建立逻辑回归,决策树,SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
尽管对于较高的阈值,SVM可以产生更好的ROC值,但逻辑回归通常更擅长区分不同类别。朴素贝叶斯的ROC曲线通常低于其他两个ROC曲线,这表明样本内性能比其他两个分类器方法差。
加载样本数据。
通过使用与versicolor和virginica物种相对应的度量来定义二元分类问题。
load fisheriris可下载资源
pred = meas(51:end,1:2);定义二进制响应变量。
一、决策树
定下一个最初的质点,从该点出发、分叉。(由于最初质点有可能落在边界值上,此时有可能会出现过拟合的问题。
二、SVM
svm是除深度学习在深度学习出现之前最好的分类算法了。它的特征如下:
(1)它既可应用于线性(回归问题)分类,也可应用于非线性分类;
(2)通过调节核函数参数的设置,可将数据集映射到多维平面上,对其细粒度化,从而使它的特征从二维变成多维,将在二维上线性不可分的问题转化为在多维上线性可分的问题,最后再寻找一个最优切割平面(相当于在决策数基础上再寻找一个最优解),因此svm的分类效果是优于大多数的机器学习分类方法的。
(3)通过其它参数的设置,svm还可以防止过拟合的问题。
三、随机森林
为了防止过拟合的问题,随机森林相当于多颗决策树。
四、knn最近邻
由于knn在每次寻找下一个离它最近的点时,都要将余下所有的点遍历一遍,因此其算法代价十分高。
五、朴素贝叶斯
要推事件A发生的概率下B发生的概率(其中事件A、B均可分解成多个事件),就可以通过求事件B发生的概率下事件A发生的概率,再通过贝叶斯定理计算即可算出结果。
六、逻辑回归
(离散型变量,二分类问题,只有两个值0和1)
resp = (1:100)'>50; % Versicolor = 0, virginica = 1拟合逻辑回归模型。
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
mdl = fitglm(pred,resp,'Distribution','binomial','Link','logit');计算ROC曲线。使用逻辑回归模型中的概率估计值作为得分。
perfcurve 将阈值存储在数组中。
显示曲线下的面积。
AUC
AUC = 0.7918曲线下的面积为0.7918。最大AUC为1,对应于理想分类器。较大的AUC值表示更好的分类器性能。
绘制ROC曲线
plot(X,Y)
xlabel('False positive rate')
ylabel('True positive rate')
title('ROC for Classification by Logistic Regression')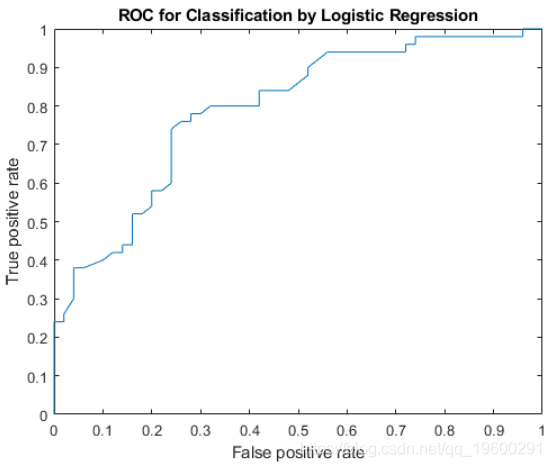
