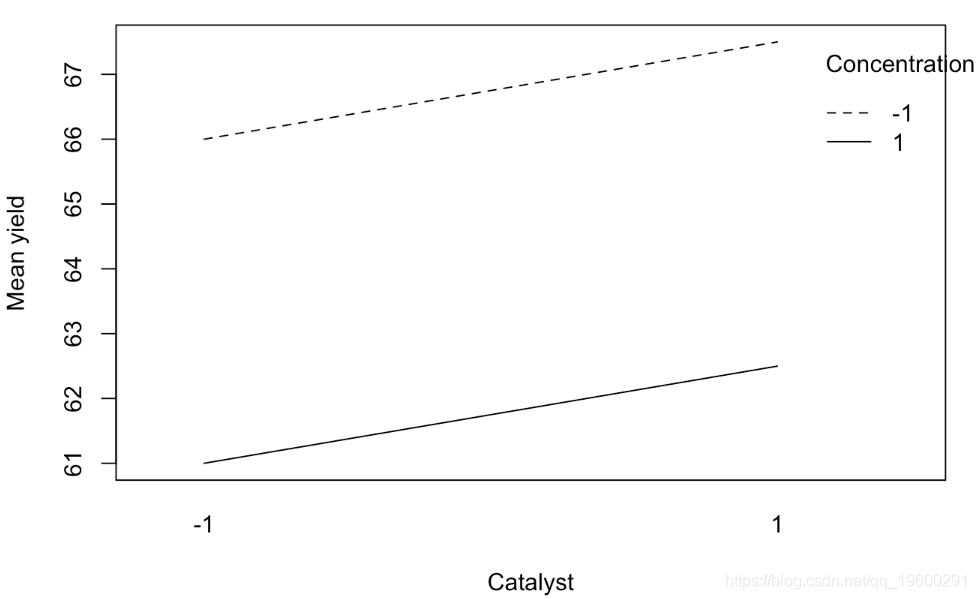
这也可以在立方图上看到:与立方体正面 (13) 相比,立方体 (33) 背面的平均温度影响更大。
三因素相互作用
当催化剂为 B(在其 +1 水平)时,浓度相互作用的温度为:

当催化剂为 A(在其 -1 水平)时,浓度相互作用的温度为:

这两种相互作用之间的差异衡量了两种催化剂的温度-浓度相互作用的一致性。这种差异的一半被定义为温度、浓度和催化剂的三因素相互作用,用 TCK 表示。
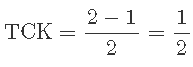
因子设计中的复制
工厂实验的结果 y是两次重复运行的平均值。两个单独的运行如下表所示。运行顺序是随机的。例如,运行 6 和 13 是 T、C 和 K(T=-1、C=-1、K=-1)的相同设置下的两个仿行。
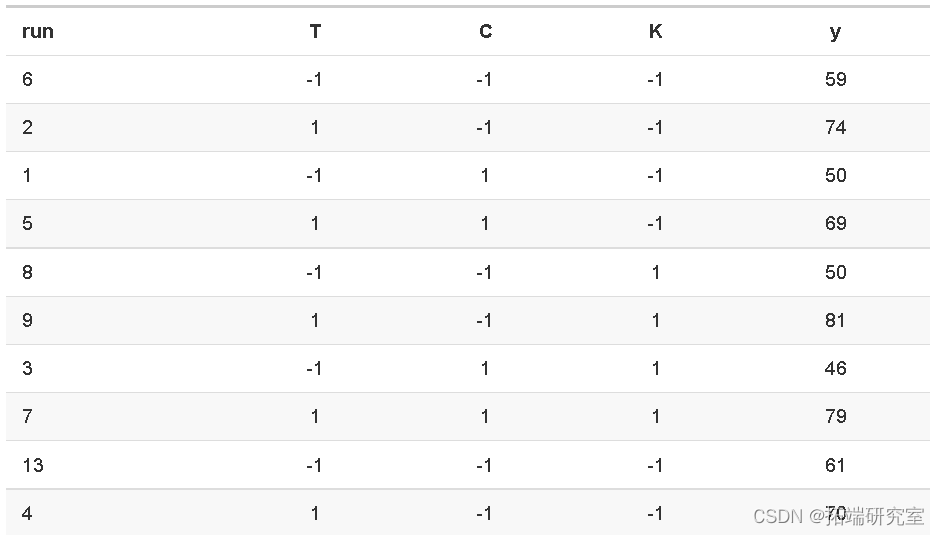
复制运行并不总是可行的。工厂实验运行包括清洁反应器,插入适当的催化剂装料,并在给定的进料浓度下在给定的温度下运行设备 3 小时,以使过程在所选的实验条件下稳定下来,以及 (4) 取样在运行的最后几个小时内每 15 分钟输出一次。
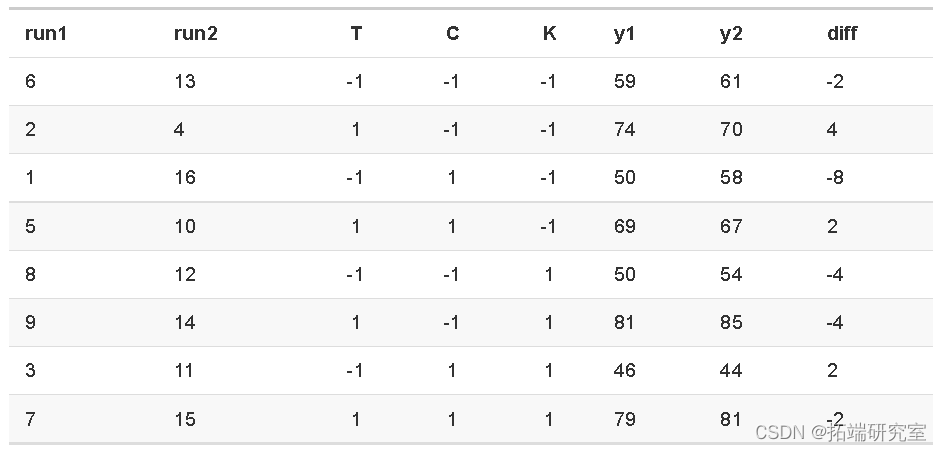
假设每次测量的方差为 σ2。每组条件下的估计方差为:
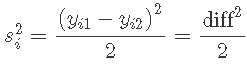
其中 yi1 是第 i 次运行的第一个结果。在上表中diffi=(yi1−yi2)。σ2 的汇总估计是
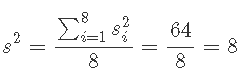
对于重复运行,具有一个自由度的方差估计为 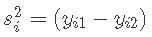 . 这些产生单自由度估计的平均值产生具有 8 个自由度的合并估计 s2=8。
. 这些产生单自由度估计的平均值产生具有 8 个自由度的合并估计 s2=8。
