在这篇文章中,我们讨论了基于gensim 包来可视化主题模型 (LDA) 的输出和结果的技术 。
我们遵循结构化的工作流程,基于潜在狄利克雷分配 (LDA) 算法构建了一个主题模型。
在这篇文章中,我们将使用主题模型,探索多种策略以使用matplotlib 绘图有效地可视化结果 。
可下载资源
介绍
我将使用 20 个新闻组数据集的一部分,因为重点更多地放在可视化结果的方法上。
让我们从导入包和 20 News Groups 数据集开始。
PCA的局限性
PCA是一种线性算法,它不能解释特征之间的复杂多项式关系。而t-SNE是基于在邻域图上随机游走的概率分布来找到数据内的结构。
线性降维算法的一个主要问题是不相似的数据点放置在较低维度表示为相距甚远。但为了在低维度用非线性流形表示高维数据,相似数据点必须表示为非常靠近,这不是线性降维算法所能做的。
t-SNE实际上是做什么?
t-SNE非线性降维算法通过基于具有多个特征的数据点的相似性识别观察到的簇来在数据中找到模式。本质上是一种降维和可视化技术。另外t-SNE的输出可以作为其他分类算法的输入特征。
t-SNE与其他降维算法相比
基于所实现的精度,将t-SNE与PCA和其他线性降维模型相比,结果表明t-SNE能够提供更好的结果。这是因为算法定义了数据的局部和全部结构之间的软边界。
import matplotlib.pyplot as plt
# NLTK停止词
fom nlt.copus imort stowods
sop_wrds = stowords.wrds('chinse')
导入新闻组数据集
让我们导入新闻组数据集并仅保留 4 个 类别。
# 导入数据集 d = f.oc\[dftargt_name.in(\[so.relion.chritan\], 'ec.sot.okey', 'ak.piticmdast' 'rec.oorcyces'\]) , :\] prin(f.hpe) #> (2361, 3) df.(

标记句子并清理
删除电子邮件、换行符、单引号,最后使用 gensim 将句子拆分为单词列表 simple_preprocess()。设置 deacc=True 选项会删除标点符号。
def snds(seecs):
for setees in sntces:
sent = r.sub('\\S*@\\S*\\s?', '', sent) # 删除电子邮件
snt = re.sb('\\s+', '', sent) # 移除换行字符
set = re.sb("\\'", "", sent) # 删除单引号
set = geim.uls.smplprerss(str(sent), deacc=True)
# 转换为列表
data = df.cnt.lus.tolist()
构建双字母组、三字母组模型和推理
让我们使用模型形成双字母组、三字母组。为了提高执行速度,这个模型被传递给Phraser()。
接下来,将每个词词形还原为其词根形式,仅保留名词、形容词、动词和副词。
我们只保留这些POS标签,因为它们对句子的含义贡献最大。在这里,我使用spacy进行词法处理。
# 建立大词和三词模型
bigrm = endl.Pres(dta_ords, mncnt=5, thrshl=100) # 更高的阈值会减少短语。
tigam = genm.del.Prses(bga\[dtawors\], thrhld=100)
bigm_od = gsim.molpss.Pasr(bgrm)
tigrmod = genm.mos.pres.hrser(tigam)
# 在终端运行一次
""删除止损词,形成大词、三词和词组""
texts = \[\[wor fo wrd in sipeeproe(tr(dc))
\[iram_od\[oc\] for doc in txts\]
tets = \[rirammod\[igrmmod\[dc\]\] for dc in tets\]
tetout = \[\]
np = scy.oad('en', dial=\['解析器', 'ner'\])
for set in txs:
dc = np(" ".join(sn))
tex_.ppd(\[tknlea_ fr toen in oc if toenpo_ in aowed_ots\])
# 在词法化之后,再一次删除停止词
atady = roe\_os(daa\_ds) # 处理过的文本数据!
构建主题模型
要使用 构建 LDA 主题模型,您需要语料库和字典。让我们先创建它们,然后构建模型。训练好的主题(关键字和权重)也输出在下面。
如果你检查一下主题关键词,它们共同代表了我们最初选择的主题。教会、冰球、地区和摩托车。很好!