使用ROC曲线比较分类方法
加载样本数据
load ionosphereX 是351×34预测变量的矩阵。 Y 是类别标签的字符数组: 'b' 不良雷达回波和 'g' 良好雷达回波。
重新格式化因变量以适合逻辑回归。
拟合一个逻辑回归模型来估计雷达返回的后验概率是一个不好的概率。
mdl = fitglm(pred,resp,'Distribution','binomial','Link','logit');
score_log = mdl.Fitted.Probability; % Probability estimates使用得分的概率计算标准ROC曲线。
在相同的样本数据上训练SVM分类器标准化数据。
mdlSVM = fitcsvm(pred,resp,'Standardize',true);计算后验概率。
第二列 score_svm 包含不良雷达收益的后验概率。
使用SVM模型的分数计算标准ROC曲线。
在同一样本数据上拟合朴素贝叶斯分类器。
计算后验概率(分数)
[~,score_nb] = resubPredict(mdlNB);使用朴素贝叶斯分类的分数计算标准ROC曲线。
将ROC曲线绘制在同一张图上。
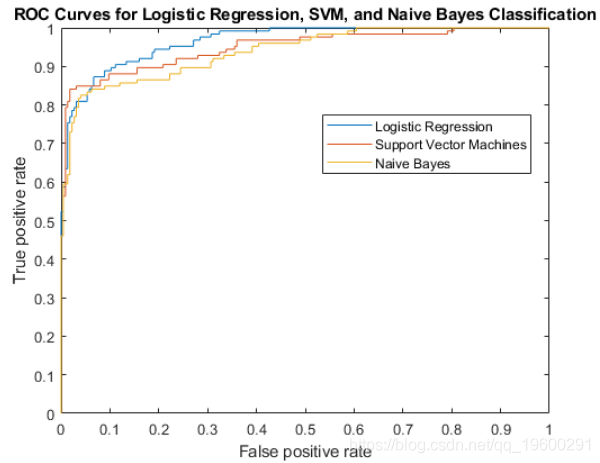
尽管对于较高的阈值,SVM可以产生更好的ROC值,但逻辑回归通常更擅长区分不良雷达收益与良好雷达。朴素贝叶斯的ROC曲线通常低于其他两个ROC曲线,这表明样本内性能比其他两个分类器方法差。
比较所有三个分类器的曲线下面积。
AUClog
AUClog = 0.9659
AUCsvm
AUCsvm = 0.9489
AUCnb
AUCnb = 0.9393Logistic回归的AUC度量最高,而朴素的贝叶斯则最低。该结果表明,逻辑回归对此样本数据具有更好的样本内平均性能。
确定自定义核功能的参数值
本示例说明如何使用ROC曲线为分类器中的自定义内核函数确定更好的参数值。
在单位圆内生成随机的一组点。
定义预测变量。将第一象限和第三象限中的点标记为属于正类别,而将第二象限和第二象限中的点标记为负类。
pred = [X1; X2];
resp = ones(4*n,1);
resp(2*n + 1:end) = -1; % Labels创建函数mysigmoid.m ,该函数 接受要素空间中的两个矩阵作为输入,并使用S形内核将其转换为Gram矩阵。
使用Sigmoid内核函数训练SVM分类器。使用标准化数据。
设置 gamma = 0.5 ,使用调整后的S形核训练SVM分类器。
SVMModel2 = fitPosterior(SVMModel2);