重复运行效应的误差方差和标准误差的估计
每个估计的效应,例如 T、C、K、TC 等,都是 8 个观测值的两个平均值之间的差异。重复运行的因子效应方差为

因此,任何因子效应的标准误为:
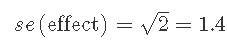
结果解释
哪些影响是真实的,哪些可以偶然解释?一个粗略的经验法则是,任何 2-3 倍于其标准误差的效应都不容易仅靠偶然性来解释。
如果我们假设观测值是独立且正态分布的,那么
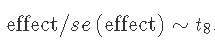
因此,95% 的置信区间可以计算为:
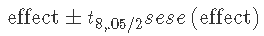
其中 t8,.05/2 是 t8t 的第 97.5 个百分位数。这是通过 qt() 函数在 R 中获得的。
qt(p = 1-.025,df = 8)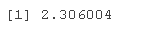
因此,因子效应的 95% 置信区间为
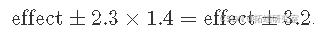
T 的 95% 置信区间为
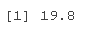
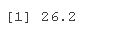
K 的 95% 置信区间为
1.5-3.2 #下限## \[1\] -1.71.5+3.2 #上限## \[1\] 4.7温度的影响可能不是偶然的,但偶然不能成为催化剂的影响的规则。
只有在没有证据表明该因素与其他因素相互作用时,才应单独解释一个因素的主效应。
交互图
下图显示了每对因子 TC、TK、CK(即这些因子的每个因子水平组合)的平均产量。这些图通常称为交互图。如果两条线平行,则表明没有相互作用,如果两条线交叉或接近交叉,则表明可能存在相互作用。
下图显示了催化剂和温度之间的双向相互作用。