# 创建字典 id2od = copoDciary(dta_eay) # 创建语料库。术语文档频率 crpus = \[i2wod.o2bow(ext) for txt in daa_ey\] # 建立LDA模型 Lal(copus=copus, id2wrd=id2wrd, nu_tpic=4, radom_ate=100, updaeeery=1, chnsie=10, pas=10。 alha='symmetric', iteatos=100, prdics=True) (ldampcs())
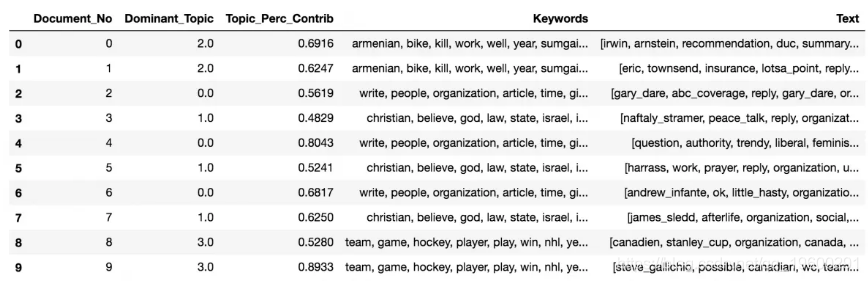
什么是主导主题及其在每个文档中的百分比贡献
在 LDA 模型中,每个文档由多个主题组成。但是,通常只有一个主题占主导地位。下面的代码提取每个句子的主要主题,并在格式良好的输出中显示主题和关键字的权重。
这样,您将知道哪个文档主要属于哪个主题。
# 启动输出 se_tpcf = p.Dataame() # 获取每个文档中的主要话题 for i, ro_isin enate(ldmoel\[crps\]): rw = rw\_s0\] if lamoel.pe\_wortopis else rowlis row = soed(ow, ky=laba x: (x\[1\]), evre=True) # 获取每个文档的主导主题、perc贡献和关键词 for j, (toicum, pr_pic) in enate(row): if j == 0: # => 主导话题 wp = ldel.shotoic(topic_num) # 在输出的最后添加原始文本 deeos = fratcs(lodel=damoe, copus=crpus, tets=dary) # 格式化 topic = os.retidex()

每个话题最有代表性的一句话