[~,scores2] = resubPredict(SVMModel2);计算两个模型的ROC曲线和曲线下面积(AUC)。
绘制ROC曲线。
plot(x1,y1)
hold on
plot(x2,y2)
hold off
title('ROC for classification by SVM');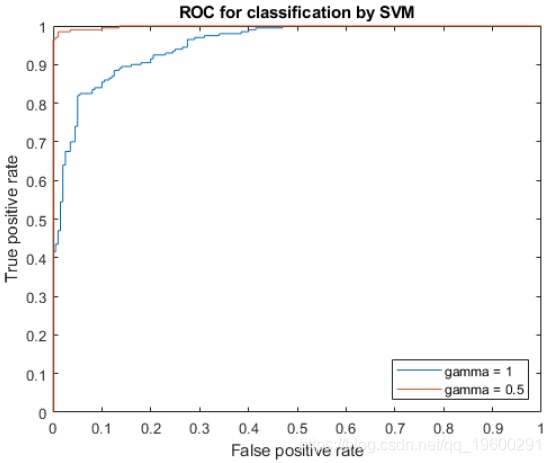
将gamma参数设置为0.5的内核函数可提供更好的样本内结果。
比较AUC度量。
auc1
auc2
auc1 =
0.9518
auc2 =
0.9985伽玛设置为0.5时曲线下的面积大于伽玛设置为1时曲线下的面积。这也证实了伽玛参数值为0.5会产生更好的结果。为了直观比较这两个伽玛参数值的分类性能。
绘制分类树的ROC曲线
加载样本数据。
load fisheriris列向量 species由三种不同物种的鸢尾花组成。双矩阵 meas 包含对花朵的四种测量类型:萼片长度,萼片宽度,花瓣长度和花瓣宽度。所有度量单位均为厘米。
使用萼片的长度和宽度作为预测变量训练分类树。
根据树预测物种的分类标签和分数 。
[~,score] = resubPredict(Model);分数是观察值(数据矩阵中的一行)所属类别的后验概率。列 score 对应于所指定的类 'ClassNames'。
由于这是一个多类问题,因此不能仅将其 score(:,2) 作为输入。这样做将无法提供 perfcurve 有关两个阴性类别(setosa和virginica)分数的足够信息。此问题与二元分类问题不同,在二元分类问题中,知道一个类别的分数就足以确定另一个类别的分数。因此,必须提供 perfcurve 将两个否定类的得分纳入考虑范围的函数。一种函数是score(:,2)-max(score(:,1),score(:,3))。
X,默认为假阳性率, Y,默认为真阳性率(召回率或敏感性)。正类标签为 versicolor。由于未定义否定类别,因此 perfcurve 假设不属于肯定类别的观测值属于一个类别。该函数将其接受为否定类。
suby = 12×2
0 0
0.1800 0.1800
0.4800 0.4800
0.5800 0.5800
0.6200 0.6200
0.8000 0.8000
0.8800 0.8800
0.9200 0.9200
0.9600 0.9600
0.9800 0.9800
⋮
subnames = 1x2 cell
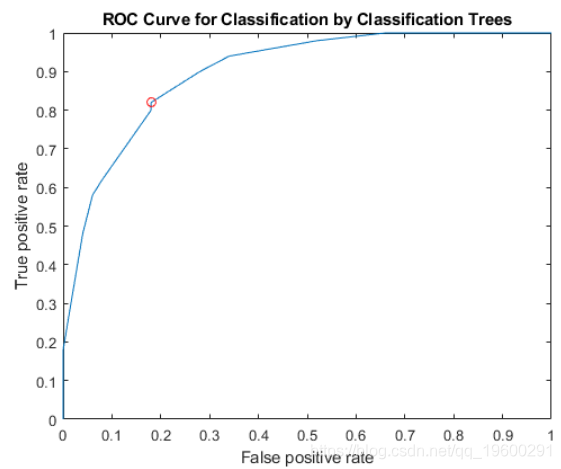
{'setosa'} {'virginica'}在ROC曲线上绘制ROC曲线和最佳工作点。
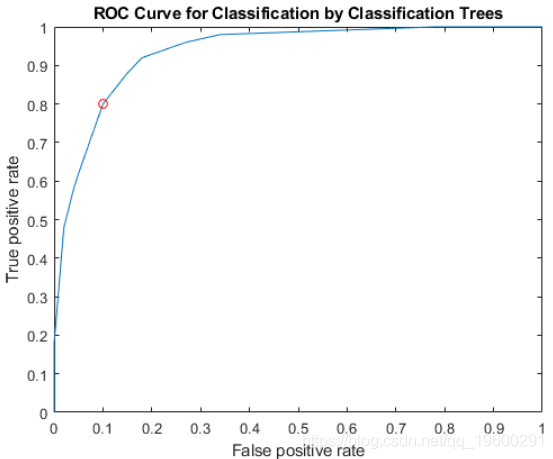
找到与最佳工作点相对应的阈值。