plot(tabT,taC,ty, type = "l")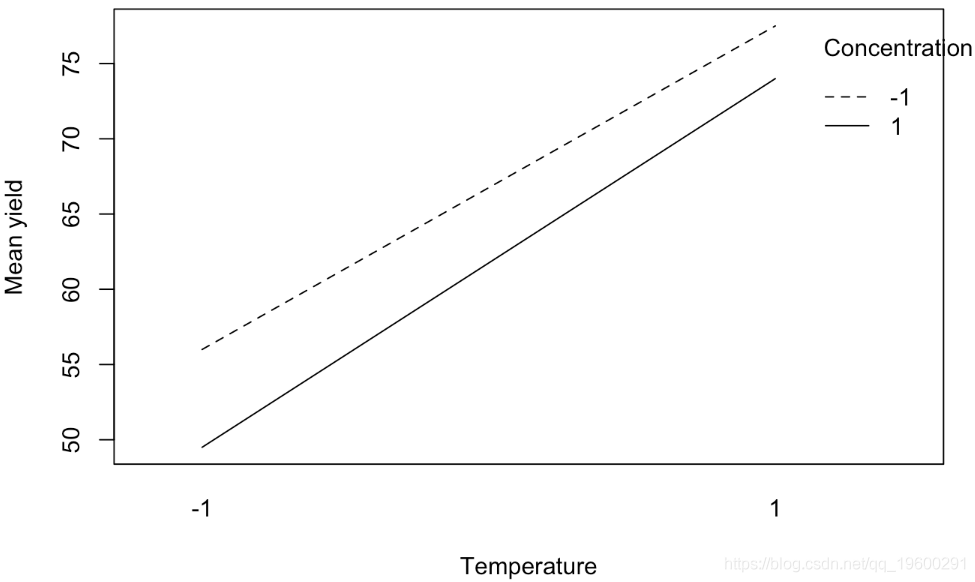

2k 因子设计的线性模型
yi 是第 i 次运行的结果,

2^3 因子设计的线性模型是:
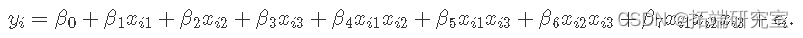
变量 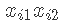 是温度和浓度之间的相互作用,xi1xi3xi1xi3 是温度和催化剂之间的相互作用等。
是温度和浓度之间的相互作用,xi1xi3xi1xi3 是温度和催化剂之间的相互作用等。
参数估计是通过 lm() R 中的函数获得的。
fact.mod <-lm(y~T\*K\*C,data = tab0503)
round(summary(fact.mod)$coefficients,2)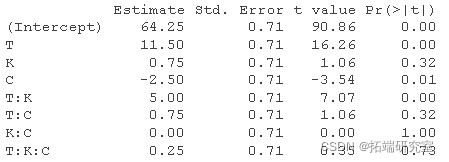
设计矩阵 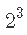 设计是:
设计是:
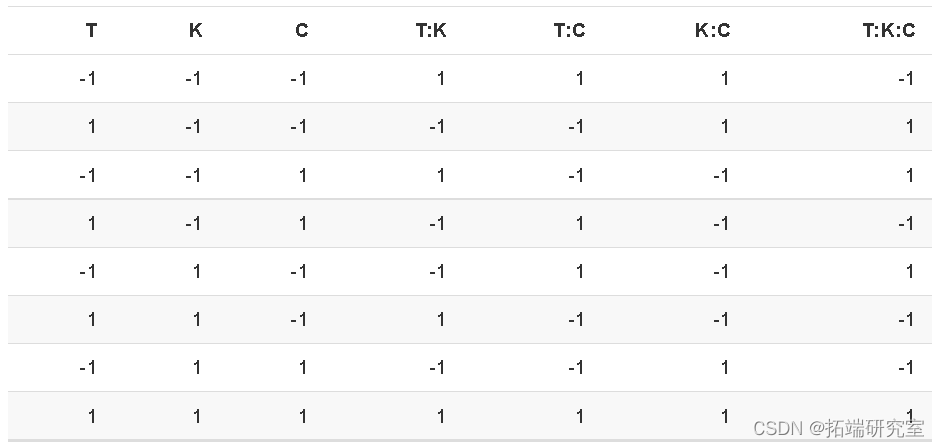
这个模型矩阵 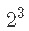 设计是:
设计是:
model.matr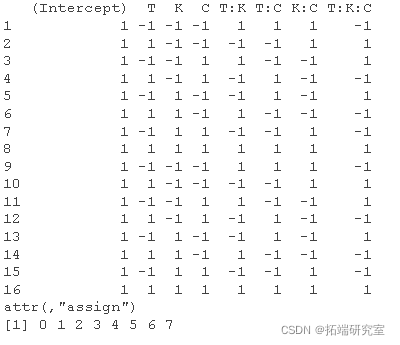
下表显示了具有因变量的模型矩阵:
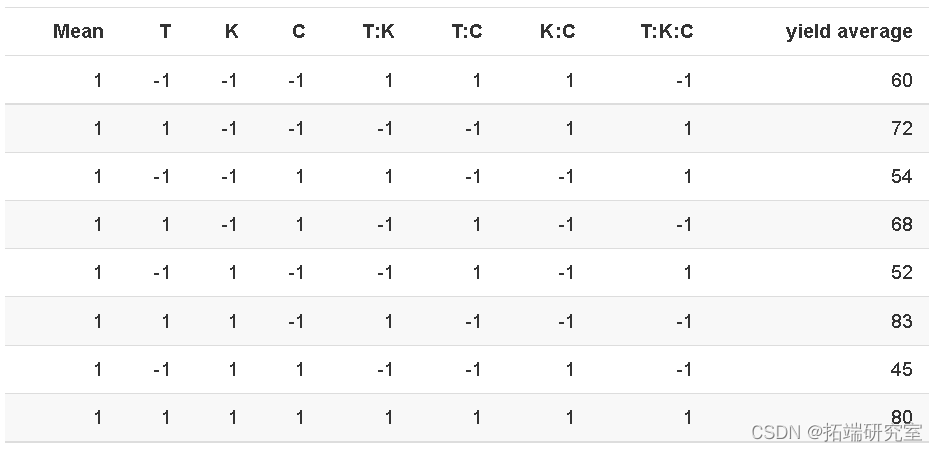
如果将 T 的列乘以平均收益率并除以 4,则得到 T 的主效应。
估计的最小二乘系数是因子估计的二分之一,截距 β0 是样本均值。因此,因子估计是最小二乘系数的两倍。例如,
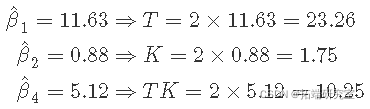
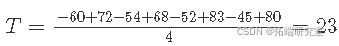
- 4 的除数将对比度转换为两个平均值之间的差异。
