
此示例中,神经网络用于使用2011年4月至2013年2月期间的数据预测公民办公室的电力消耗。
最近我们被客户要求撰写关于预测电力负荷的研究报告。每日数据是通过总计每天提供的15分钟间隔的消耗量来创建的。
可下载资源
LSTM简介
LSTM(或长短期记忆人工神经网络)允许分析具有长期依赖性的有序数据。当涉及到这项任务时,传统的神经网络体现出不足,在这方面,LSTM将用于预测这种情况下的电力消耗模式。
与ARIMA等模型相比,LSTM的一个特殊优势是数据不一定需要是稳定的(常数均值,方差和自相关),以便LSTM对其进行分析。
▌短时记忆
NN 会受到短时记忆的影响。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。 因此,如果你正在尝试处理一段文本进行预测,RNN 可能从一开始就会遗漏重要信息。
在反向传播期间,RNN 会面临梯度消失的问题。 梯度是用于更新神经网络的权重值,消失的梯度问题是当梯度随着时间的推移传播时梯度下降,如果梯度值变得非常小,就不会继续学习。
梯度更新规则
因此,在递归神经网络中,获得小梯度更新的层会停止学习—— 那些通常是较早的层。 由于这些层不学习,RNN 可以忘记它在较长序列中看到的内容,因此具有短时记忆。
▌作为解决方案的 LSTM 和 GRU
LSTM 和 GRU 是解决短时记忆问题的解决方案,它们具有称为“门”的内部机制,可以调节信息流。
这些“门”可以知道序列中哪些重要的数据是需要保留,而哪些是要删除的。 随后,它可以沿着长链序列传递相关信息以进行预测,几乎所有基于递归神经网络的技术成果都是通过这两个网络实现的。
LSTM 和 GRU 可以在语音识别、语音合成和文本生成中找到,你甚至可以用它们为视频生成字幕。对 LSTM 和 GRU 擅长处理长序列的原因,到这篇文章结束时你应该会有充分了解。
下面我将通过直观解释和插图进行阐述,并避免尽可能多的数学运算。
▌RNN 述评
为了了解 LSTM 或 GRU 如何实现这一点,让我们回顾一下递归神经网络。 RNN 的工作原理如下;第一个词被转换成了机器可读的向量,然后 RNN 逐个处理向量序列。
处理时,RNN 将先前隐藏状态传递给序列的下一步。 而隐藏状态充当了神经网络记忆,它包含相关网络之前所见过的数据的信息。
让我们看看 RNN 的一个细胞,了解一下它如何计算隐藏状态。 首先,将输入和先前隐藏状态组合成向量, 该向量包含当前输入和先前输入的信息。 向量经过激活函数 tanh之后,输出的是新的隐藏状态或网络记忆。
激活函数 Tanh
激活函数 Tanh 用于帮助调节流经网络的值。 tanh 函数将数值始终限制在 -1 和 1 之间。