T((X==OPTROCPT(1))&(Y==OPTROCPT(2)))
ans = 0.2857指定 virginica 为否定类,并计算和绘制ROC曲线 versicolor。
同样,必须提供 perfcurve 将否定类分数纳入考量的函数。要使用的函数的一个示例是score(:,2)-score(:,3)。
计算ROC曲线的逐点置信区间
加载样本数据。
load fisheriris仅将前两个变量用作预测变量,来定义二元问题。
pred = meas(51:end,1:2);定义二进制因变量。
resp = (1:100)'>50; % Versicolor = 0, virginica = 1拟合逻辑回归模型。
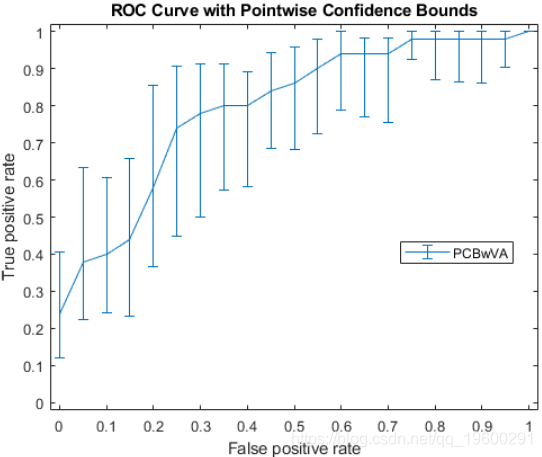
通过垂直平均(VA)和使用bootstrap进行采样,计算真实正率(TPR)上的逐点置信区间。
'NBoot',1000 将引导样本的数量设置为1000。 'XVals','All' 提示 perfcurve 返回 X, Y和 T 所有分数的Y 值,并X 使用垂直平均将所有值的值(真阳性率) 平均 (假阳性率)。 默认情况下将使用阈值平均来计算置信范围。
绘制逐点置信区间。
errorbar(X,Y(:,1),Y(:,1)-Y(:,2),Y(:,3)-Y(:,1));
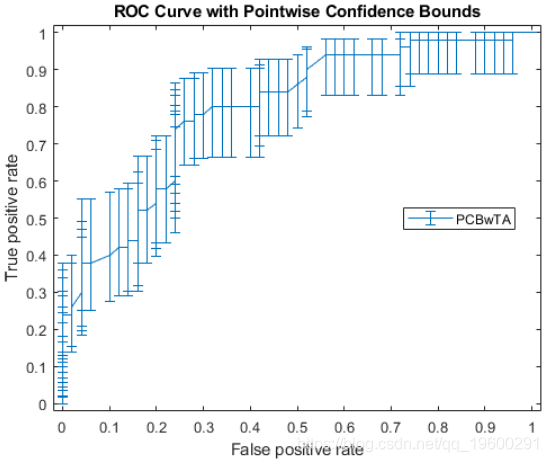
不一定总是可以控制误报率(FPR,X 此示例中的 值)。因此,可能希望通过阈值平均来计算真实正利率(TPR)的逐点置信区间。
绘制置信区间。
figure()
errorbar(X1(:,1),Y1(:,1),Y1(:,1)-Y1(:,2),Y1(:,3)-Y1(:,1));
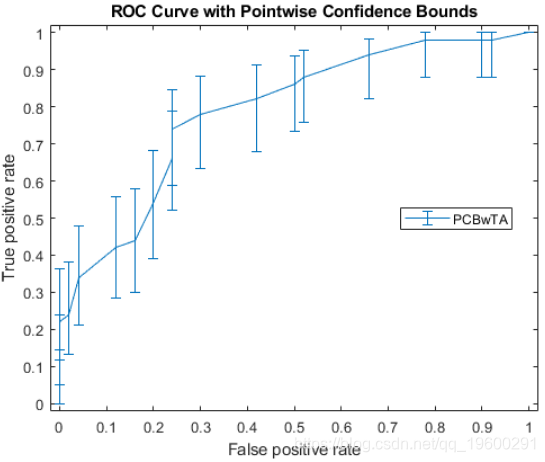
指定阈值计算ROC曲线。然后绘制曲线。
figure()
errorbar(X1(:,1),Y1(:,1),Y1(:,1)-Y1(:,2),Y1(:,3)-Y1(:,1));
 R语言Stan贝叶斯回归置信区间后验分布可视化模型检验
R语言Stan贝叶斯回归置信区间后验分布可视化模型检验 R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码
R语言层次聚类、多维缩放MDS分类RNA测序(RNA-seq)乳腺发育基因数据可视化|附数据代码 R语言分类回归分析考研热现象分析与考研意愿价值变现
R语言分类回归分析考研热现象分析与考研意愿价值变现 R语言逻辑回归logistic模型ROC曲线可视化分析2例:麻醉剂用量影响、汽车购买行为
R语言逻辑回归logistic模型ROC曲线可视化分析2例:麻醉剂用量影响、汽车购买行为


