最近我们被客户要求撰写关于预测一辆汽车的燃油经济性的研究报告。
这个例子展示了如何用Matlab实现贝叶斯优化,使用分位数误差调整回归树随机森林的超参数。如果你打算使用模型来预测条件量值而不是条件平均值,那么使用分位数误差而不是平均平方误差来调整模型是合适的。
加载和预处理数据
加载数据集。考虑建立一个模型,预测一辆汽车的燃油经济性中位数,给定它的加速度、汽缸数、发动机排量、马力、制造商、型号和重量。
随机森林
随机森林(RF)使用随机数据样本独立训练每棵树,这种随机性有助于使得模型比单个决策树更健壮。由于这个原因,随机森林算法在训练数据上不太可能出现过拟合现象。
随机森林应用示例
随机森林的差异性已被用于各种应用,例如基于组织标记数据找到患者群$[1]$。 在以下两种情况下,随机森林模型对于这种应用非常实用:
-
目标是为具有强相关特征的高维问题提供高预测精度;
-
数据集非常嘈杂,并且包含许多缺失值,例如某些属性是半连续的;
优点
随机森林中的模型参数调整比XGBoost更容易。在随机森林中,只有两个主要参数:每个节点要选择的特征数量和决策树的数量。此外,随机森林比XGB更难出现过拟合现象。
缺点
随机森林算法的主要限制是大量的树使得算法对实时预测的速度变得很慢。对于包含不同级别数的分类变量的数据,随机森林偏向于具有更多级别的属性。
贝叶斯优化
贝叶斯优化是一种优化函数的技术,其评估成本很高$[2]$。它为目标函数构建后验分布,并使用高斯过程回归计算该分布中的不确定性,然后使用采集函数(acquisition function )来决定采样的位置。贝叶斯优化专注于解决问题:
$max(_x∈AF(X))$
超参数的维度($x∈R_d$)一般设置为$d<20$。
通常设置A超矩形($x∈R^d$:$a_i≤x_i≤b_i$)。目标函数是连续的,这是使用高斯过程回归建模所需的。它也缺乏像凹函数或线性函数这类函数,这使得利用这类函数来提高效率的技术徒劳无功。贝叶斯优化由两个主要组成部分组成:用于对目标函数建模的贝叶斯统计模型和用于决定下一步采样的采集函数。
在根据初始空间初始化实验设计的评估目标后,迭代使用这些目标分配N个评估的预算的剩余部分,如下所示:
-
观察初始点;
-
当$n\leqN$ 时,使用所有可用数据更新后验概率分布,并让$x_n$作为采集函数的最大值时的取值。继续观察$y_n=f(x_n)$ ,增大$n$, 直到循环结束;
-
返回一个解决方案:最大的评估点;
通过上述可以总结到,贝叶斯优化是为黑盒无导数全局优化而设计的,在机器学习中调整超参数中是非常受欢迎的。
考虑将汽缸数、制造商和型号_年份作为分类变量。
Cylinders = categorical(Cylinders);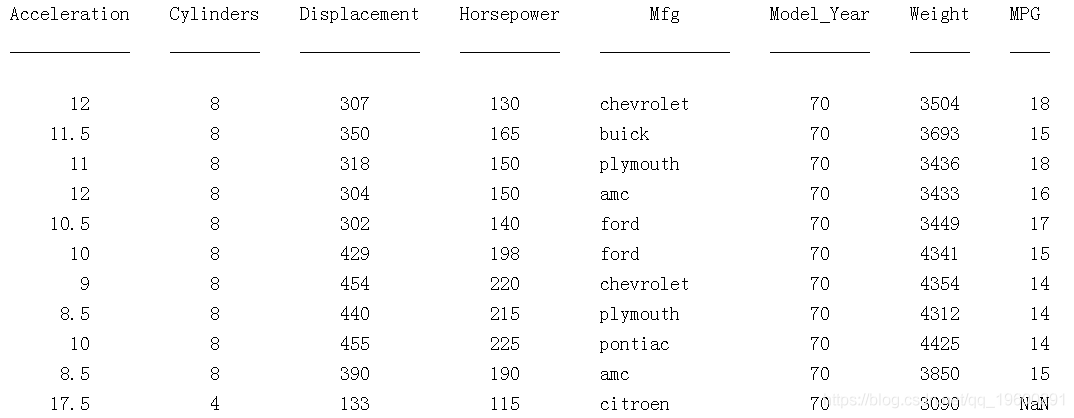
指定调整参数
考虑调整:
- 森林中的树木的复杂性(深度)。深的树倾向于过度拟合,但浅的树倾向于欠拟合。因此,规定每片叶子的最小观测值数量最多为20。
- 生长树时,在每个节点上要采样的预测器数量。指定从1到所有预测的采样。