当向量流经神经网络时,由于有各种数学运算的缘故,它经历了许多变换。 因此想象让一个值继续乘以 3,你可以想到一些值是如何变成天文数字的,这让其他值看起来微不足道。
没有 tanh 函数的向量转换
tanh 函数确保值保持在 -1~1 之间,从而调节了神经网络的输出。 你可以看到上面的相同值是如何保持在 tanh 函数所允许的边界之间的。
有 tanh 函数的向量转换
这是一个 RNN。 它内部的操作很少,但在适当的情形下(如短序列)运作的很好。 RNN 使用的计算资源比它的演化变体 LSTM 和 GRU 要少得多。
▌LSTM
LSTM 的控制流程与 RNN 相似,它们都是在前向传播的过程中处理流经细胞的数据,不同之处在于 LSTM 中细胞的结构和运算有所变化
这一系列运算操作使得 LSTM具有能选择保存信息或遗忘信息的功能。咋一看这些运算操作时可能有点复杂,但没关系下面将带你一步步了解这些运算操作。
核心概念
LSTM 的核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。
因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。
Sigmoid
门结构中包含着 sigmoid 激活函数。Sigmoid 激活函数与 tanh 函数类似,不同之处在于 sigmoid 是把值压缩到 0~1 之间而不是 -1~1 之间。这样的设置有助于更新或忘记信息,因为任何数乘以 0 都得 0,这部分信息就会剔除掉。同样的,任何数乘以 1 都得到它本身,这部分信息就会完美地保存下来。这样网络就能了解哪些数据是需要遗忘,哪些数据是需要保存。
接下来了解一下门结构的功能。LSTM 有三种类型的门结构:遗忘门、输入门和输出门。
遗忘门
遗忘门的功能是决定应丢弃或保留哪些信息。来自前一个隐藏状态的信息和当前输入的信息同时传递到 sigmoid 函数中去,输出值介于 0 和 1 之间,越接近 0 意味着越应该丢弃,越接近 1 意味着越应该保留。
输入门
输入门用于更新细胞状态。首先将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要。
其次还要将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去,创造一个新的侯选值向量。最后将 sigmoid 的输出值与 tanh 的输出值相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的。
细胞状态
