在这篇文章中,我将展示如何使用R语言来进行支持向量回归SVR。
最近我们被客户要求撰写关于支持向量机回归的研究报告,包括一些图形和统计输出。我们将首先做一个简单的线性回归,然后转向支持向量回归,这样你就可以看到两者在相同数据下的表现。
一个简单的数据集
首先,我们将使用这个简单的数据集。
对于很多算法工程师来说, 超参数调优是件非常头疼的事。除了根据经验设定所谓的“合 理值”之外, 一般很难找到合理的方法去寻找超参数的最优取值。 而与此同时,超参数对于模型效果的影响又至关重要。 高没有一些可行的办法去进行超参数的调优呢?
为了进行超参数调优,我们一般会采用网格搜索、 随机搜索、贝叶斯优化等算法。 在具体介绍算法之前,需要明确超参数搜索算法一般包括哪几个要素。一是目标函数,即算法需要最大化/最小化的目标;二是搜索范围,一般通过上限和下限来确定 ; 三是算法的其他参数, 如搜索步长。
网格搜索
网格搜索可能是最简单、应用最广泛的超参数搜索算法, 色通过查找搜索范围内的所有的点来确定最优值。 如果采用较大的搜索范围以及较小的步长,网恪搜索高很大概率找到全局最优值。 然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候。因此, 在实际应用中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置;然后会逐渐缩小搜索范围和步长,来寻找更精确的最优值。 这种操作方案可以降低所需的时间和计算量, 但由于目标函数一般是非凸的, 所以很可能会错过全局最优值。
随机搜索
随机搜索的思想与网格搜索比较相似 , 只是不再测试上界和下界之间的所有值,而是在搜索范围中随机选取样本点。 它的理论依据是,如果样本点集足够大,那么通过随机采样也能大概率地找到全局最优值, 或其近似值。随机搜索一般会比网格搜索要快一些,但是和网格搜索的快速版一样,它的结果也是没法保证的。
贝叶斯优化算法
贝叶斯优化算法在寻找最优值参数时,采用了与网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新点时,会忽略前一 个点的信息,而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数。具体来说,它学习目标函数形状的方法是,首先根据先验分布,假设 一个搜集函数,然后,每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布;最后,算法测试由后验分布给出的全局最值最可能出现的位置的点。对于贝叶斯优化算法,有一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之 间找到一个平衡点,“探索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。
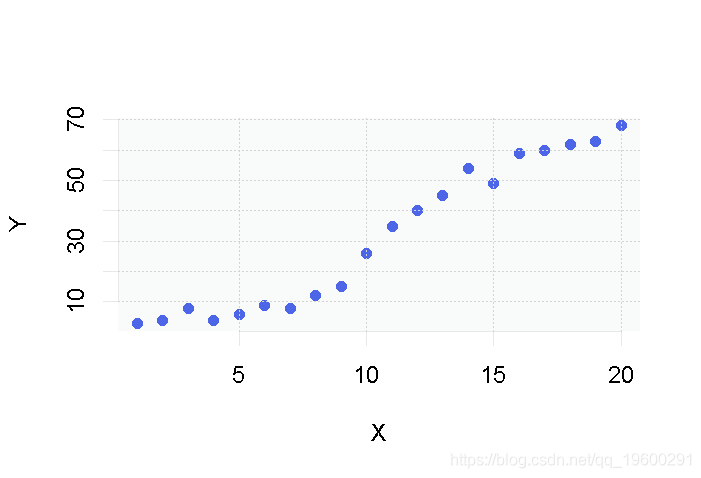
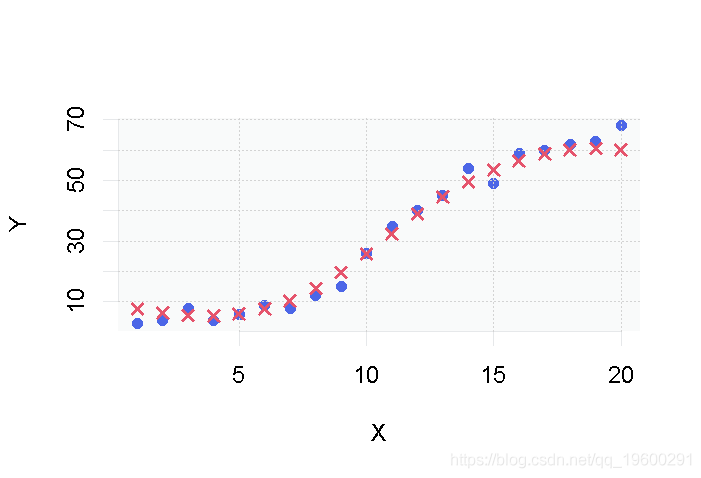
正如你所看到的,在我们的两个变量X和Y之间似乎存在某种关系,看起来我们可以拟合出一条在每个点附近通过的直线。
我们用R语言来做吧!
第1步:在R中进行简单的线性回归
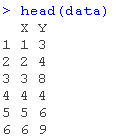
下面是CSV格式的相同数据,我把它保存在regression.csv文件中。
我们现在可以用R来显示数据并拟合直线。
# 从csv文件中加载数据 dataDirectory <- "D:/" #把你自己的文件夹放在这里 data <- read.csv(paste(dataDirectory, 'data.csv', sep=""), header = TRUE) # 绘制数据 plot(data, pch=16) # 创建一个线性回归模型 model <- lm(Y ~ X, data) # 添加拟合线 abline(model)
上面的代码显示以下图表:

第2步:我们的回归效果怎么样?
为了能够比较线性回归和支持向量回归,我们首先需要一种方法来衡量它的效果。
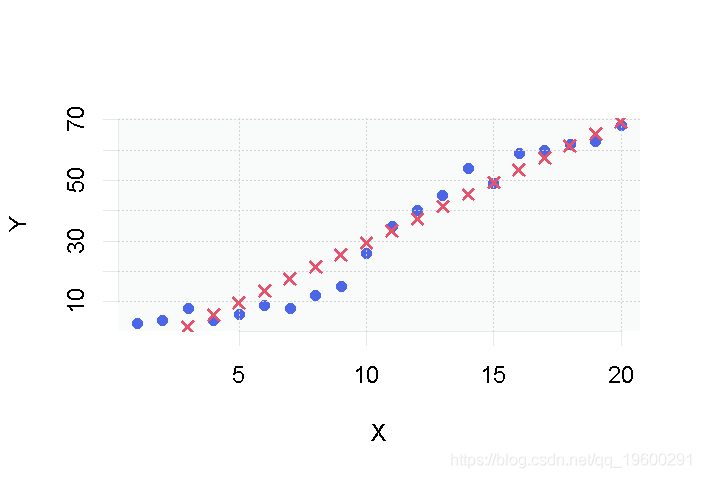
为了做到这一点,我们改变一下代码,使模型做出每一个预测可视化
# 对每个X做一个预测 pred <- predict(model, data) # 显示预测结果 points(X, pred)

产生了以下图表。
随时关注您喜欢的主题
对于每个数据点Xi,模型都会做出预测Y^i,在图上显示为一个红色的十字。与之前的图表唯一不同的是,这些点没有相互连接。
为了衡量我们的模型效果,我们计算它的误差有多大。
我们可以将每个Yi值与相关的预测值Y^i进行比较,看看它们之间有多大的差异。
请注意,表达式Y^i-Yi是误差,如果我们做出一个完美的预测,Y^i将等于Yi,误差为零。
如果我们对每个数据点都这样做,并将误差相加,我们将得到误差之和,如果我们取平均值,我们将得到平均平方误差(MSE)。
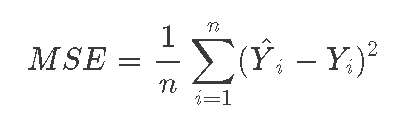
在机器学习中,衡量误差的一个常见方法是使用均方根误差(RMSE),所以我们将使用它来代替。
为了计算RMSE,我们取其平方根,我们得到RMSE
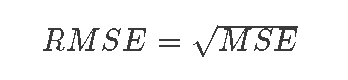
使用R,我们可以得到以下代码来计算RMSE
rmse <- function(error)
{
sqrt(mean(error^2))
}

我们现在知道,我们的线性回归模型的RMSE是5.70。让我们尝试用SVR来改善它吧!
第3步:支持向量回归
用R创建一个SVR模型。
下面是用支持向量回归进行预测的代码。
model <- svm(Y ~ X , data)
如你所见,它看起来很像线性回归的代码。请注意,我们调用了svm函数(而不是svr!),这是因为这个函数也可以用来用支持向量机进行分类。如果该函数检测到数据是分类的(如果变量是R中的一个因子),它将自动选择SVM。
这一次的预测结果更接近于真实的数值 ! 让我们计算一下支持向量回归模型的RMSE。
代码画出了下面的图。
# 这次svrModel$residuals与data$Y - predictedY不一样。 #所以我们这样计算误差 svrPredictionRMSE

