豆瓣读书是豆瓣网的一个子版块。
本文数据来源于豆瓣读书网站,分析内容将基于豆瓣读书的图书评分和评论信息。
主题将紧紧围绕以下几点:有哪些书籍值得推荐?一般书籍的价格是多少?一本书的评分和评论数量之间是否存在某种关系?
可下载资源
热门书籍分布
截至爬取之日,热门书评数量实时增长,分别是:
项集:项的集合。例:集合{computer,printer}就是一个2项集。
支持度:表示在所有的事务中同时出现该项集的概率。(项集A的支持度计数是事务数据集中包含项集 A 的事务个数。若已知项集的支持度计数,则规则A => B的支持度和置信度很容易从所有事务计数、项集A和项集A∪B的支持度计数推出。)
频繁项集:在一次具体的数据分析任务中,我们可以自行设定最小支持度阈值,则如果项集A的支持度满足预定义中的最小支持度阈值,即A项集为频繁项集(若A包含k个项,则也称A为k频繁项集)。
关联规则:指有关联的规则。例如上面的例子中 “面包=>牛奶” 就是一条关联规则。其侧面揭示了事务中的某种联系。
置信度:表示的是关联规则的前件出现时后件是否会出现,若出现,后件出现的概率有多大。对于A=>B而言,置信度表示A出现时B同时出现的概率。
①:评分>=8.0且评论超过10w+的书籍; ②:只有评论超过10w+的书; ③:按书评数量排名TOP8;
经过对比,我发现一些值得一读再读的名著总是在列表中,而且列表中的大部分书籍都是开卷即有益的好书。 降低标准后,也出现了一些有益的书籍(《平凡的世界》之类的)。
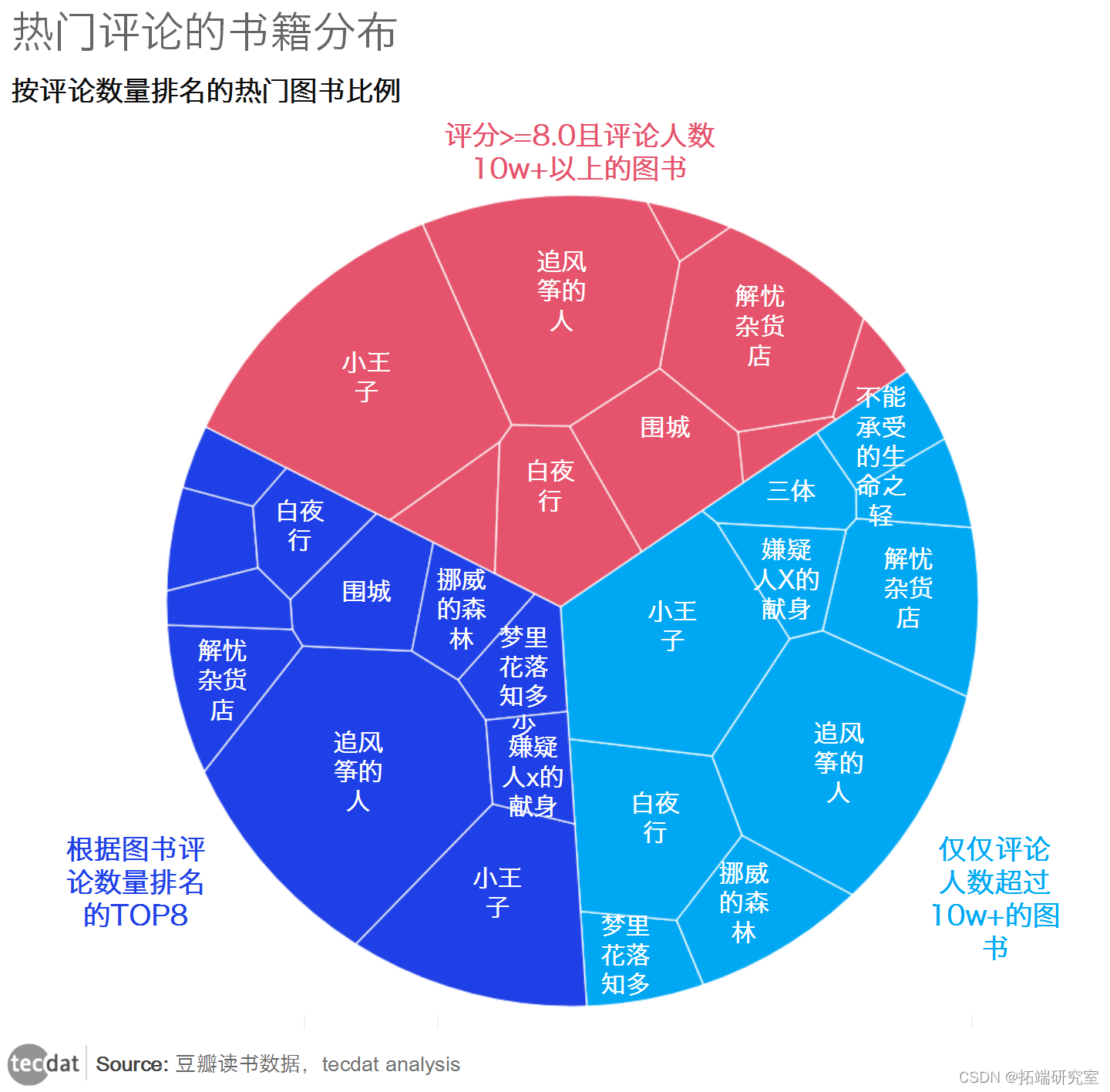
由此可以得出结论,数据分析算法应该是综合多种数据得到的权重模型,所以评论量大或者评分高的书不一定值得一读,综合考虑得到的结果可以 被认为是公平的。比如郭敬明的《梦里花落知多少》,路遥的《平凡的世界》。
书籍的价格一般都是在什么范围?