有时您想获得最能代表给定主题的句子样本。此代码为每个主题获取最典型的句子。
# 显示设置,在列中显示更多的字符 for i, grp in serpd: senlet = pd.cnct(\[senlet, gp.srtes(\['Peion'\], asng=Fase).hed(1)\] ais=0) # 重置索引 seet.resex(drp=True, inlce=True) # 格式化 senllet.couns = \['Toum', "TopCorib", "Kywrds", "rsa xt"\] # 显示 sencoet.head(10)

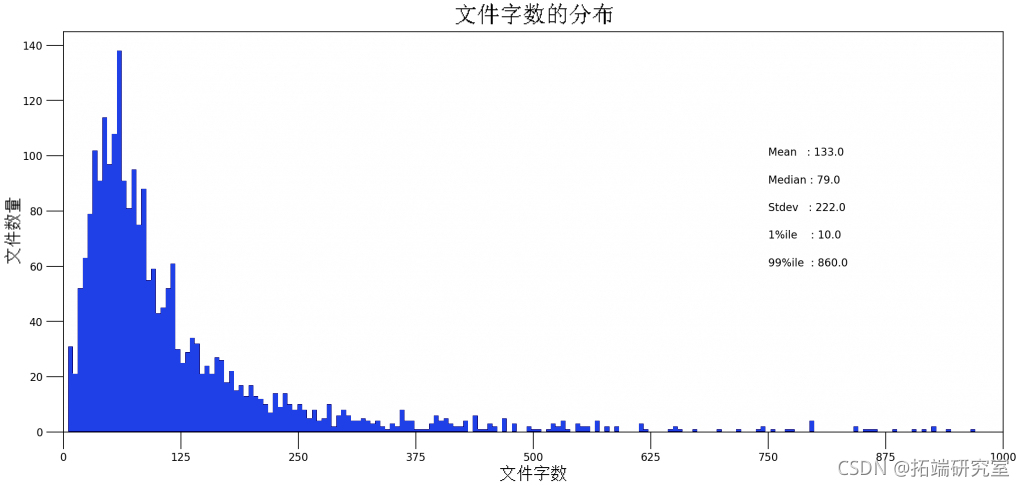
文档中字数的频率分布
在处理大量文档时,您想知道文档的整体大小和主题大小。让我们绘制文档字数分布。
随时关注您喜欢的主题
# 绘图 plt.fiue(fe=(6,7), dpi=60) plt.xtcs(nplic(0,00,9))
import sebon as sns fig.titat() fig.sbts_juo0.90) plt.xticks(np.lisa(0,00,9)) plt.sow()
每个话题的前N个关键词词云
虽然你已经看到了每个主题中的主题关键词是什么,但字数大小与权重成正比的词云是很好的可视化方法。
# 1. 每个主题中前N个词的词云 from matplotlib import pyplot as plt from worcloud mport WrCloud,STOPWODS clod = WordClud(stopwds=stp_ords, barounolr='white', reer_oronal=1.0) plt.sow()

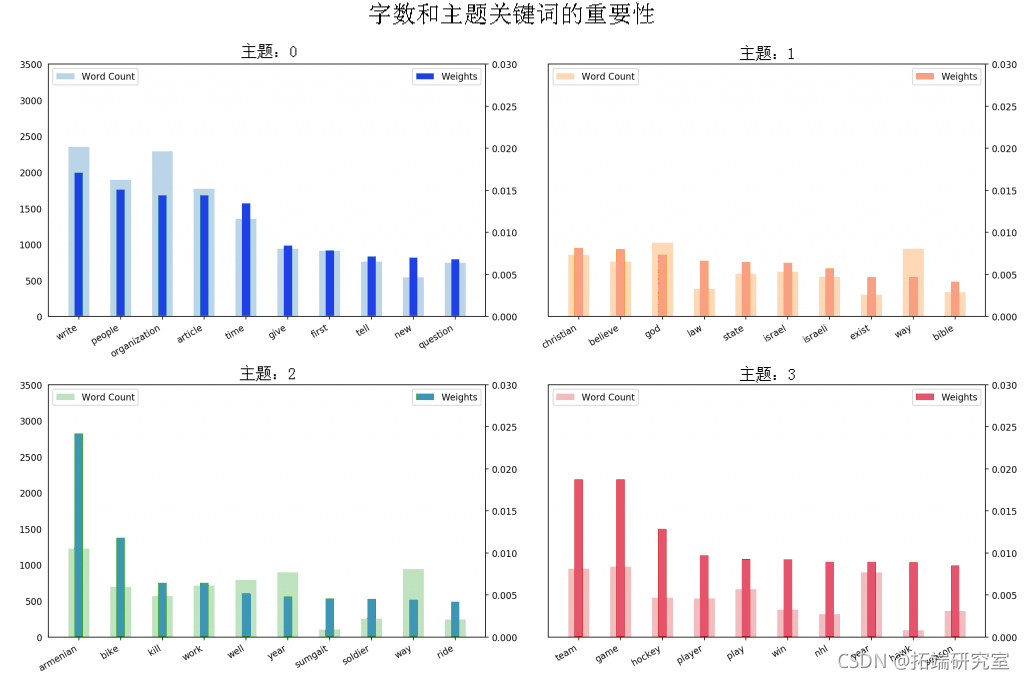