- 通过乘以各自因素的标识获得交互作用对比。
- 每列相对于其他列完全平衡(正数和负数相等)。
- 平衡(正交)设计确保每个估计的效应不受其他效应的大小的影响。
最小二乘估计可以在 R 中乘以 2。
fad <-lm
round(2*coeffits,2)
当有重复运行时,我们还从回归模型中获得因子效应的 p 值和置信区间。例如,β1 的 p 值对应于温度的阶乘效应
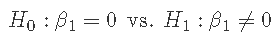
如果原假设为真,那么 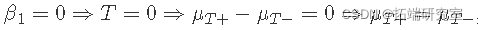
为了获得因子效应的 95% 置信区间,我们将回归参数的 95% 置信区间乘以 2。这在 R 中使用函数 很容易做到 confint()。
2*confint.lm
浓度主效应的 95% 置信区间为 (-8.0,-1.5),温度和浓度之间的双向交互作用具有 95% 置信区间 (-1.46,4.96)。
因子设计相对于一次一个因子设计的优势
假设一次只研究一个因素。例如,在将浓度保持在 20% (-1) 并将催化剂保持在 B (+1) 时研究温度。
为了使效应具有更普遍的相关性,有必要使效应在所有其他浓度和催化剂水平上都相同。换句话说,因素(例如,温度和催化剂)之间没有相互作用。如果效应相同,则因子设计更有效,因为效应的估计需要更少的观察来达到相同的精度。
如果在其他浓度和催化剂水平下效应不同,则阶乘可以检测和估计相互作用。
非重复因子设计中的正态图
回顾正态分位数图
一组数据的正态性可以通过以下方法来评估。让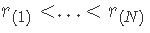 表示的有序值
表示的有序值  . 例如,r(1) 是 r1,…,rN 的最小值,r(N) 是 r1,…,rN 的最大值。所以,如果数据是:-1, 2, -10, 20, 那么