正如预期的那样,RMSE更好了,现在是3.15,而之前是5.70。
但我们能做得更好吗?
第四步:调整你的支持向量回归模型
为了提高支持向量回归的性能,我们将需要为模型选择最佳参数。
在我们之前的例子中,我们进行了ε-回归,我们没有为ε(ϵ)设置任何值,但它的默认值是0.1。 还有一个成本参数,我们可以改变它以避免过度拟合。
选择这些参数的过程被称为超参数优化,或模型选择。
标准的方法是进行网格搜索。这意味着我们将为ϵ和成本的不同组合训练大量的模型,并选择最好的一个。
# 进行网格搜索 tuneResultranges = list(epsilon = seq(0,1,0.1), cost = 2^(2:9)) # 绘制调参图 plot(Result)
在上面的代码中有两个重要的点。
- 我们使用tune方法训练模型,ϵ=0,0.1,0.2,…,1和cost=22,23,24,…,29这意味着它将训练88个模型(这可能需要很长一段时间
- tuneResult返回MSE,别忘了在与我们之前的模型进行比较之前将其转换为RMSE。
最后一行绘制了网格搜索的结果。
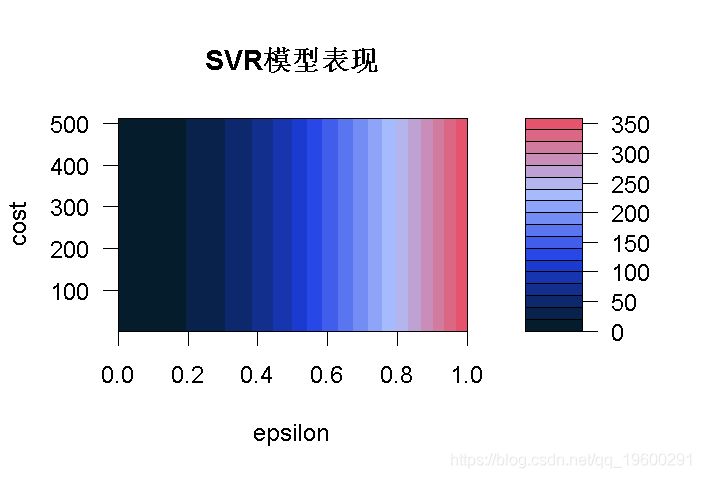
在这张图上,我们可以看到,区域颜色越深,我们的模型就越好(因为RMSE在深色区域更接近于零)。
这意味着我们可以在更窄的范围内尝试另一个网格搜索,我们将尝试在0和0.2之间的ϵ值。目前看来,成本值并没有产生影响,所以我们将保持原样,看看是否有变化。
rangelist(epsilo = seq(0,0.2,0.01), cost = 2^(2:9))
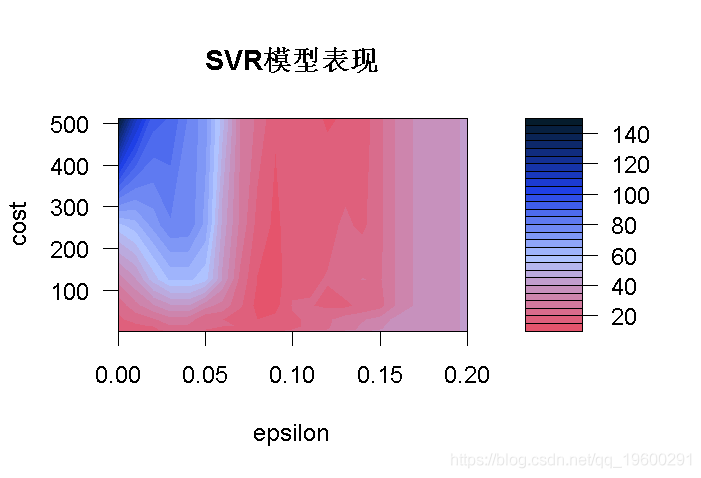
我们用这一小段代码训练了不同的168模型。
当我们放大暗区域时,我们可以看到有几个较暗的斑块。
从图中可以看出,C在200到300之间,ϵ在0.08到0.09之间的模型误差较小。
 希望对我们来说,我们不必用眼睛去选择最好的模型,R让我们非常容易地得到它,并用来进行预测。
希望对我们来说,我们不必用眼睛去选择最好的模型,R让我们非常容易地得到它,并用来进行预测。
# 这个值在你的电脑上可能是不同的 # 因为调参方法会随机调整数据 tunedModelRMSE <- rmse(error)
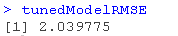
我们再次提高了支持向量回归模型的RMSE !
我们可以把我们的两个模型都可视化。在下图中,第一个SVR模型是红色的,而调整后的SVR模型是蓝色的。

我希望你喜欢这个关于用R支持向量回归的介绍。你可以查看原文得到本教程的源代码。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据
【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据 R语言Stan贝叶斯回归置信区间后验分布可视化模型检验
R语言Stan贝叶斯回归置信区间后验分布可视化模型检验 R语言分类回归分析考研热现象分析与考研意愿价值变现
R语言分类回归分析考研热现象分析与考研意愿价值变现