对于读书爱好者来说,这是一个比较关心的问题。
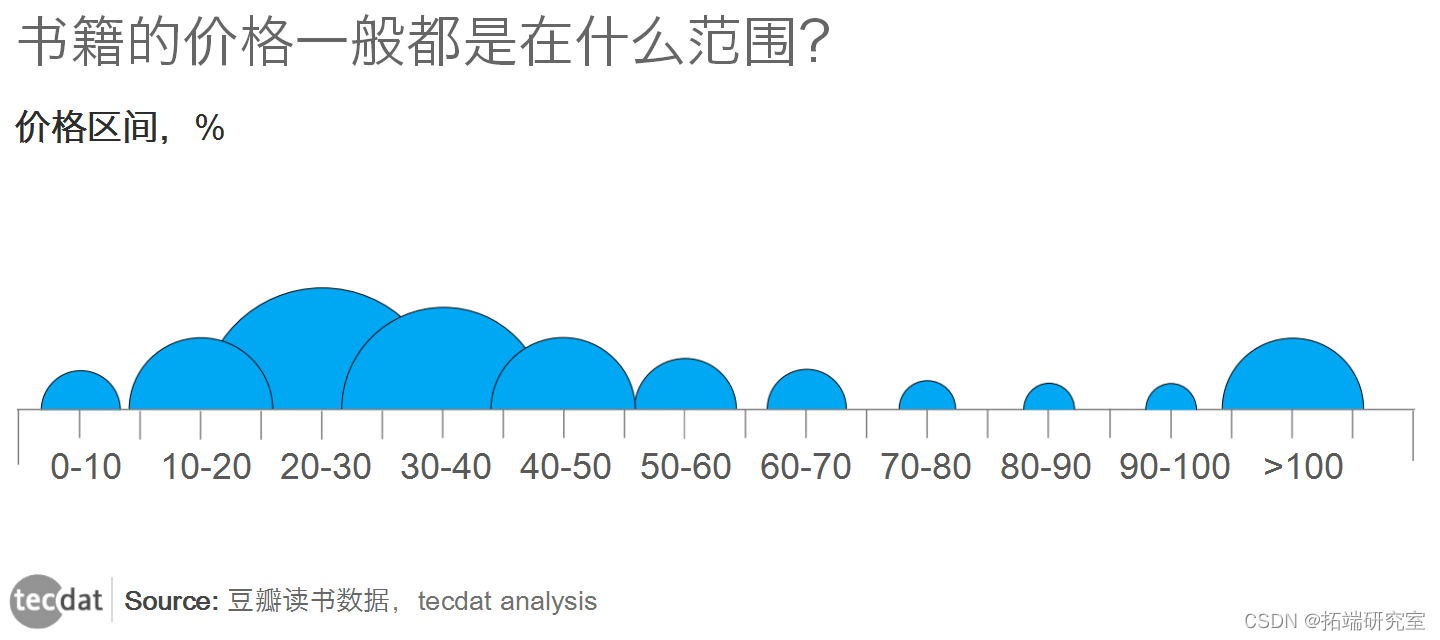
从上图我们可以发现,大部分书籍的价格在20-40之间,其他价格区间的书籍相对较少。 计算机专业书籍的价格在60-90之间,低于10元价格范围的书籍部分是电子书。 我们惊讶地发现有很多书的价格超过100元!