. 例如,r(1) 是 r1,…,rN 的最小值,r(N) 是 r1,…,rN 的最大值。所以,如果数据是:-1, 2, -10, 20, 那么 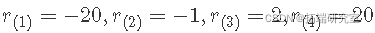 。
。
N(0,1)的累积分布函数 (CDF) 具有 S 形。
x <- seq
plot(x,pnorm)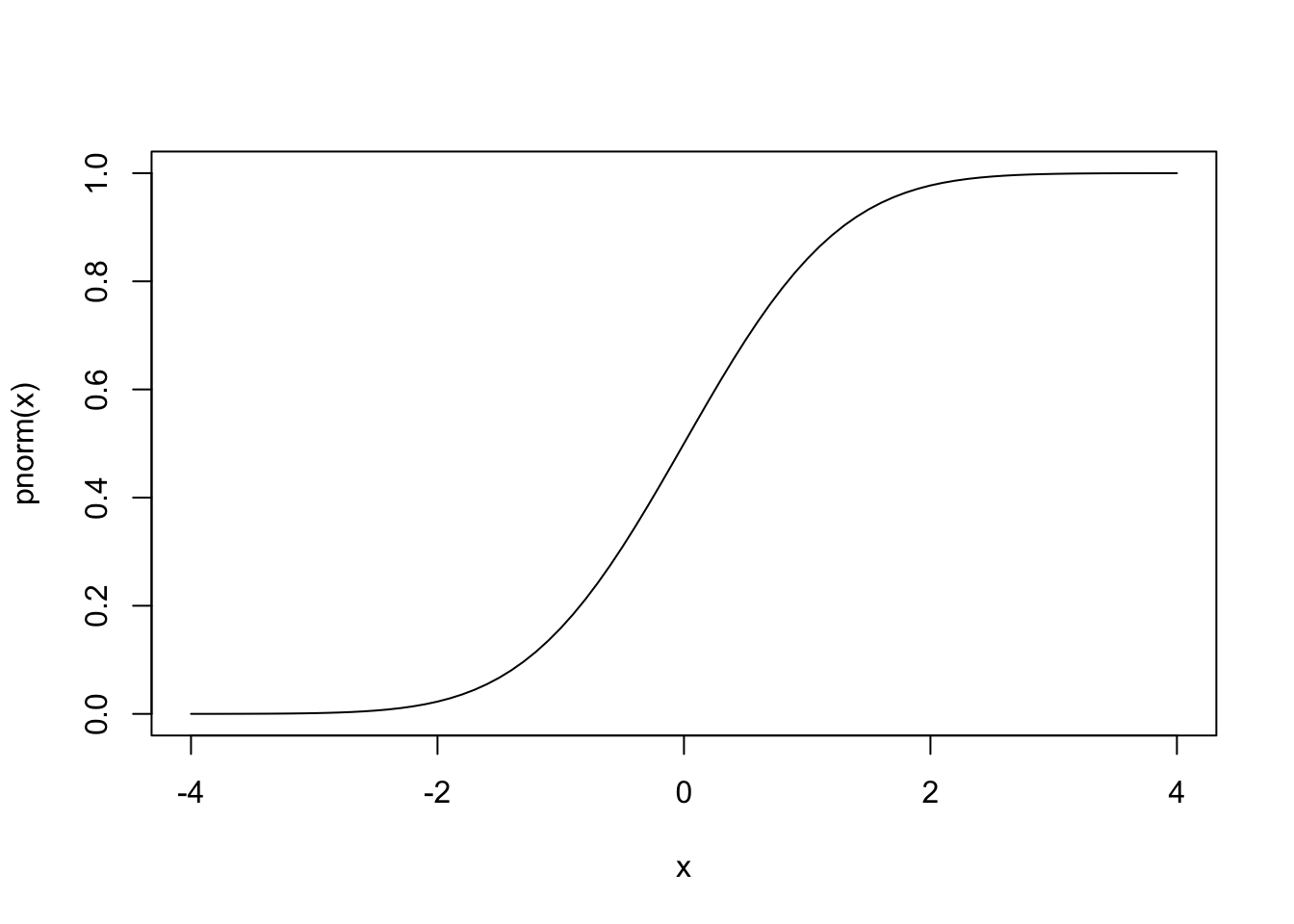
因此,一组数据的正态性检验是绘制数据的有序值 r(i) 与 pi=(i-0.5)/N 的关系。如果该图与正态 CDF 具有相同的 S 形,则这表明数据来自正态分布。
下面是从图中模拟的 1000 个随机样本的 r(i) 与 pi=(i−0.5)/N,i=1,…,N 的关系图
N <- 1000
x <- rnorm(N)
p <- ((1:N)-0.5)/N
plot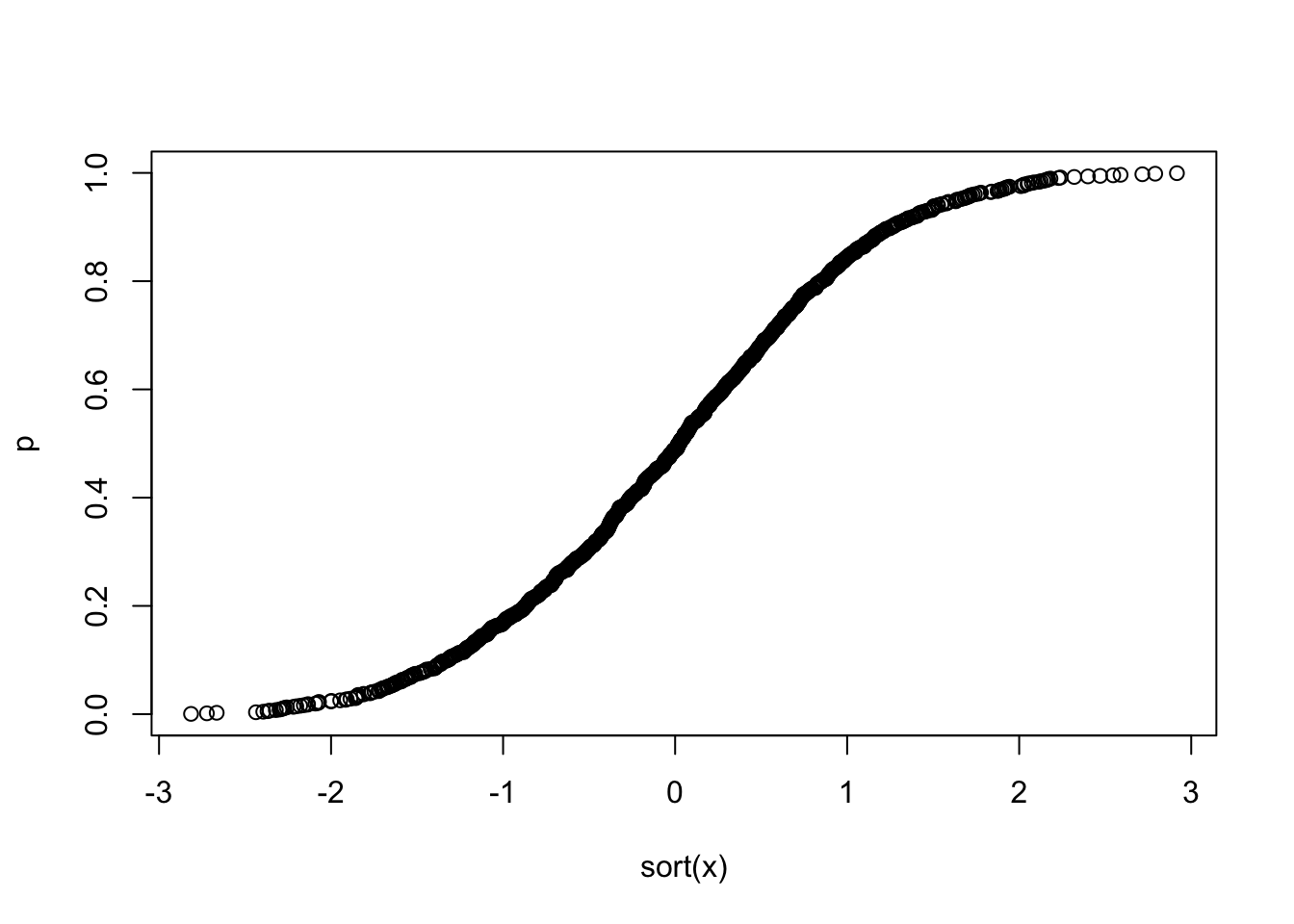
我们还可以构建一个正态的分位数-分位数图。可以证明 Φ(r(i))Φ(r(i)) 在 [0,1] 上具有均匀分布。这意味着 E(Φ(r(i)))=i/(N+1)(这是来自 [0,1] 上的均匀分布的第 i 阶统计量的期望值。
这意味着 N 点 (pi,Φ(r(i))) 应该落在一条直线上。现在将 Φ−1 变换应用于水平和垂直尺度。N个点
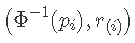
形成正态概率图  . 如果
. 如果  是从正态分布生成的,然后是点图
是从正态分布生成的,然后是点图 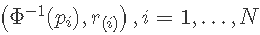 应该是一条直线。
应该是一条直线。
在 R qnorm() 中是 Φ-1。
plot(qnorm(p),sort(x))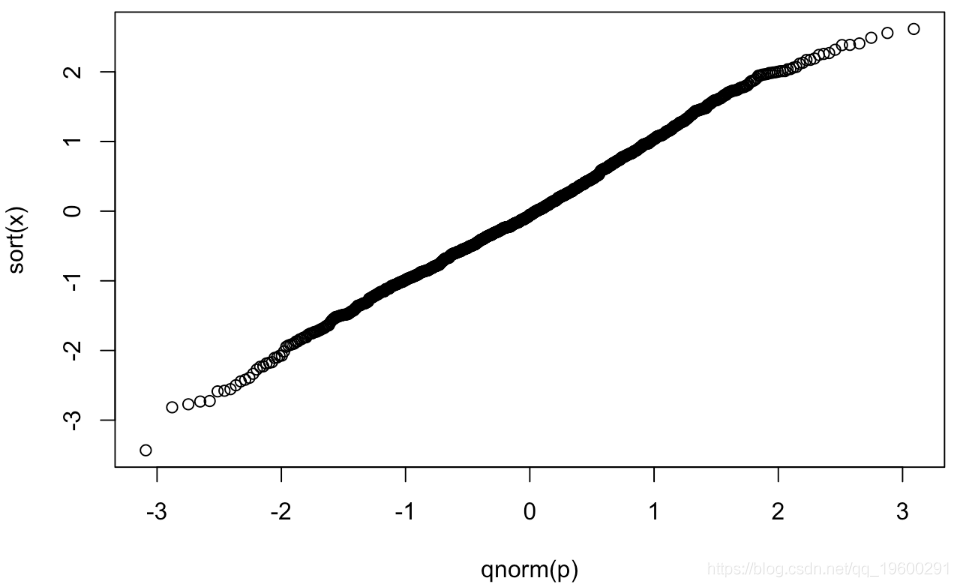
我们通常使用内置函数 qqnorm() (并 qqline() 添加一条直线进行比较)来生成 QQ 图。请注意,R 使用稍微更通用的分位数版本 (pi=(1−a)/(N+(1−a)−a),其中 a=3/8,如果 N≤10,a=1/2,如果N>10。
