
软件开发职位通常需要的技能是NoSQL数据库(包括MongoDB)的经验。
本教程将探索使用API收集数据,将其存储在MongoDB数据库中以及对数据进行一些分析。
我们将使用什么API?
我们将使用的API是GameSpot的API。GameSpot是网络上最大的视频游戏评论网站之一,可以在此处访问其API 。
设定
在我们开始之前,您应该确保自己获得GameSpot的API密钥。您还应该确保已安装MongoDB及其Python库。可以在这里找到Mongo的安装说明。
只需运行以下命令即可安装PyMongo库:
$ pip install pymongo

创建MongoDB数据库
现在,我们可以通过创建MongoDB数据库来开始我们的项目。首先,我们要处理进口商品。我们MongoClient将从PyMongo以及requests和导入pandas:
from pymongo import MongoClient
import requests
import pandas as pd
使用MongoDB创建数据库时,我们首先需要连接到客户端,然后使用客户端来创建所需的数据库:
client = MongoClient('127.0.0.1', 27017)
db_name = 'gamespot_reviews'
# connect to the database
db = client[db_name]
MongoDB可以在一个数据库中存储多个数据集合,因此我们还需要定义我们要使用的集合的名称:
# open the specific collection
reviews = db.reviews
我们的数据库和集合已创建,我们准备开始向其中插入数据。
使用API
我们需要向包含我们的API密钥的基本URL发出请求。GameSpot的API拥有自己的多个资源,我们可以从中提取数据。例如,他们有一个资源,其中列出了有关游戏的数据,例如发行日期和控制台。
但是,我们对他们的游戏评论资源很感兴趣, 我们 通过创建将传递给requests函数的标头来做到这一点:
headers = {
"user_agent": "[YOUR IDENTIFIER] API Access"
}
games_base = "http://www.gamespot.com/api/reviews/?api_key=[YOUR API KEY HERE]&format=json"
下面的数据字段:id,title,score,deck,body,good,bad:
review_fields = "id,title,score,deck,body,good,bad"
GameSpot一次只能返回100个结果。因此,为了获得数量可观的评论以进行分析,我们需要创建一系列数字并遍历它们,一次检索100个结果。
您可以选择任何数字。我选择了接受他们的所有评论,最高评分为14,900:
pages = list(range(0, 14900))
pages_list = pages[0:14900:100]
我们将创建一个将基本URL,我们要返回的字段列表,排序方案(升序或降序)以及查询的偏移量连接在一起的函数。
我们将获取要循环浏览的页面数,然后每100个条目将创建一个新URL并请求数据:
def get_games(url_base, num_pages, fields, collection):
field_list = "&field_list=" + fields + "&sort=score:desc" + "&offset="
for page in num_pages:
url = url_base + field_list + str(page)
...
print("Data Inserted")
回想一下,MongoDB将数据存储为JSON。因此,我们需要使用json()方法将响应数据转换为JSON格式。
数据转换为JSON后,我们将从响应中获取“结果”属性,因为这实际上是包含我们感兴趣的数据的部分。然后,我们将遍历100个不同的结果,并使用insert_one()PyMongo中的命令将每个结果插入到我们的集合中。也可以将它们全部放入列表中并使用insert_many()。
现在让我们调用该函数并让其收集数据:
get_games(review_base, pages_list, review_fields, reviews)
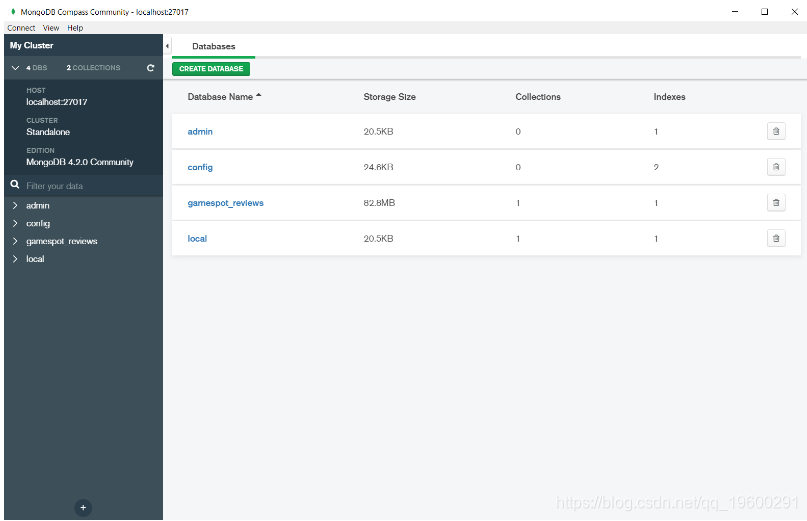
我们可以使用Compass程序直接查看数据库及其内容:
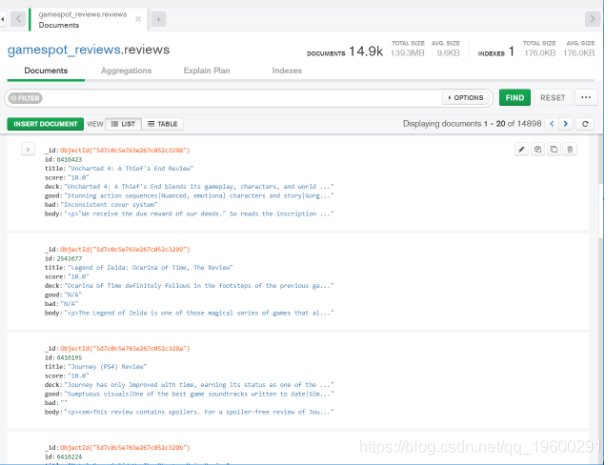