可以发现,这些百元以上的书籍,大部分都是史料书籍。 价格高的原因之一是这些书一般分为很多卷,研究意义重大,耗费大量人力。
热门书籍评价指标Apriori关联规则分析
接下来,我们研究3个关键评价指标:评分、评分数量和评论数量之间的关系。Apriori是常用的关联规则挖掘方法之一,可以找出3个评价指标之间的隐藏关联。
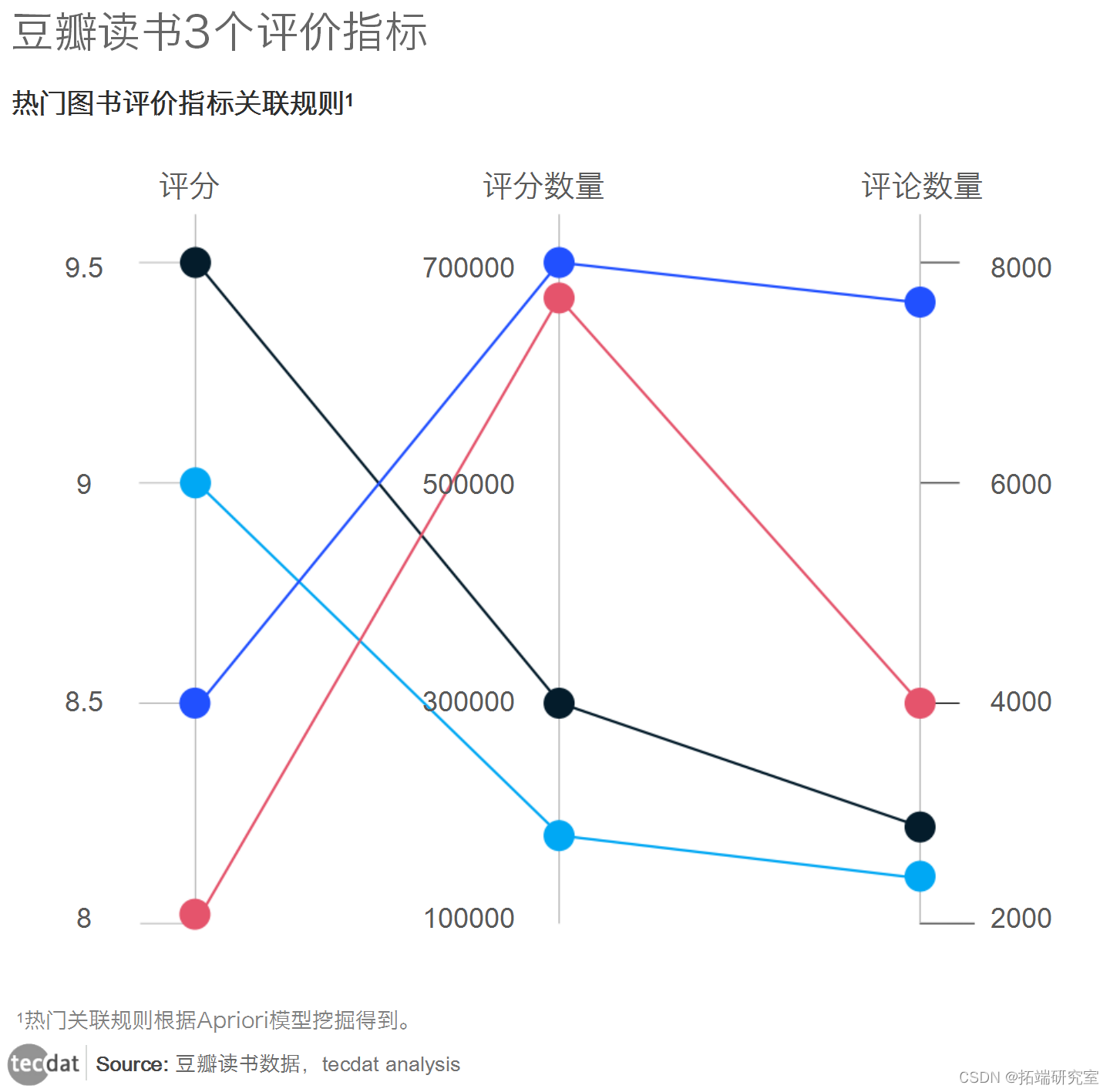
使用平行多维图来观察流行书籍评分、评分数量和评论数量的流行关联规则。 我们发现大部分书籍的评分在8.0-8.9之间,评分数量在20万-70万之间。

评论最多的书有追风筝人、解忧的杂货店、白夜行等,评分在8.1以上。
随时关注您喜欢的主题
基本上,具有更多评论的作品具有更高的评分。 但是,有些超高分(9分以上)的作品,评论数量却没有想象中的多!
本文章中的所有信息(包括但不限于分析、预测、建议、数据、图表等内容)仅供参考,__拓端数据(__tecdat__)__不因文章的全部或部分内容产生的或因本文章而引致的任何损失承担任何责任。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究
SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究 R语言SVM支持向量机文本挖掘分类研究手机评论数据词云可视化
R语言SVM支持向量机文本挖掘分类研究手机评论数据词云可视化 R语言、WEKA关联规则、决策树、聚类、回归分析工业企业创新情况影响因素数据
R语言、WEKA关联规则、决策树、聚类、回归分析工业企业创新情况影响因素数据 SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究
SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究