qqnorm(x);qqline(x)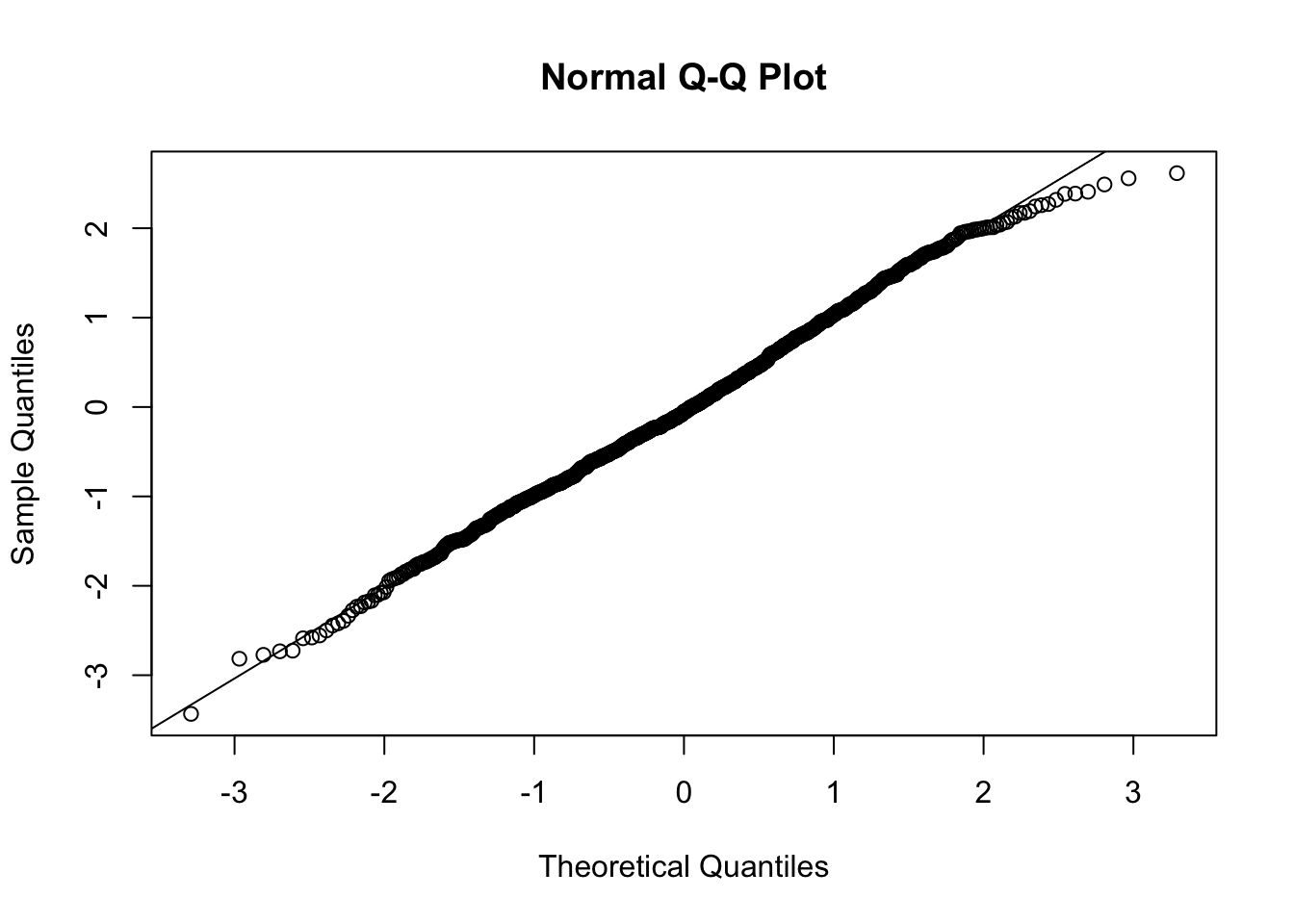
该图与直线的显着(系统性)偏差表明:
- 正态假设不成立。
- 方差不是恒定的。
一个主要应用是在因子设计中,其中 r(i) 被有序因子效应代替。设 ^θ(1)<^θ(2)<⋯<^θ(N) 为 N 个有序因子估计。如果我们绘制
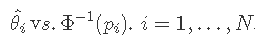
那么接近 0 的阶乘效应 ^θi 将沿直线下降。因此,偏离直线的点将被宣布为重要点。
基本原理如下: 1. 假设估计效应 ^θi 为 N(θ,σ)(估计效应涉及 N 个观测值的平均值,CLT 确保 N 小至 8 的平均值接近正态)。2. 如果 H0:θi=0,i=1,…,N 为真,那么所有估计的影响都将为零。3. 估计效应的结果正态概率图将是一条直线。4. 因此,正态概率图是检验所有估计的效应是否具有相同的分布(即相同的均值)。
- 当一些效应不为零时,相应的估计效应将趋于更大并偏离直线。
- 对于正面影响,估计的影响落在该线之上,而负面影响落在该线之下。
示例 – 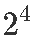 研究化学反应的设计
研究化学反应的设计
一个工艺开发实验研究了四个因素 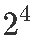 因子设计:催化剂装料量 1、温度 2、压力 3和其中一种反应物的浓度 4。因变量 y 是 16 个运行条件中每个条件下的转化百分比。该设计如下图所示。
因子设计:催化剂装料量 1、温度 2、压力 3和其中一种反应物的浓度 4。因变量 y 是 16 个运行条件中每个条件下的转化百分比。该设计如下图所示。
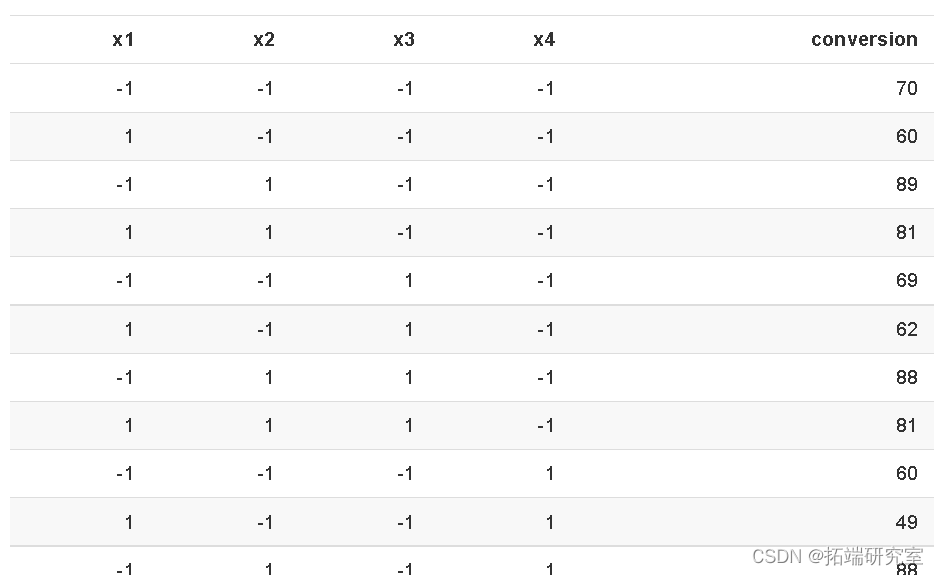