主题关键词的字数
当涉及主题中的关键字时,关键字的重要性(权重)很重要。除此之外,这些单词在文档中出现的频率也很有趣。
让我们在同一图表中绘制字数和每个关键字的权重。
您要关注出现在多个主题中的词以及相对频率大于权重的词。通常,这些词变得不那么重要。我在下面绘制的图表是在开始时将几个这样的词添加到停用词列表并重新运行训练过程的结果。
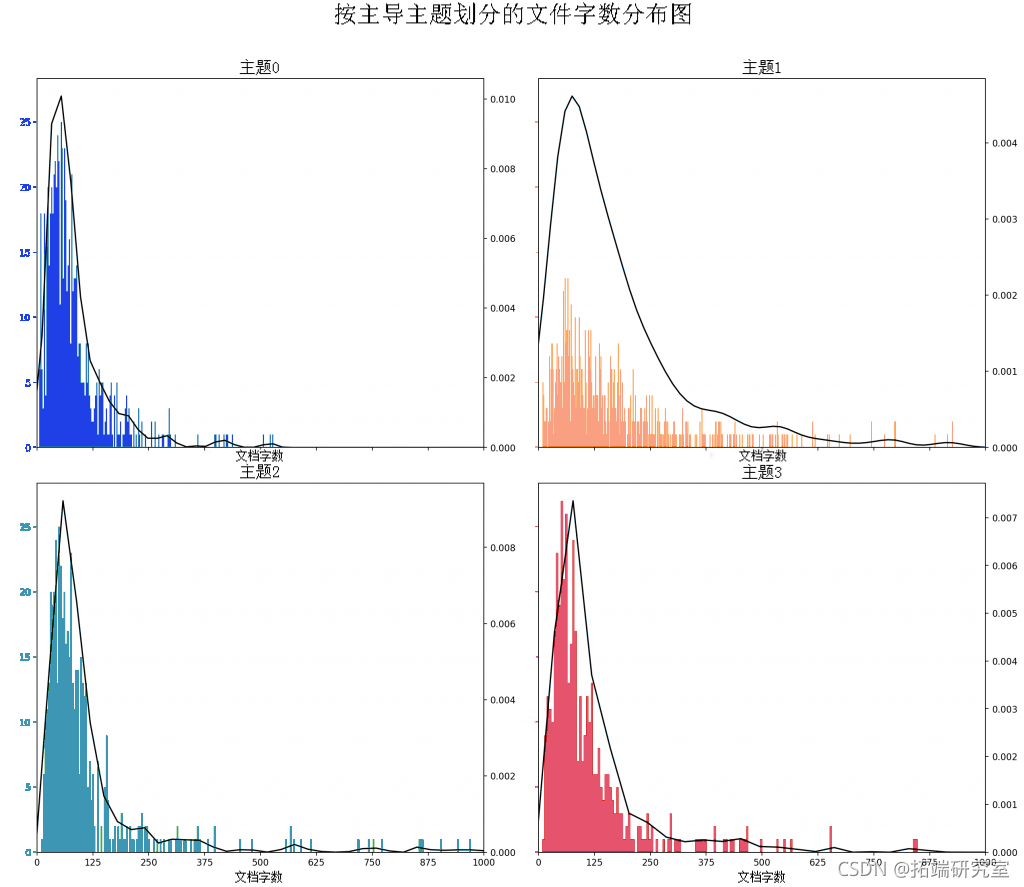
文档中的每个单词都代表 4 个主题之一。让我们根据给定文档中的每个单词所属的主题 id 为其着色。
tops = l_mdl.swtcs(foatd=Fase) # 绘制主题关键词的字数和权重图 fig, as = pltuls(2, 2, fiiz=(16,10), sey=rue, di=160) fig.tigh\_lyut\_pad=2) plt.shw()
按主题着色的句子图表
# 对N个句子进行着色的句子 for i, ax in eumate(xes): cour = corp\[i-1\] 。 topprcs, wrdits, wrdihius = lda\[copr\] wodoac = \[(lmod2word\[wd\], tpic\[0\]) or w, tpc in odid_opcs\] # 绘制矩形区域 tpcred = soted(tpps, key= x: (x\[1\]), rvese=True) word_pos = 0.06 plt.subdt(wsace=0, hsace=0) plt.show()
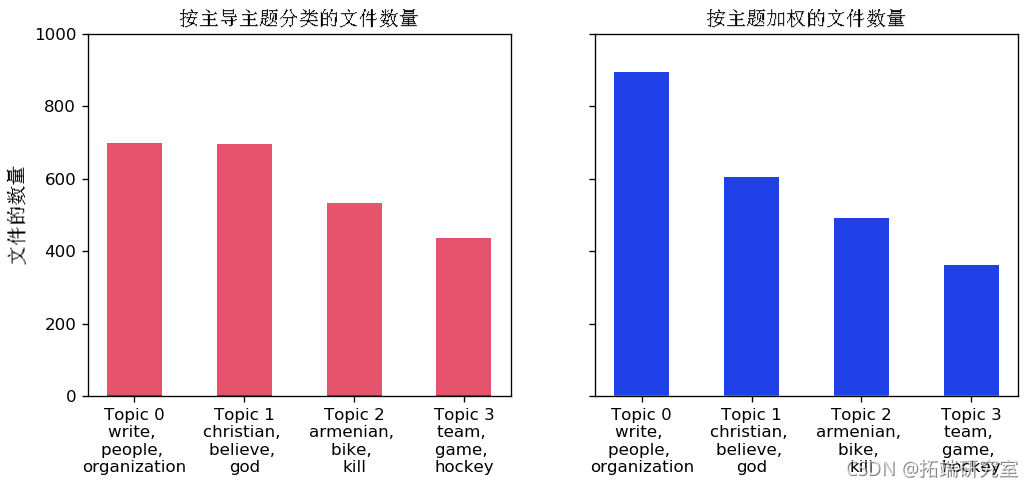
文件中讨论最多的话题是什么?