下一步,就是计算细胞状态。首先前一层的细胞状态与遗忘向量逐点相乘。如果它乘以接近 0 的值,意味着在新的细胞状态中,这些信息是需要丢弃掉的。然后再将该值与输入门的输出值逐点相加,将神经网络发现的新信息更新到细胞状态中去。至此,就得到了更新后的细胞状态。
输出门
输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,我们将前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的细胞状态传递给 tanh 函数。
最后将 tanh 的输出与 sigmoid 的输出相乘,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。
让我们再梳理一下。遗忘门确定前一个步长中哪些相关的信息需要被保留;输入门确定当前输入中哪些信息是重要的,需要被添加的;输出门确定下一个隐藏状态应该是什么。
▌GRU
知道了 LSTM 的工作原理之后,来了解一下 GRU。GRU 是新一代的循环神经网络,与 LSTM 非常相似。与 LSTM 相比,GRU 去除掉了细胞状态,使用隐藏状态来进行信息的传递。它只包含两个门:更新门和重置门。
更新门
更新门的作用类似于 LSTM 中的遗忘门和输入门。它决定了要忘记哪些信息以及哪些新信息需要被添加。
重置门
重置门用于决定遗忘先前信息的程度。
这就是 GRU。GRU 的张量运算较少,因此它比 LSTM 的训练更快一下。很难去判定这两者到底谁更好,研究人员通常会两者都试一下,然后选择最合适的。
自相关图,Dickey-Fuller测试和对数变换
为了确定我们的模型中是否存在平稳性:
- 生成自相关和偏自相关图
- 进行Dickey-Fuller测试
- 对时间序列进行对数变换,并再次运行上述两个过程,以确定平稳性的变化(如果有的话)
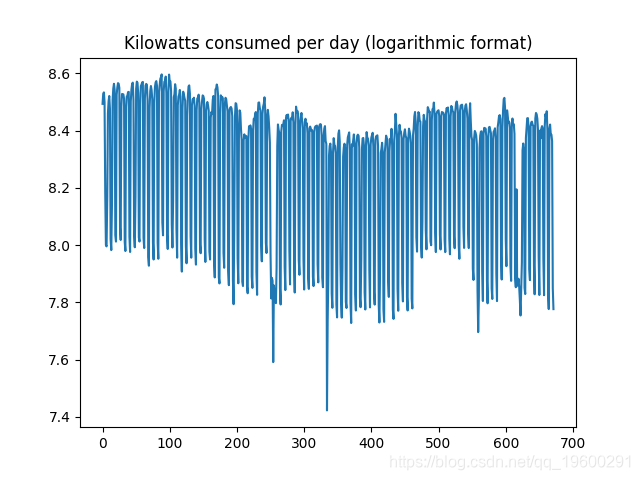
首先,这是时间序列图:
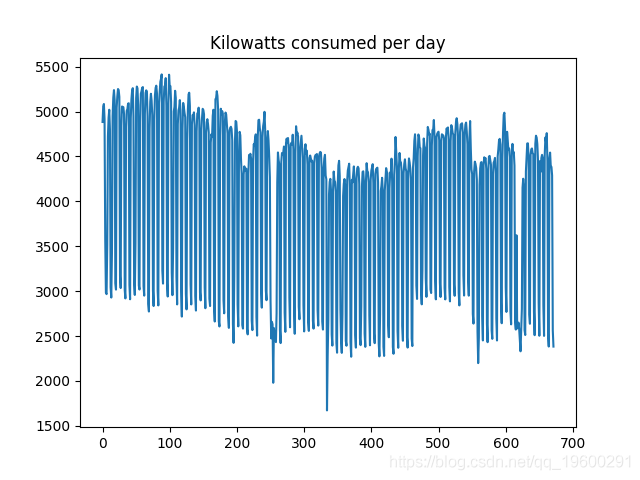
据观察,波动性(或消费从一天到下一天的变化)非常高。在这方面,对数变换可以用于尝试稍微平滑该数据。在此之前,生成ACF和PACF图,并进行Dickey-Fuller测试。
自相关图
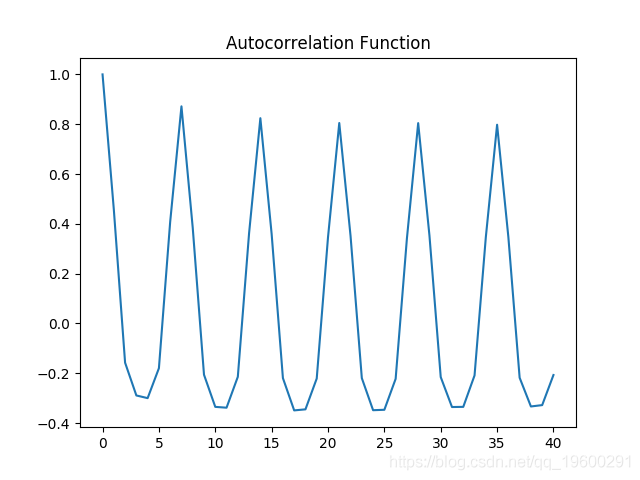
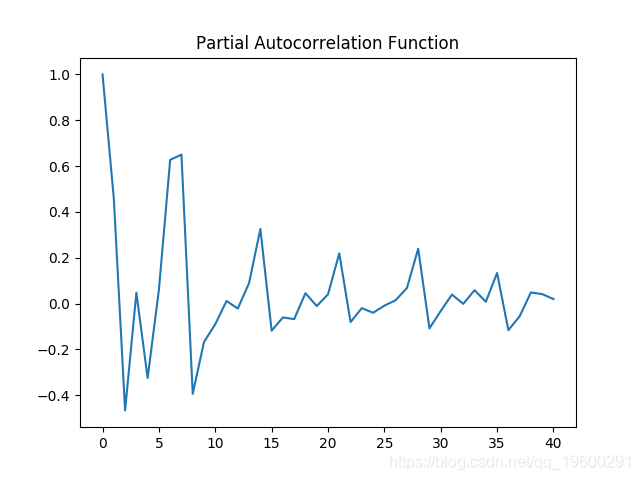
偏自相关图
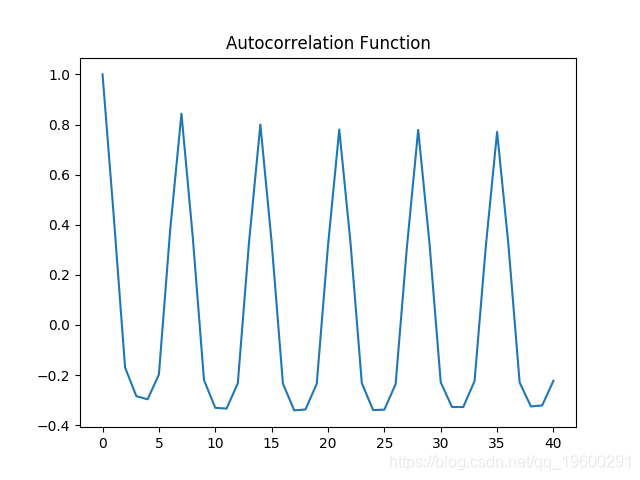
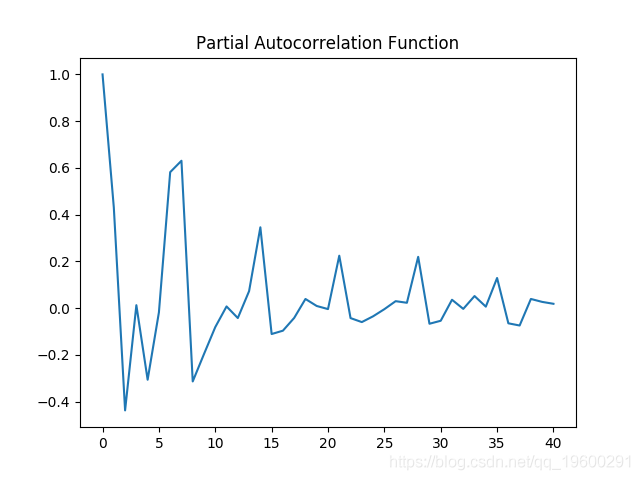