该设计未重复,因此无法估计因子效应的标准误差。
fct1 <- lm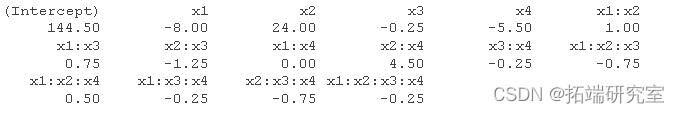
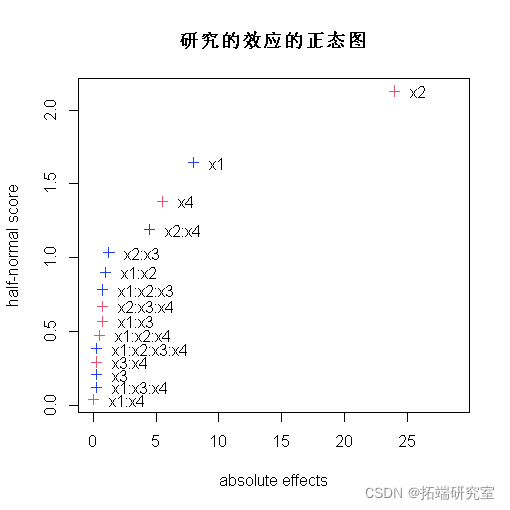
可以获得因子效应的正态图 。
Plot(fac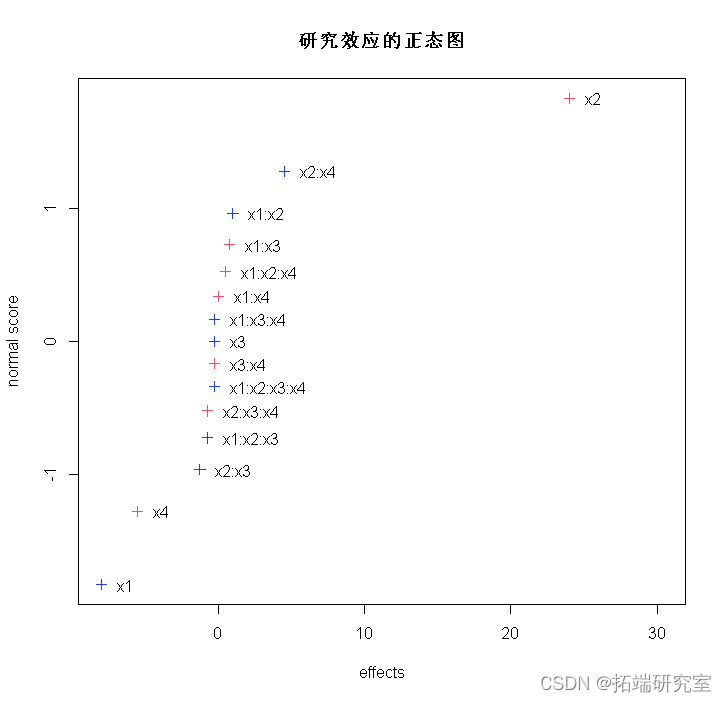
对应的效应 x1, x4, x2:x4, x2 不会沿着直线下降。
半正态图
相关的图形方法称为半正态概率图。让
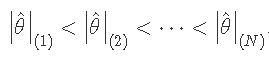
表示无标识因子效应估计的有序值。
根据半正态分布的坐标绘制它们 – 正态随机变量的绝对值具有半正态分布。
半正态概率图由点组成
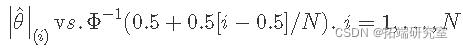
该图的一个优点是所有较大的估计效应都出现在右上角并落在该线之上。
可以获得过程开发示例中效应的半正态图half = TRUE。
Lenth 方法:检验没有方差估计的实验的显着性
半正态图和正态图是涉及视觉判断的非正式图形方法。最好根据正式的显着性检验来定量地判断与直线的偏差。
在 2k 设计 N=2k-1 中估计 θ1,θ2,…,θN 的因子效应。假设所有因子效应具有相同的标准差。
伪标准误差 (PSE) 定义为
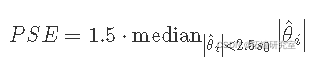
其中中位数是在 ∣∣^θi∣ 中计算的 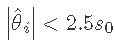 和
和
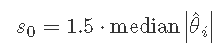
估计的因子效应为:
ef <- 2*fat1$coeffic
s0=1.5⋅median∣∣^θi∣∣的估计是
s0 <- 1.5*median(abs(eff))
s0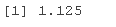
修整常数 2.5s0 是