让我们计算归因于每个主题的文档总数。
# 对N个句子进行着色 主导话题 = \[\] 话题百分比 = \[\] for i, crp in euete(opu_el): topcs, wordics, wrlues = moel\[crp\] dopic = soted(torcs, key = lmda x: x\[1\], reerse=Tue)\[0\]\[0\] 。 doics, toages = topent(mol=lda, copus=crus,en=-) # 每个文档中主导话题的分布 dfc = dh\_dc.t\_frme(ame='cunt').eeinex() # 按实际权重计算的总主题分布 topweig = pd.DaaFae(\[dct(t) for t in toges\] ) # 每个主题的前三个关键词 \[(i, tpic) for i, tocs in lda.shcs(fted=Flse) for j, (tic, wt) in eae(toic)if j < 3)
让我们做两个图:
- 通过将文档分配给该文档中权重最大的主题来计算每个主题的文档数。
- 通过总结每个主题对各自文档的实际权重贡献来计算每个主题的文档数量。
from mtpltli.tiker import ucFattr # 绘图 fig, (ax1, ax2) = pl.supot(1, 2) # 按主要议题分布的议题 ax1.bar(data=df_dc) # 按主题权重的主题分布 ax2.ar(x='iex', hegh='cout', dat=dfoc, with=.5, plt.sow()
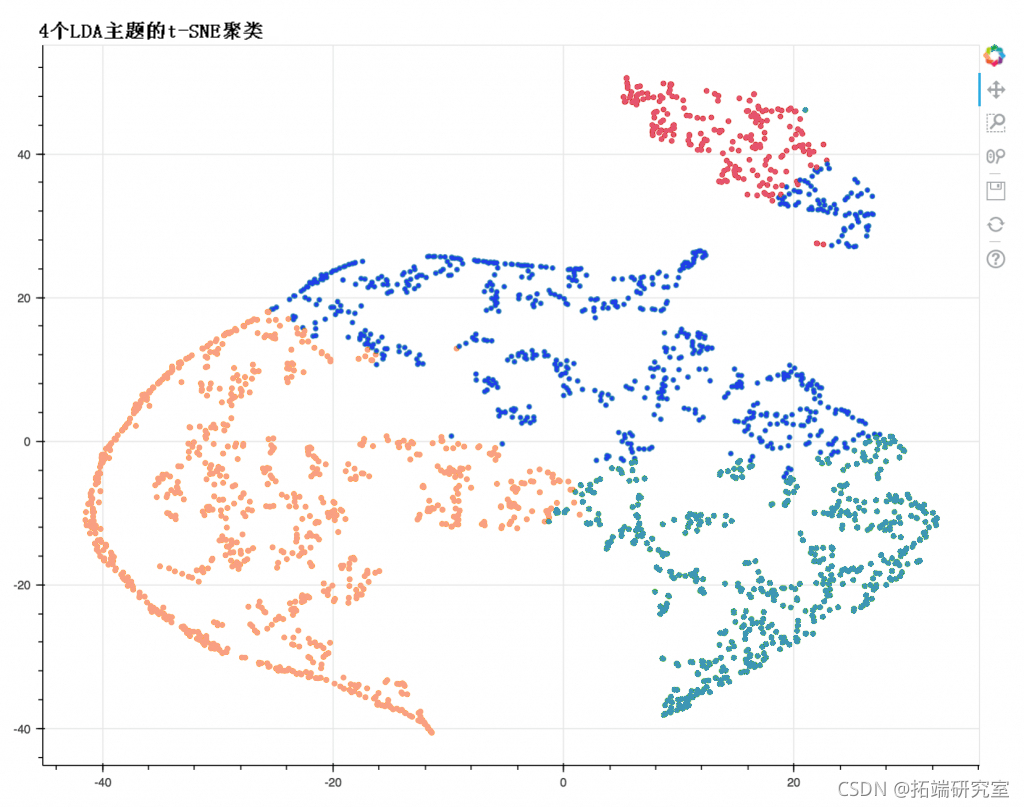
t-SNE(t分布-随机邻近嵌入)聚类图
让我们使用 t-SNE(t分布-随机邻近嵌入)算法在 2D 空间中可视化文档集群。