自相关和偏自相关图都表现出显着的波动性,这意味着时间序列中的几个区间存在相关性。
运行Dickey-Fuller测试时,会产生以下结果:
当p值高于0.05时,不能拒绝非平稳性的零假设。
STD1
954.7248
4043.4302
0.23611754
变异系数(或平均值除以标准差)为0.236,表明该系列具有显着的波动性。
现在,数据被转换为对数格式。
虽然时间序列仍然不稳定,但当以对数格式表示时,偏差的大小略有下降:
此外,变异系数已显着下降至0.0319,这意味着与平均值相关的趋势的可变性显着低于先前。
STD2 = np.std(数据集)
mean2 = np.mean(数据集)
cv2 = std2 / mean2 #变异系数std2
0.26462445 mean2
8.272395 cv2
0.031988855 同样,在对数数据上生成ACF和PACF图,并再次进行Dickey-Fuller测试。

自相关图
偏自相关图
Dickey-Fuller测试
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
Output
1%: -3.440
5%: -2.866
10%: -2.569Dickey-Fuller检验的p值降至0.0576。虽然这在技术上没有拒绝零假设所需的5%显着性阈值,但对数时间序列已显示基于CV度量的较低波动率,因此该时间序列用于LSTM的预测目的。
LSTM的时间序列分析
现在,LSTM模型用于预测目的。
数据处理
首先,导入相关库并执行数据处理
LSTM生成和预测
模型训练超过100期,并生成预测。
#生成LSTM网络
model = Sequential()
model.add(LSTM(4,input_shape =(1,previous)))
model.fit(X_train,Y_train,epochs = 100,batch_size = 1,verbose = 2)
#生成预测
trainpred = model.predict(X_train)
#将标准化后的数据转换为原始数据
trainpred = scaler.inverse_transform(trainpred)
#计算 RMSE
trainScore = math.sqrt(mean_squared_error(Y_train [0],trainpred [:,0]))
#训练预测
trainpredPlot = np.empty_like(dataset)
#测试预测
#绘制所有预测
inversetransform,= plt.plot(scaler.inverse_transform(dataset))