2.5*s0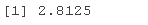
∣∣^θi∣∣≥2.5s0 的效应 ^θi 将被修剪。下面是标记为 TRUE ( x1,x2,x4,x2:x4)的效应
abs(eff)<2.5*s0
然后将 PSE 计算为这些值中位数的 1.5 倍。
PE <- 1.5*median
PE
ME 和 SME 是
ME <- PE*qt
ME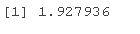
PE*qt(p =(1+.95^{1/15})/2,df=(16-1)/3)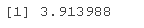
因此,效应的 95% 置信区间为:
lor <- round(ef-ME,2)
uper <- round(ef+ME,2)
kable(cbind)
具有 ME和 SME 的效应图通常称为 Lenth 图。PSE,ME,SMEPSE,ME,SME 的值是输出的一部分。下图中的尖峰用于显示因子效应。
Plot(fat1,cex.fac = 0.5)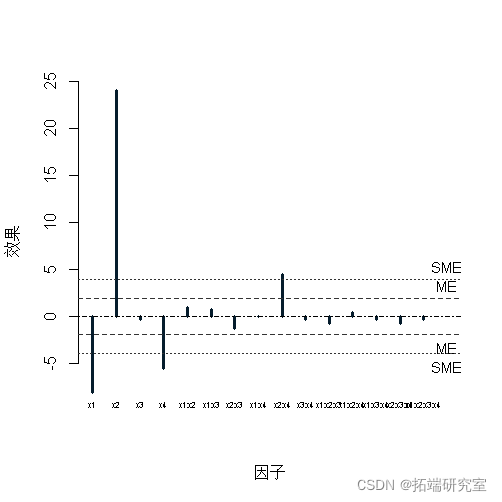

该选项 cex.fac = 0.5 调整用于因子标签的字符大小。
 R语言汇率、股价指数与GARCH模型分析:格兰杰因果检验、脉冲响应与预测可视化
R语言汇率、股价指数与GARCH模型分析:格兰杰因果检验、脉冲响应与预测可视化 R语言分析糖尿病数据:多元线性模型、MANOVA、决策树、典型判别分析、HE图、Box’s M检验可视化
R语言分析糖尿病数据:多元线性模型、MANOVA、决策树、典型判别分析、HE图、Box’s M检验可视化 R语言GJR-GARCH和GARCH波动率预测普尔指数时间序列和Mincer Zarnowitz回归、DM检验、JB检验
R语言GJR-GARCH和GARCH波动率预测普尔指数时间序列和Mincer Zarnowitz回归、DM检验、JB检验