实现贝叶斯优化的函数,要求你将这些参数作为优化变量对象传递。
optim('minLS',\[1,maxMinLS\],'Type');超参数随机森林是一个2乘1的优化变量对象数组
贝叶斯优化倾向于选择包含很多树的随机森林,因为具有更多学习者的合集更准确。如果可用的计算资源是一个考虑因素,并且你倾向于树数较少的合集,那么可以考虑将树的数量与其他参数分开调整,或者对含有许多学习者的模型进行惩罚。
定义目标函数
为贝叶斯优化算法定义一个要优化的目标函数。该函数应:
- 接受要调整的参数作为输入。
- 使用TreeBagger训练一个随机森林。在TreeBagger调用中,指定要调整的参数并指定返回袋外指数。
- 根据中位数估计袋外分位数误差。
- 返回袋外数据的分位数误差。
function Err = RF(X)
%训练随机森林并估计袋外的分位数误差
% 使用X中的预测数据和params中的参数说明,训练一个由300棵回归树组成的随机森林,然后根据中位数返回袋外误差。X是一个表,params是一个数组,对应于每个节点的最小叶子大小和预测器数量来采样。
randomForest = Tree(300,X);
Error(randomForest);使用贝叶斯优化实现目标最小化
使用贝叶斯优化法,找到在树的复杂性和每个节点的预测因子数量方面达到最小的、惩罚的、袋外分位数误差的模型。
bayes(@(params)oobErrRF,parameters,...);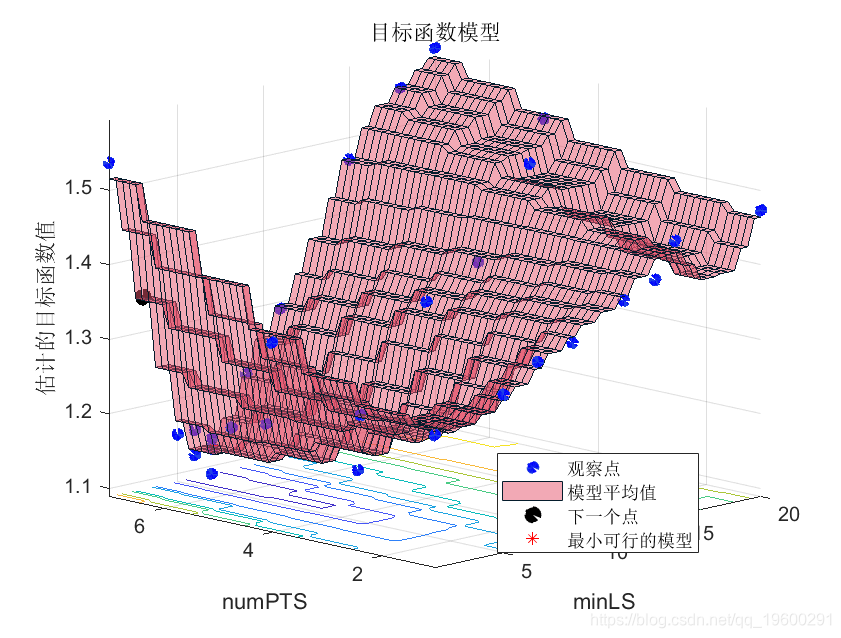
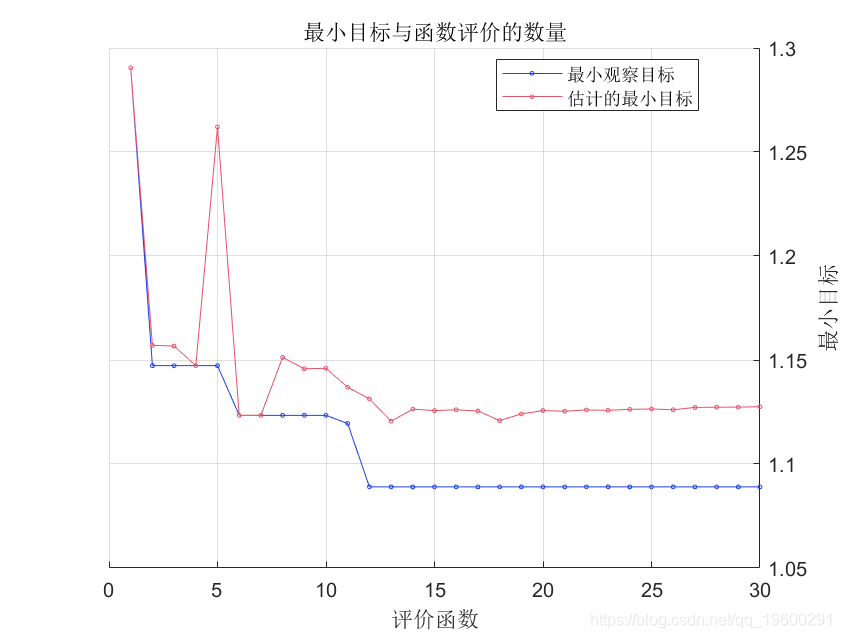
结果是一个BayesianOptimization对象,其中包括目标函数的最小值和优化的超参数值。

显示观察到的目标函数的最小值和优化的超参数值。
MinObjective
bestHyperpara
随时关注您喜欢的主题
使用优化的超参数训练模型
使用整个数据集和优化的超参数值训练一个随机森林。
Tree(300,X,'MPG','regression',...);Mdl是为中位数预测优化的TreeBagger对象。你可以通过将Mdl和新数据传递给quantilePredict来预测给定的预测数据的燃油经济性中值。
 【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据
【视频】R语言支持向量回归SVR预测水位实例讲解|附代码数据 R语言Stan贝叶斯回归置信区间后验分布可视化模型检验
R语言Stan贝叶斯回归置信区间后验分布可视化模型检验 【专题】中国纯电新能源汽车-市场发展和用车报告2024年报告合集PDF分享(附原数据表)
【专题】中国纯电新能源汽车-市场发展和用车报告2024年报告合集PDF分享(附原数据表) 数据分享|R语言Python机器学习预测4案例合集:众筹平台、机票折扣、糖尿病患者、员工满意度
数据分享|R语言Python机器学习预测4案例合集:众筹平台、机票折扣、糖尿病患者、员工满意度