我们可以看到数据已正确插入。
我们还可以进行一些数据库检索并进行打印。为此,我们将创建一个空列表来存储我们的条目,并.find()在“评论”集合上使用该命令。
使用findPyMongo中的函数时,检索也需要格式化为JSON。赋予find函数的参数将具有一个字段和值。
默认情况下,MongoDB始终返回该_id字段(它自己的唯一ID字段,而不是我们从GameSpot提取的ID),但是我们可以告诉它通过指定一个0值来抑制它。我们确实希望返回的score字段(如本例中的字段)应被赋予一个1值:
scores = []
...
print(scores[:900])
这是成功提取并打印的内容:
[{'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'}, {'score': '10.0'} ...
我们还可以使用Pandas轻松地将查询结果转换为数据框:
scores_data = pd.DataFrame(scores, index=None)
print(scores_data.head(20))
这是返回的内容:
score
0 10.0
1 10.0
2 10.0
3 10.0
4 10.0
5 10.0
6 10.0
7 10.0
8 10.0
9 10.0
10 10.0
11 10.0
12 10.0
13 10.0
14 10.0
15 10.0
16 10.0
17 9.9
18 9.9
19 9.9
在开始分析某些数据之前,让我们花点时间看一下如何将两个集合潜在地结合在一起。如前所述,GameSpot具有多种资源来提取数据,我们可能希望从第二个数据库(如“游戏”数据库)中获取值。
MongoDB是NoSQL数据库,因此与SQL不同,MongoDB并非旨在处理数据库之间的关系并将数据字段连接在一起。但是,有一个函数可以近似数据库join- lookup()。
最后,您选择一个名称将外部文档转换为该名称,它们将以该新名称显示在我们的查询响应表中。如果您有另一个数据库要调用,games并且希望将它们连接在一起进行查询,则可以这样进行:
pipeline = [{
'$lookup': {
...
}
},]
for doc in (games.aggregate(pipeline)):
print(doc)
分析数据
现在,我们可以分析和可视化在新创建的数据库中找到的一些数据。让我们确保我们具有分析所需的所有功能。
from pymongo import MongoClient
import pymongo
import pandas as pd
from bs4 import BeautifulSoup
import re
from nltk.corpus import stopwords
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
import string
import en_core_web_sm
import seaborn as sns
假设我们要对GameSpot游戏评论中的单词进行一些分析。
我们可以find()像以前一样使用函数从数据库中收集前40条(或任意数量)评论开始,但是这次我们将指定我们要按score变量排序并以降序排序:
d_name = 'gamespot_reviews'
collection_name = 'gamespot'
client = MongoClient('127.0.0.1', 27017)
db = client[d_name]
...我们将把该响应转换为Pandas数据框,并将其转换为字符串。然后,我们将提取<p>HTML标记中包含审阅文本的所有值,并使用BeautifulSoup进行处理:
reviews_data = pd.DataFrame(review_bodies, index=None)
def extract_comments(input):
...
review_entries = extract_comments(str(review_bodies))
print(review_entries[:500])
查看print声明以查看评论文本是否已收集:
[<p>For anyone who hasn't actually seen the game on a TV right in front of them, the screenshots look too good to be true. In fact, when you see NFL 2K for the first time right in front of you...]
现在我们有了审阅文本数据,我们想要以几种不同的方式对其进行分析。 我们可以通过几种不同的方式进行操作:
- 我们可以创建一个词云
- 我们可以计算所有单词并按其出现次数排序
但是,在对数据进行任何分析之前,我们必须对其进行预处理。
为了预处理数据,我们想创建一个函数来过滤条目。文本数据中仍然充满各种标签和非标准字符,我们希望通过获取评论注释的原始文本来删除它们。我们将使用正则表达式将非标准字符替换为空格。
我们还将使用NTLK中的一些停用词(非常常见的词,对我们的文本几乎没有任何意义),并通过创建一个列表来保留所有单词,然后仅在不包含这些单词的情况下才将其从列表中删除,从而将其从文本中删除我们的停用词列表。
词云
让我们获取一部分复习词以可视化为语料库。如果生成时太大,可能会导致单词cloud出现问题。
例如,我过滤掉了前5000个单词:
stop_words = set(stopwords.words('english'))
def filter_entries(entries, stopwords):
...
for word in split_entries:
...
return entries_words
review_words = filter_entries(review_entries, stop_words)
review_words = review_words[5000:]
现在,我们可以使用此处提供的预制WordCloud库,非常轻松地制作词云。
这个词云确实为我们提供了一些有关热门评论中常用词的信息:


实际上,我们确实掌握了一些有关游戏评论中所讨论的概念的信息:游戏玩法,故事,角色,世界,动作,位置等。
我们可以将最普通的单词分解成一个单词列表,然后将它们与单词的总数一起添加到单词词典中,每次看到相同的单词时,该列表就会递增。
然后,我们只需要使用Counter和most_common()函数:
def get_word_counts(words_list):
word_count = {}
for word in words_list:
...
return word_count
...
print(review_list)
以下是一些最常用的单词的计数:
[('game', 1231), ('one', 405), ('also', 308), ('time', 293), ('games', 289), ('like', 285), ('get', 278), ('even', 271), ('well', 224), ('much', 212), ('new', 200), ('play', 199), ('level', 195), ('different', 195), ('players', 193) ...]
命名实体识别
我们还可以使用spaCyen_core_web_sm随附的语言模型进行命名实体识别。此处列出了可以检测到的各种概念和语言功能。
我们需要从文档中获取检测到的命名实体和概念的列表(单词列表):
doc = nlp(str(review_words))
...我们可以打印出找到的实体以及实体的数量。
# Example of named entities and their categories
print([(X.text, X.label_) for X in doc.ents])
# All categories and their counts
print(Counter(labels))
# Most common named entities
print(Counter(items).most_common(20))
内容如下:
[('Nintendo', 'ORG'), ('NES', 'ORG'), ('Super', 'WORK_OF_ART'), ('Mario', 'PERSON'), ('15', 'CARDINAL'), ('Super', 'WORK_OF_ART'), ('Mario', 'PERSON'), ('Super', 'WORK_OF_ART') ...]
Counter({'PERSON': 1227, 'CARDINAL': 496, 'ORG': 478, 'WORK_OF_ART': 204, 'ORDINAL': 200, 'NORP': 110, 'PRODUCT': 88, 'GPE': 63, 'TIME': 12, 'DATE': 12, 'LOC': 12, 'QUANTITY': 4 ...]
[('first', 147), ('two', 110), ('Metal', 85), ('Solid', 82), ('GTAIII', 78), ('Warcraft', 72), ('2', 59), ('Mario', 56), ('four', 54), ('three', 42), ('NBA', 41) ...]
我们只需要创建一个函数来获取不同类别的实体的数量,然后使用它来获取所需的实体即可。
我们将获得已命名实体 ,组织和GPE(位置)的列表:
def word_counter(doc, ent_name, col_name):
ent_list = []
for ent in doc.ents:
...
review_gpe = word_counter(doc, 'GPE', 'GPEs')
现在我们要做的就是用一个函数绘制计数:
plot_categories("Named Entities", review_persons, 30)
plot_categories("Organizations", review_org, 30)
plot_categories("GPEs", review_gpe, 30)
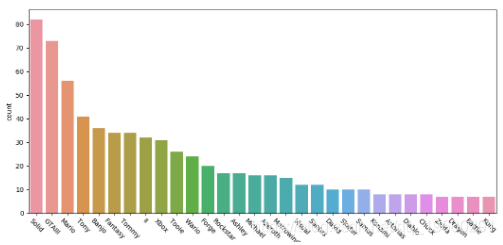

让我们看一下生成的图。
正如所预期的命名实体的,大部分返回的结果是视频游戏人物的名字。
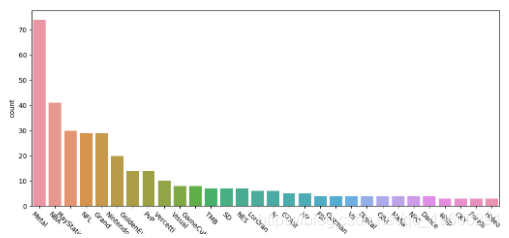

组织图显示了一些合适的游戏开发商和发行商,例如Playstation和Nintendo 。
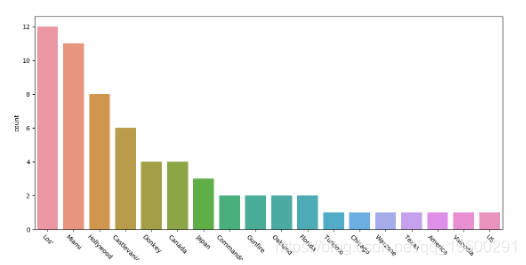

上面是GPE或地理位置的图。看起来“好莱坞”和“迈阿密”经常出现在游戏评论中。
绘制数值
最后,我们可以尝试从数据库中绘制数值。让我们从评论集合中获取分数值,对它们进行计数,然后绘制它们:
scores = []
...
plt.xticks(rotation=-90)
plt.show()

上图是给出的评分总数(从0到9.9)的图表。
结论
收集,存储,检索和分析数据是当今世界上非常需要的技能,而MongoDB是最常用的NoSQL数据库平台之一。
了解如何使用NoSQL数据库以及如何解释其中的数据将使您能够执行许多常见的数据分析任务。
 Python数据可视化-seaborn Iris鸢尾花数据
Python数据可视化-seaborn Iris鸢尾花数据