随时关注您喜欢的主题
准确性
该模型显示训练数据集的均方根误差为0.24,测试数据集的均方根误差为0.23。平均千瓦消耗量(以对数格式表示)为8.27,这意味着0.23的误差小于平均消耗量的3%。
以下是预测消费与实际消费量的关系图:
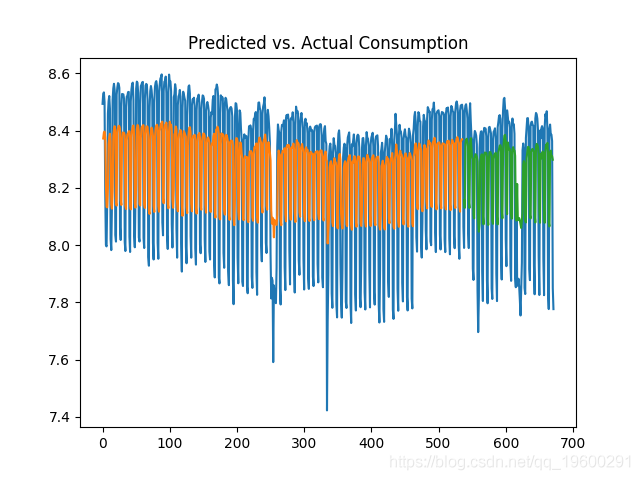
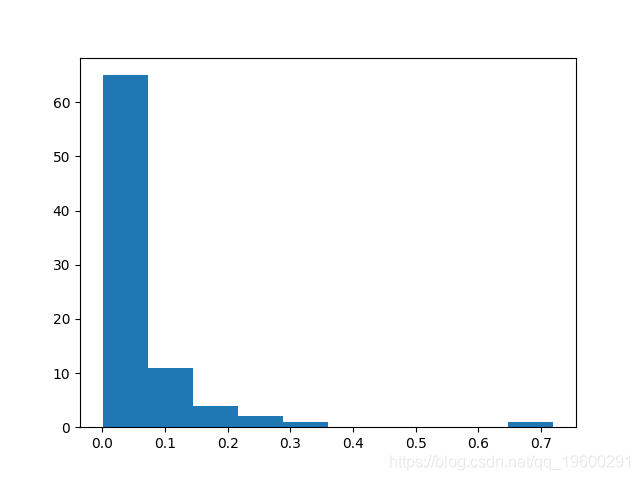
有趣的是,当在原始数据上生成预测(未转换为对数格式)时,会产生以下训练和测试误差:
在每天平均消耗4043千瓦的情况下,测试的均方误差占总日均消耗量的近20%,并且与对数数据产生的误差相比非常高。
让我们来看看这增加预测到10和50天。
10天
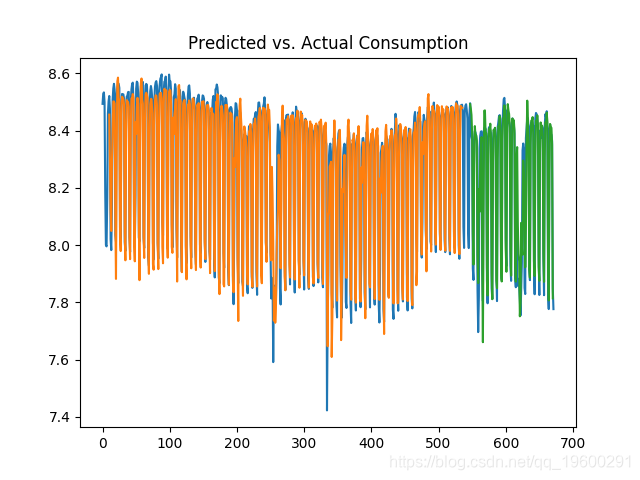
50天
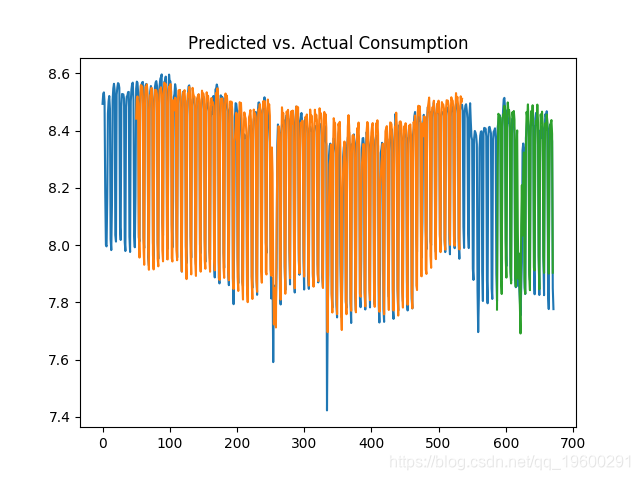
鉴于数据是对数格式,现在可以通过获得数据的指数来获得预测的真实值。
我们可以看到测试误差在10天和50天期间显着降低,并且考虑到LSTM模型在预测时考虑了更多的历史数据,消耗的波动性得到了更好的预测。
例如,testpred变量用(1,-1)重新调整:
testpred.reshape(1,-1)
array([[7.7722197,8.277015,8.458941,8.455311,8.447589,8.445035,
8.425287,8.404881,8.457063,8.423954,7.98714,7.9003944,
8.240862,8.41654,8.423854,8.437414,8.397851,7.9047146]],
dtype = float32)结论
对于这个例子,LSTM被证明在预测电力消耗波动方面非常准确。此外,以对数格式表示时间序列可以提高LSTM的预测准确度。
 【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据
【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据 数据分享|R语言Python机器学习预测4案例合集:众筹平台、机票折扣、糖尿病患者、员工满意度
数据分享|R语言Python机器学习预测4案例合集:众筹平台、机票折扣、糖尿病患者、员工满意度 R语言神经网络模型金融应用预测上证指数时间序列可视化
R语言神经网络模型金融应用预测上证指数时间序列可视化 R语言用随机森林模型的酒店收入和产量预测误差分析
R语言用随机森林模型的酒店收入和产量预测误差分析