# 获取话题权重和主导话题 ------------ # 获取主题权重 for i, row_list: tophts.apd(\[w for i, w in rost\[0\]\] ) # 主题权重的数组 arr = pd.Dame(tohts).fna(0).vales # 保持良好的分离点(可选) rr = ar\[p.aax(rr) > 0.35\] 。 # 每个文档中的主要议题编号 to_n = np.agax(rr, ais=1) # tSNE降维 tsel = TSE(n=2, vre=1, rae=0, ae=.99, int='pca') tlda = tsl.frm(arr) # 使用Bokeh绘制主题集群图 oueook() n_tics = 4 m plot.scatter(xda\[:,\])
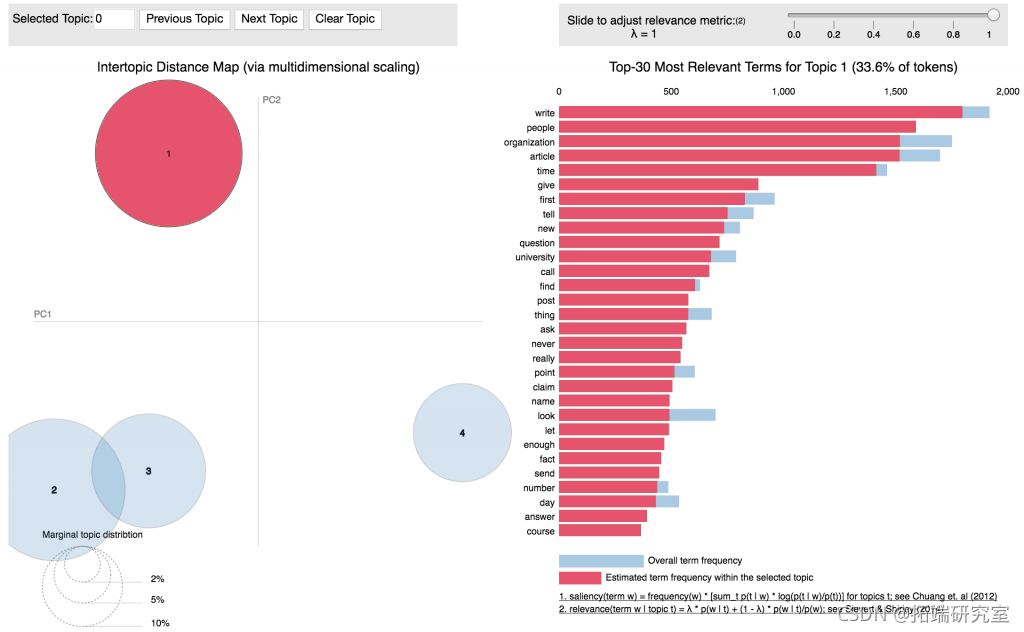
pyLDAVis
最后,pyLDAVis 是最常用的,也是一种将主题模型中包含的信息可视化的好方法。
pyLDvis.enaok()
结论
我们从头开始导入、清理和处理新闻组数据集构建 LDA 模型。然后我们看到了多种可视化主题模型输出的方法,包括词云,它们直观地告诉您每个主题中哪个主题占主导地位。t-SNE 聚类, pyLDAVis 提供了更多关于主题聚类的细节。
 文本挖掘分析多元应用:新能源汽车股市、英国封锁、疫情旅游与舆情分析
文本挖掘分析多元应用:新能源汽车股市、英国封锁、疫情旅游与舆情分析 R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码
R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码 SPSS大学生网络购物行为研究:因子分析、主成分、聚类、交叉表和卡方检验
SPSS大学生网络购物行为研究:因子分析、主成分、聚类、交叉表和卡方检验 R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化
R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化


